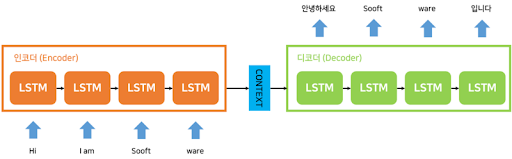
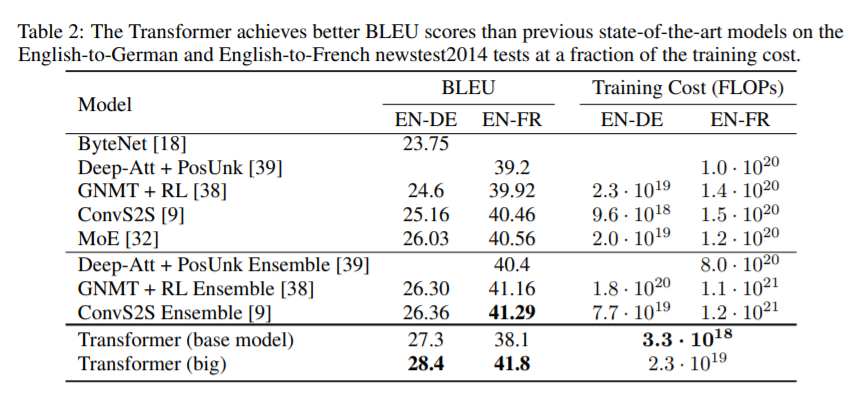
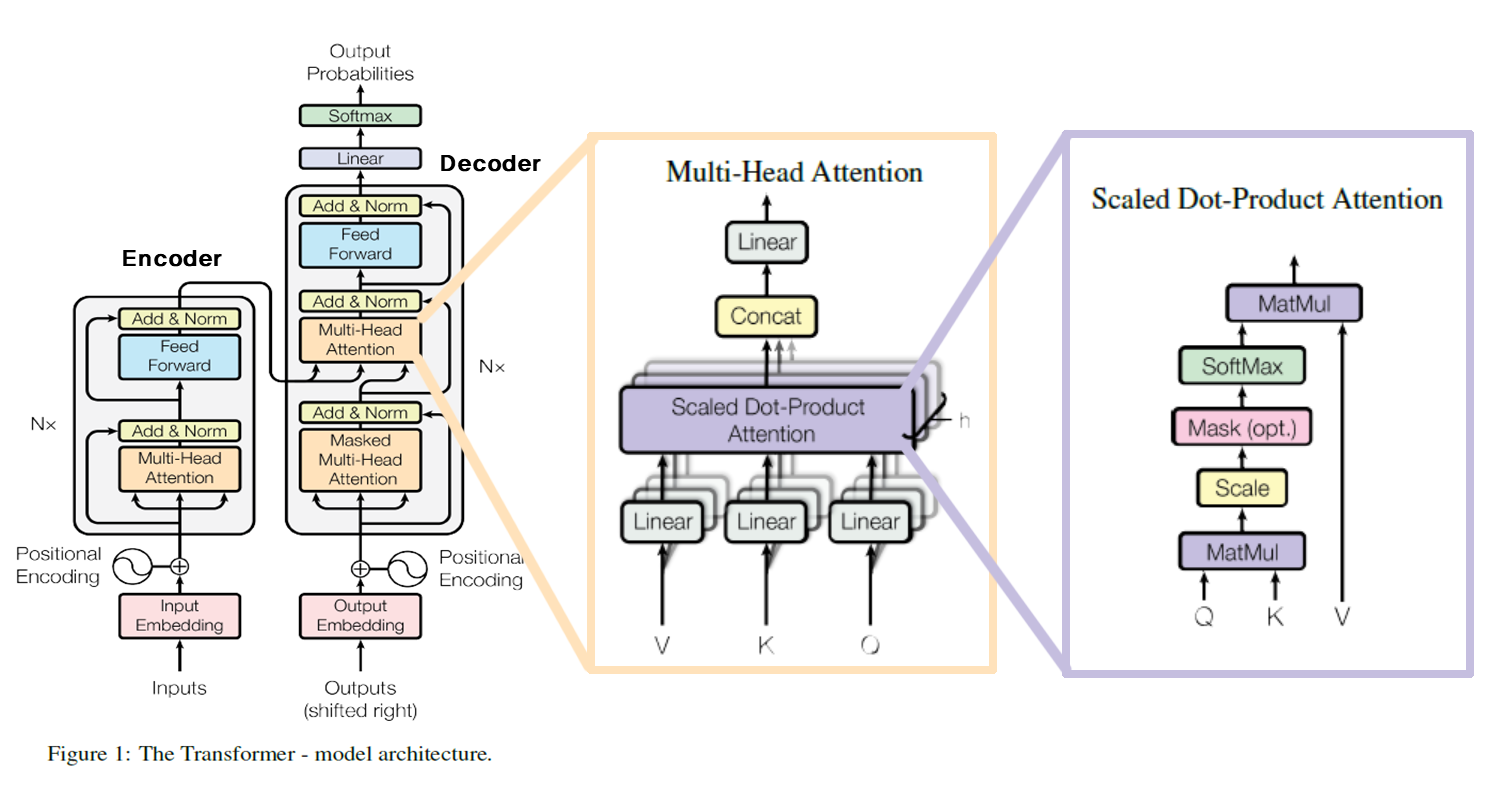
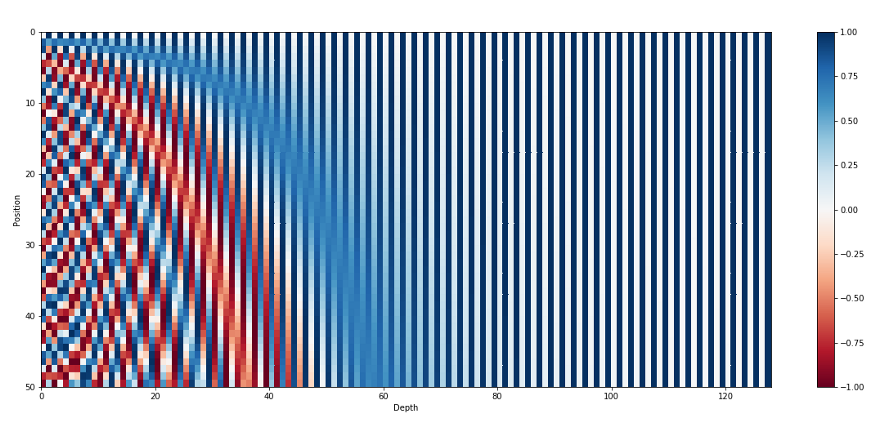
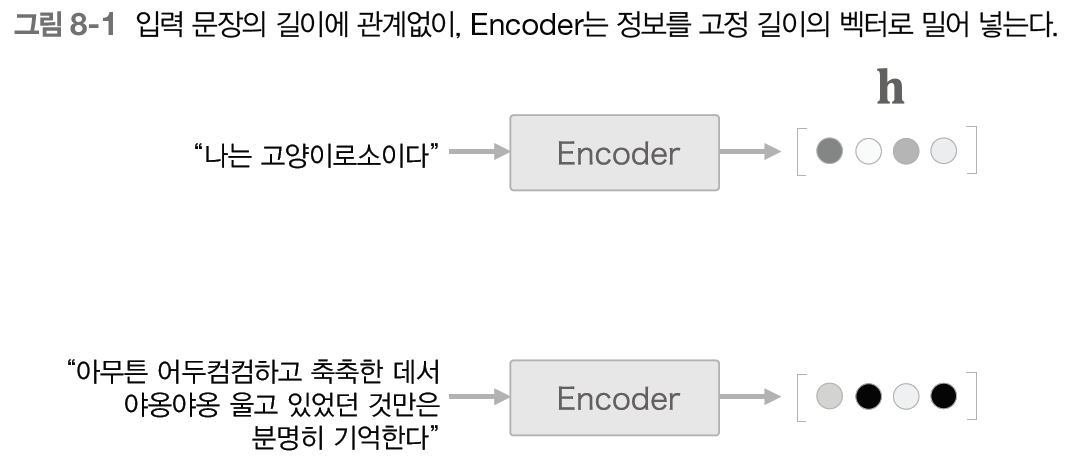
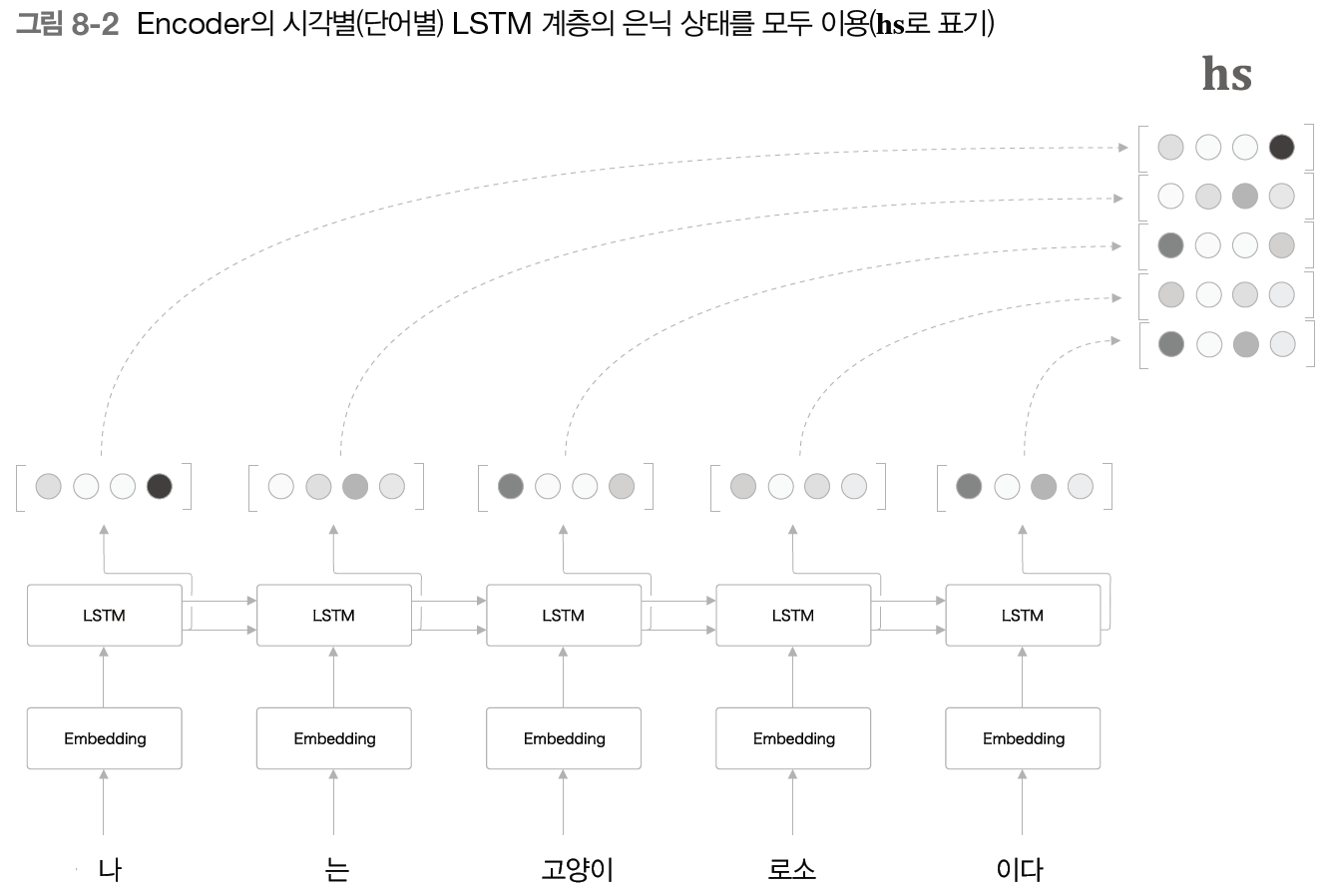
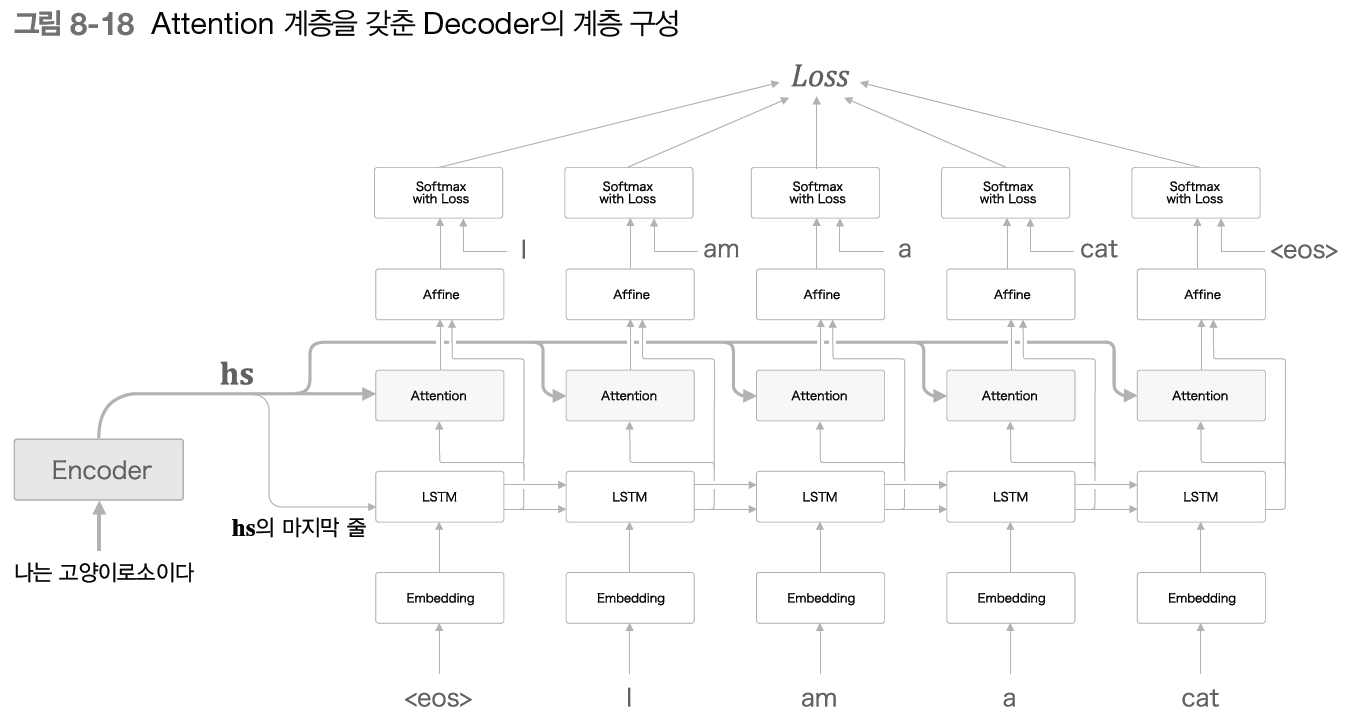
