오억년만에 나타나서 처음 쓰는 글은 pd.read_csv할 때 utf-8, utf-16, 심지어는 cp949까지도 오류날 때 해결하는 방법이다.
[python] 파이썬 공공데이터 csv 파일 읽어오기_인코딩 에러 해결
회사에서 진행하는 데이터분석 아카데미 프로젝트 마감이 얼마 남지 않았다. 데이터 수집은 다했는데 전처리가 관건일듯.. 공공데이터 포털사이트에서 다운받은 cvs 파일을 pandas 모듈을 이용해
javagirl.tistory.com
위의 블로그가 엄청 큰 도움이 됐는데, 걍 결론적으로 엑셀 파일을 csv로 저장할 때 애초에 인코딩을 utf-8로 하는것이었다.
엑셀에서 엄청 긴 숫자를 입력하면 얘가 자동적으로 숫자로 인식해서 막 16e+06 이런식으로 지멋대로 숫자로 변환하는데 그게 싫어서 full 숫자로 저장하게 하려고 csv로 저장해서 python에서 불러오는 걸 하려고 했었다.
내가 현재 일하고 있는 회사에서는 이런식으로 숫자가 엄청 길게 기재되는 경우가 매우 빈번해서 이런 아주 간단한 부분을 확실히 알고 넘어가야 했다.
엑셀을 csv로 저장할 때 인코딩 오류로 열리지 않을 때는 애초에 엑셀에서 엑셀 메뉴 > 파일 > 다른이름으로 저장 > 파일형식 : csv utf8(쉼표로분리)로 저장 하면 된다.
'코딩 > Python' 카테고리의 다른 글
| tqdm 사용하기 (0) | 2020.12.02 |
|---|---|
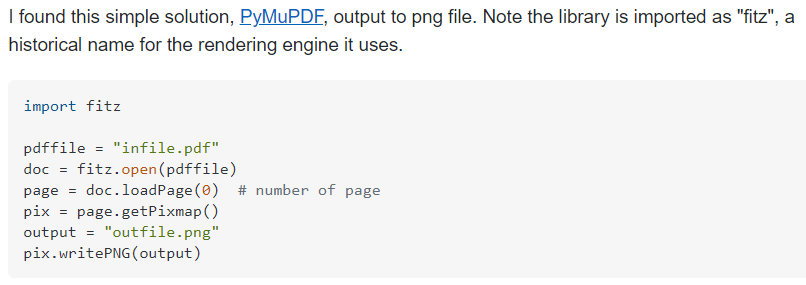
| PyMuPDF : pdf2image (0) | 2020.12.02 |
| 판다스 이해하기 - 시리즈에서 문자열 조작하기 (0) | 2020.07.20 |
| 판다스 이해하기 - 분할, 더미변수, 문자형 날짜형 변환 (0) | 2020.07.16 |
| 판다스 이해하기 - 조건문, concat, append, 그룹화, 함수적용, join (0) | 2020.07.16 |