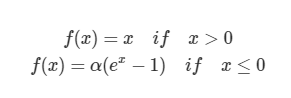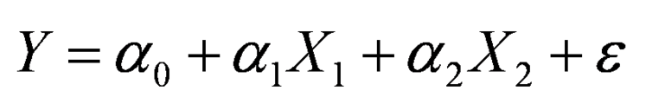|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
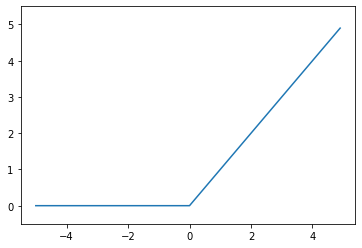
# 신경망을 이용하여 콘크리트 강도 예측하기
concrete <- read.csv('c:/data/concrete.csv')
# 예측하고자 하는 결과가 정규분포를 띄는지 확인한다.
# 만약 정규분포를 띈다면 예측 결과가 좋게 나올 수 있다는 것을 알 수 있다.
hist(concrete$strength)
# 결측치 확인
colSums(is.na(concrete))
# 정규화 함수
normalize <- function(x) {
return ( (x-min(x)) / (max(x) - min(x) ) )
}
# 데이터 정규화하기
concrete_norm <- as.data.frame(lapply(concrete,normalize))
# 0~1 사이로 데이터가 바꼈는지 확인
summary(concrete_norm$strength)
# 기존 데이터와 비교
summary(concrete$strength)
# train(75%) / test(27%)
nrow(concrete_norm) * 0.75 # 772.5
concrete_train <- concrete_norm[1:773, ]
concrete_test <- concrete_norm[774:1030, ]
# 신경망 패키지 설치
install.packages("neuralnet")
library(neuralnet)
# 모델 생성
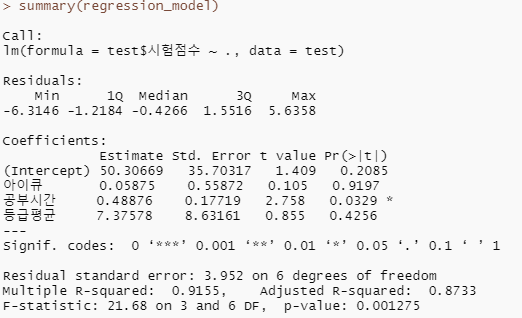
concrete_model <- neuralnet(formula=strength ~ cement + slag + ash +water +superplastic + coarseagg + fineagg + age,
data =concrete_train)
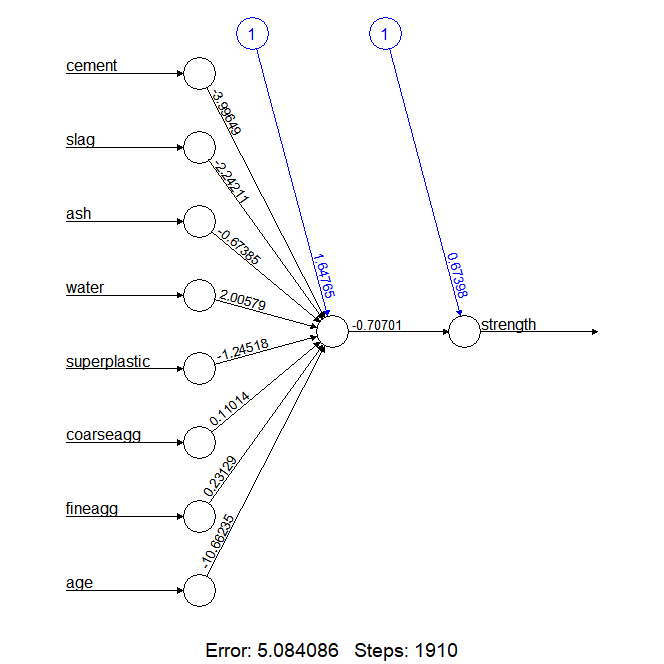
# 신경망 모델 시각화
plot(concrete_model)
# 예측
model_results <- compute(concrete_model, concrete_test[1:8])
predicted_strength <- model_results$net.result
# 상관관계 확인
cor(predicted_strength, concrete_test$strength) # 0.806285848
|
cs |
모델 성능 개선
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
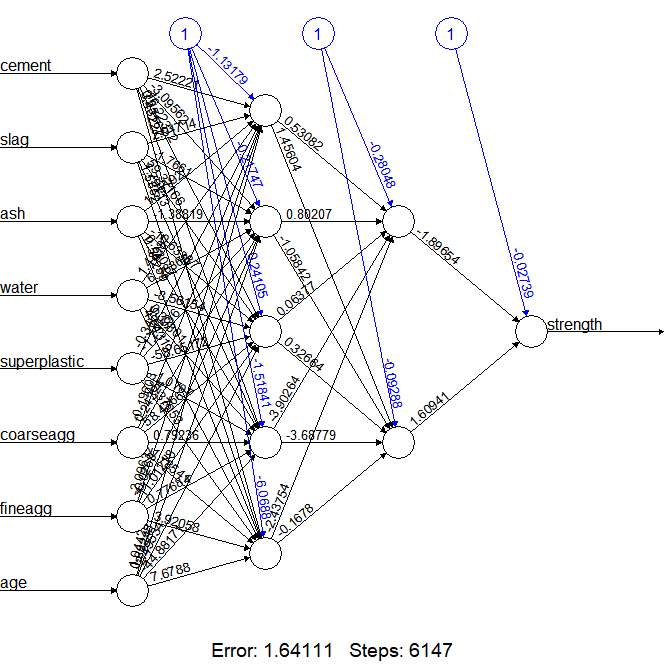
# 모델 성능 개선 은닉층(hidden) 생성
concrete_model2 <- neuralnet(formula=strength ~ cement + slag + ash +
water +superplastic + coarseagg + fineagg + age,
data =concrete_train , hidden=c(5,2))
# 은닉층을 설정해 생성한 신경망 모델 시각화
plot(concrete_model2)
# 예측
model_results <- compute(concrete_model2, concrete_test[1:8])
predicted_strength2 <- model_results$net.result
# 상관관계 확인
cor(predicted_strength2, concrete_test$strength)
|
cs |
'인공지능 > 실습예제' 카테고리의 다른 글
| (R) 연관규칙(Apriori) 이해하기 (0) | 2020.07.02 |
|---|---|
| (R) 신경망 활용하기 2 - 와인 분류 (0) | 2020.07.01 |
| (R) 다중회귀분석 이해하기 (0) | 2020.06.30 |
| (R) 회귀분석 활용하기 (0) | 2020.06.26 |
| (R) 규칙기반알고리즘 활용하기 - 버섯 분류 (0) | 2020.06.26 |