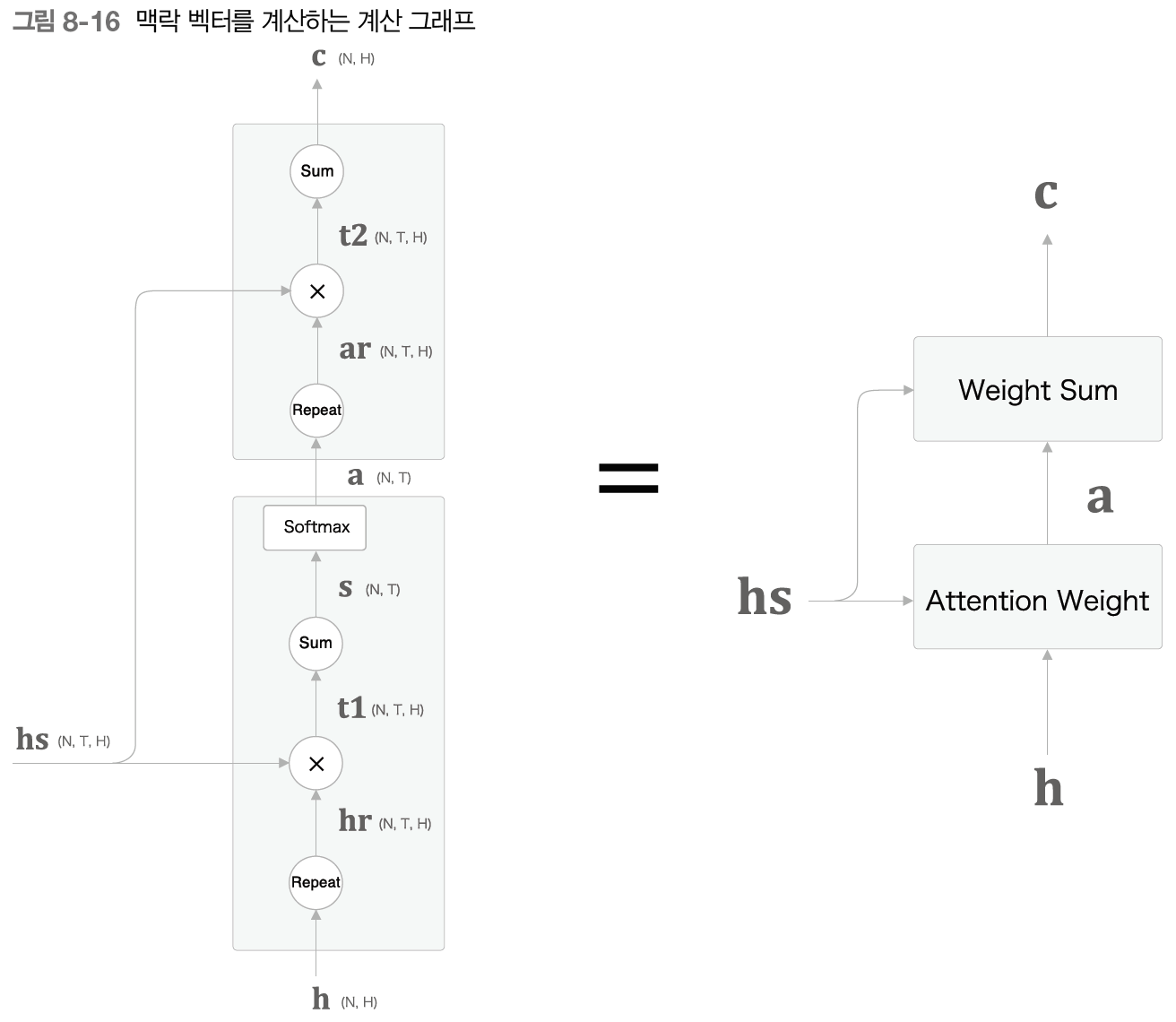
2번째로 설명할 faster R-CNN은 Object Detection에 사용되는 모델로, Object Detection의 시초인 R-CNN을 개선한 모델이다. 따라서 faster R-CNN을 설명하기 앞서 R-CNN을 포함한 Object Detection의 주요한 논문들의 흐름을 설명하겠다.
R-CNN
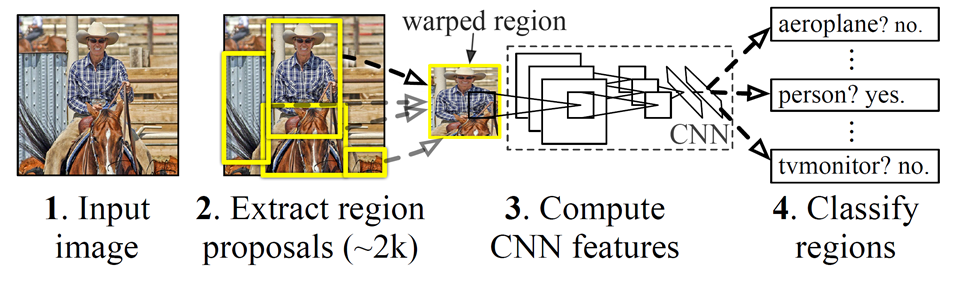

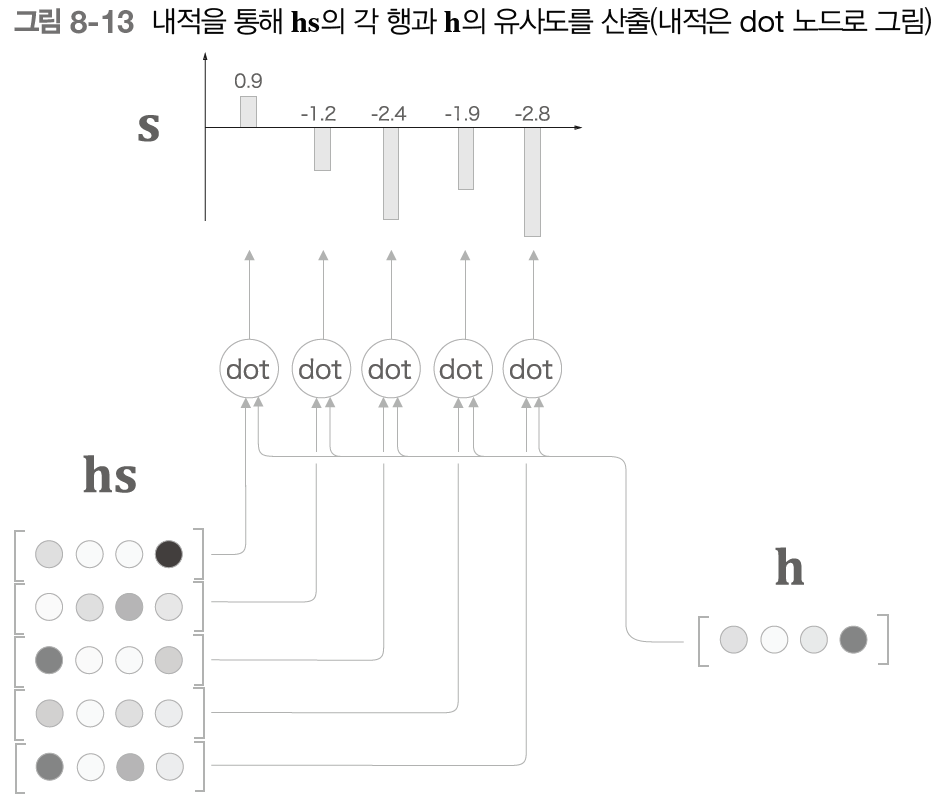
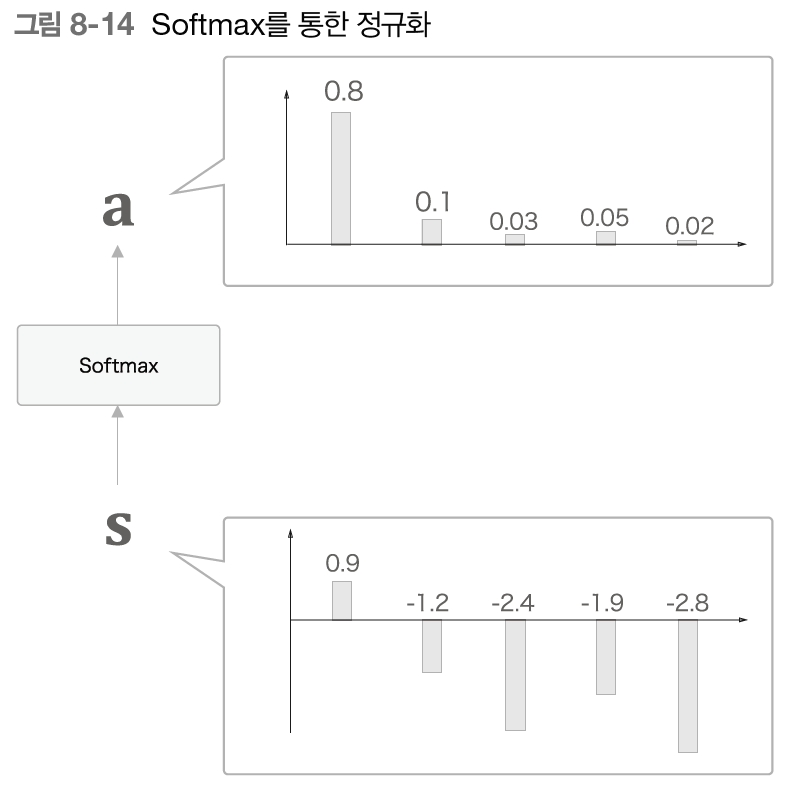
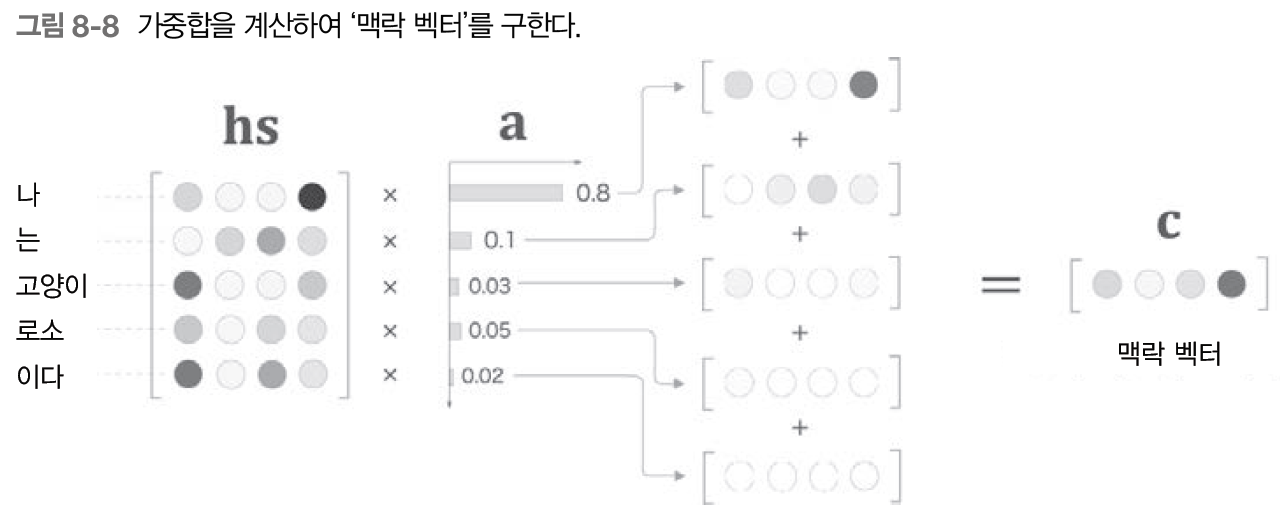
R-CNN은 말 그대로 CNN을 사용하여 Object Detection에서 높은 성능을 보였다. R-CNN의 구조를 그림으로 설명하자면 위의 이미지들로 나타낼 수 있으며, R-CNN의 학습과정을 자세히 설명하자면 다음과 같다.
알고리즘
1. Input으로 들어온 이미지를 Selective Search 알고리즘을 사용하여 후보 영역(Region proposal)을 생성한다. (~2k : 2000여개)
2. 각각의 후보 영역(Region proposal)을 고정된 크기로 Warp하여 CNN input으로 사용한다.
+) CNN은 이미 ImageNet을 활용한 pre-trained된 네트워크를 사용 + fine tune(Object Detection용 데이터 셋 사용)
3. CNN을 통해 나온 feature map을 사용하여 벡터를 추출하고 클래스 별로 SVM Classifier 학습, regressor를 통한 Bounding Box Regression을 진행한다.
+) SVM Classification을 한 후의 2000여개의 박스들은 어떤 물체일 확률 값을 갖게 되며, 2000여개의 박스를 모두 사용하는 것이 아닌, 가장 확률값이 높은 박스만을 사용하기 위해 IoU(Intercetion over Union)을 적용하여 물체 전체를 대상화할 수 있는 박스 한개를 만들어낸다. 이 과정을 Non-Maximun Supperssion이라고 하며, IoU는 쉽게 말해 두 박스의 교집합을 합집합으로 나눠준 값으로 두 박스가 일치할수록 1에 가까운 값이 나오게 된다.
+) Bounding Box Regression을 사용하는 이유는 Selective Search를 통해 찾은 박스 위치가 부정확하기 때문에 모델의 성능을 높이기 위해 박스 위치를 교정하기 위해 사용한다. 박스의 위치를 조절하는 과정은 박스의 좌표 및 너비 높이를 조정하는 함수의 가중치를 곱하며 선형 회귀 학습을 시키기 때문에 Regression이 함께 들어가 있다.
R-CNN의 한계점
- 합성곱 신경망(conv)의 입력을 위한 고정된 크기를 위해 wraping/crop을 사용해야 하며, 그 과정에서 input 이미지 정보의 손실이 일어난다.
- 2000여개의 영역마다 CNN을 적용해야 하기 때문에 학습 시간이 오래 걸린다.
- 학습이 여러 단계(conv-SVM Classifier/Bounding Box Regression)로 이루어지기 때문에 학습 시간이 오래 걸리며, 대용량의 저장 공간을 필요로 한다.
- Object Detection 속도가 느리다. (이미지 하나당 CPU에서 54', GPU에서 13')
이와 관련해 더 자세한 설명을 필요로한다면 여기를 참고하길 바란다. 설명이 매우 친절히 되어있고 Object Detection에 대한 논문들이 순차적으로 정리되어 있어 이해하기 편하다.
Fast R-CNN을 설명하기에 앞서 SPPNet에 대해서도 설명하면 좋지만 내가 여기서 말하고 싶은 논문은 Faster R-CNN이기 때문에 SPPNet에 대한 내용은 여기와 여기를 참고하길 바란다.
SPPNet

SPPNet에 대해 간략히 설명하자면 R-CNN의 단점을 보완하고자 만들어진 모델로, R-CNN은 Region proposal을 하나 하나 conv input으로 사용한 반면, SPPNet은 input 이미지 자체를 Convolution Network를 통해 feature map을 만들고 그 feature map으로부터 Region proposal을 만든다는 차이점이 있다. 이 덕에 SPPNet은 학습 속도를 개선할 수 있었다.
Fast R-CNN

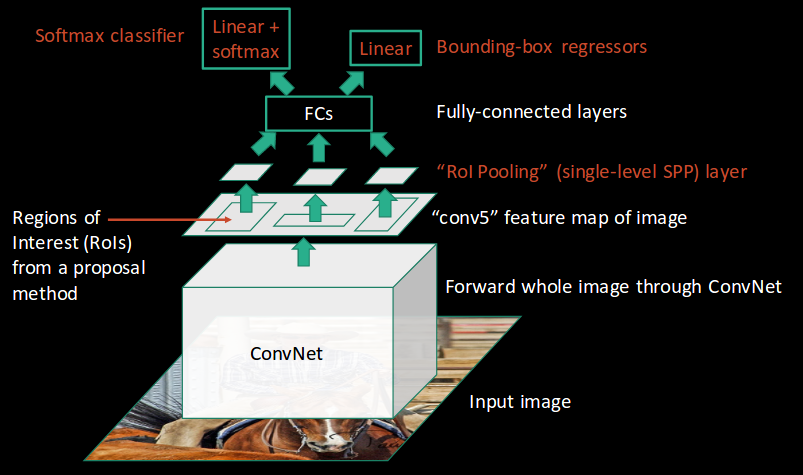
Fast R-CNN은 R-CNN과 SPPNet의 단점을 개선하고자 나온 모델이다. R-CNN과 SPPNet의 단점은 학습이 여러 단계로 진행되며, 그로 인해 많은 학습 시간과 GPU 계산 용량이 요구되고 Object Detect에 있어 시간이 오래 걸린다는 것이다.
Fast R-CNN은 CNN 특징 추출 및 Classification, Bounding Box Regression을 모두 하나의 모델에서 학습시키고자 한 모델이다.
알고리즘
1. 전체 이미지를 미리 학습된 CNN을 통과시켜 feature map을 추출한다.
2. feature map에서 RoI(Region of Interest)들을 찾아준다.
+) RoI들은 input 이미지에서 Selective Search를 통해 찾은 것을 feature map에 적용한 것이다.
3. (Selective Search를 통해 찾은) 각각의 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 벡터를 추출한다.
4. feature vector는 fully vector들을 통과한 후, softmax와 bounding box regression의 input으로 들어간다.
+) softmax는 SVM을 대신하는 방법으로, 해당 RoI가 어떤 물체인지를 classification한다.
+) bounding box regression은 selective search로 찾은 박스의 위치를 조절한다.
Fast R-CNN은 SPPNet처럼 input 이미지를 CNN에 통과한 뒤, 그 feature map을 공유한다.
SPPNet은 그 뒤의 과정이 R-CNN과 동일하지만, Fast R-CNN은 RoI Pooling을 사용하여 end-to-end로 학습 가능하게 했다는 것이 가장 큰 특징이다. 이러한 end-to-end 학습이 가능하게 되면서 학습 속도와 정확도를 모두 향상시킬 수 있게 되었다.
RoI Pooling Layer
Fast R-CNN의 핵심인 RoI Pooling은 RoI 영역에 해당하는 부분만 max-pooling을 통해 feature map으로부터 고정된 길이의 저차원 벡터로 축소하는 단계를 의미한다. RoI Pooling에 대한 자세한 내용은 아래의 그림을 참고하며 설명하도록 하겠다.
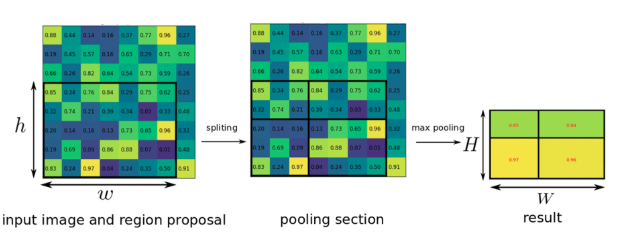
위의 h*w의 영역이 바로 CNN의 output인 feature map에서 RoI 영역에 해당한다. 이 RoI 영역은 CNN을 통과한 feature map에 selective search 기반의 region proposal을 통해 추출된다.
이렇게 정의된 RoI(h*w)를 H*W의 고정된 작은 윈도우 사이즈로 나누고, 나눠진 영역에서 max-pooling을 적용하면 결과값으로 항상 H*W 크기의 feature map이 생성된다. 이런 pooling을 하는 이유는, 다 제각각의 크기인 RoI 영역을 동일한 크기로 맞춰 fc(fullly connect) layer로 넘기기 위함이다.
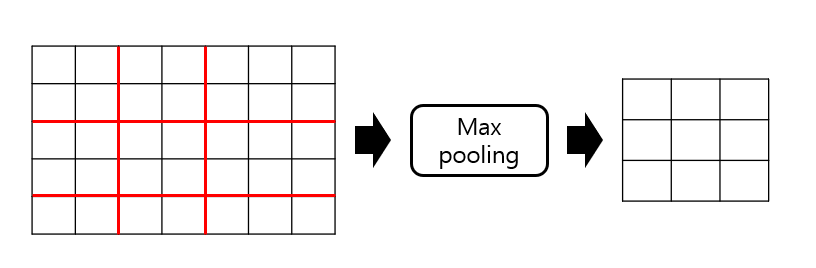
위의 이미지를 보면 RoI 영역 안의 max-pooling 영역이 모두 동일하지 않음을 알 수 있다. 그럼에도 불구하고 고정된 길이의 벡터로 만드는 것이 RoI pooling layer의 역할이다.
이렇게 RoI pooling layer를 통해 전부 동일한 크기가 된 output들은 fully connected layer를 거쳐 softmax classifcation과 bounding box regression이 수행된다.
이 모든 과정들이 하나의 conv 모델에 의해 동시에 수행되기 때문에 연산속도가 빠르고 정확도가 높아질 수 있었다.
Fast R-CNN은 RoI pooling layer를 사용하여 CNN 특징 추출 및 Classification, Bounding Box Regression을 모두 하나의 모델에서 학습시킬 수 있게 되어 R-CNN과 SPPNet에 비해 빠른 연산 속도와 정확도를 나타낼 수 있었다. 하지만 여전히 Region proposal을 selective search로 수행하여 Region proposal 연산이 느리다는 단점이 있다. (selective search 알고리즘은 GPU를 사용하기 부적합하다.)
Fast R-CNN에 대해 더 자세한 설명이 필요하다면 여기, 여기, 여기를 참고하길 바란다.
Faster R-CNN
Faster R-CNN은 이름과 같이 Fast R-CNN의 개선된 모델로, end-to-end 구조를 위한 전체적인 모델 구조는 Fast R-CNN과 동일하다. 하지만 Fast R-CNN의 단점이었던 Region Proposal을 개선하고자 selective search를 사용하지 않고, Region Proposal Network(RPN)를 통해서 RoI를 계산한다. 이 덕분에 GPU를 통해 RoI 연산이 가능해졌으며 RoI 연산도 학습을 시켜 정확도를 높였다. 따라서 기존의 Selective Search는 2000여개의 RoI를 계산하는 반면 RPN은 더 적은 수의 RoI를 계산하면서도 높은 정확도를 보인다.

위의 이미지를 보면 알 수 있다시피, Faster R-CNN은 RoI를 구하는 방법으로 RPN을 사용하는 것 외에는 Fast R-CNN과 모두 동일하다는 것을 알 수 있다. 그렇다면 RPN의 구조는 정확하게 어떻게 생긴걸까? 이에 대한 내용을 아래에 자세히 다루도록 하겠다.
Region Proposal Network
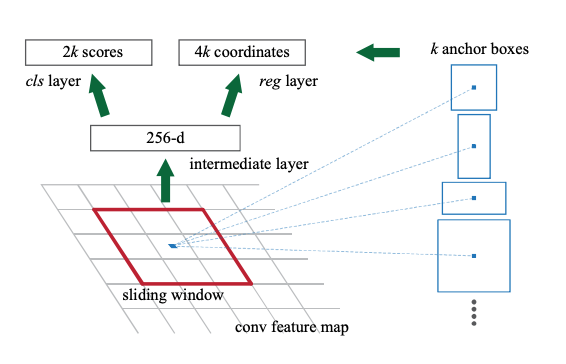
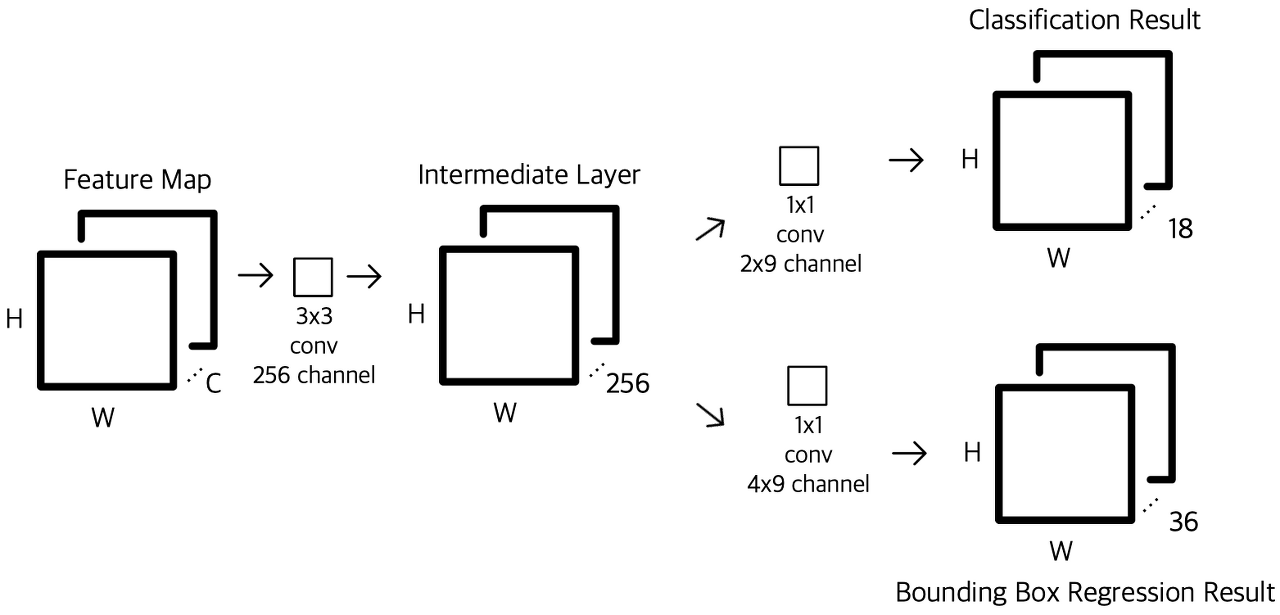
참고한 블로그에 의하면 아래의 이미지가 더 직관적으로 RPN의 구조를 이해하기 쉬운 이미지라고 하여 둘 다 갖고 왔다. RPN이 동작하는 원리는 다음과 같다.
알고리즘
1. CNN을 통해 뽑아낸 feature map을 입력으로 받는다. 이 때, feature map의 크기를 H*W*C(세로*가로*채널수)로 잡는다.
2. feature map에 3x3 convolution을 256 channel (or 512 channel)만큼 수행한다. 이 때, padding을 1로 설정해주어 H x W가 보존되도록 진행하며, intermediate layer 수행 결과 H*W*256 (or 512) 크기의 두 번째 featur map을 얻는다.
3. 2번째 feature map을 입력으로하여 classification(cls layer)과 bounding box regression(reg layer) 예측 값을 계산한다.
+) 이 과정은 Fully Connected Layer가 아니라 1 x 1 컨볼루션을 이용하여 계산하는 Fully Convolution Network의 특징을 갖는다. 이는 입력 이미지의 크기에 상관없이 동작할 수 있도록 하기 위함이며 자세한 내용은 Fully Convolution Network을 참고하길 바란다.
4. Classification layer에서는 1 x 1 컨볼루션을 (2(Object인지 아닌지를 나타냄) x 9(앵커(Anchor) 개수)) 채널 수 만큼 수행하며, 그 결과로 H*W*18 크기의 feature map을 얻는다. H*W 상의 하나의 인덱스는 피쳐맵 상의 좌표를 의미하고, 그 아래 18개의 채널은 각각 해당 좌표를 Anchor로 삼아 k개의 앵커 박스들이 object인지 아닌지에 대한 예측 값을 담는다. 즉, 한번의 1x1 컨볼루션으로 H x W 개의 Anchor 좌표들에 대한 예측을 모두 수행할 수 있다. 이제 이 값들을 적절히 reshape 해준 다음 Softmax를 적용하여 해당 Anchor가 Object일 확률 값을 얻는다.
+) 여기서 앵커(Anchor)란, 각 슬라이딩 윈도우에서 bounding box의 후보로 사용되는 상자를 의미하며 이동불변성의 특징을 갖는다.
5. Bounding Box Regression 예측 값을 얻기 위한 1 x 1 컨볼루션을 (4 x 9) 채널 수 만큼 수행하며 regression이기 때문에 결과로 얻은 값을 그대로 사용한다.
6. Classification의 값과 Bounding Box Regression의 값들을 통해 RoI를 계산한다.
+) 먼저 Classification을 통해서 얻은 물체일 확률 값들을 정렬한 다음, 높은 순으로 K개의 앵커를 추려낸다. 그 후, K개의 앵커들에 각각 Bounding box regression을 적용하고 Non-Maximum-Suppression을 적용하여 RoI을 구한다.
Training
Faster R-CNN은 크게 RPN과 Fast R-CNN으로 구성되어있는 것으로 나눌 수 있고, 결론적으로 RPN이 RoI를 제대로 만들어야 학습이 잘 되기 때문에 4단계에 걸쳐 모델을 번갈아 학습시킨다. 4단계는 다음과 같다.
1. ImageNet pretrained 모델을 불러온 후, Region Proposal을 위해 end-to-end로 RPN을 학습시킨다.
2. 1단계에서 학습시킨 RPN에서 기본 CNN을 제외한 Region Proposal layer만을 가져와 Fast R-CNN을 학습시킨다.
+) 첫 feature map을 추출하는 CNN까지 fine tune을 시킨다.
3. 학습시킨 Fast R-CNN과 RPN을 불러와 다른 가중치들(공통된 conv layer 고정)을 고정하고 RPN에 해당하는 layer들만 fine tune 시킨다.
+) 이 때부터 RPN과 Fast R-CNN이 conv weight를 공유하게 된다.
4. 공유된 conv layer를 고정시키고 Fast R-CNN에 해당하는 레이어만 fine tune 시킨다.
이러한 과정을 통해 만들어진 Faster R-CNN은 굉장히 빠른 속도와 높은 정확도를 보인다. 여기에 쓰지는 않았지만 Faster R-CNN의 손실함수에 대해 알고 싶다면 여기를 참고하길 바란다.
또한 내가 Faster R-CNN을 공부하면서 참고했던 유튜브와 블로그의 링크를 남길테니 참고하길 바란다.
Object Detection 전체 흐름을 알려주는 블로그, 유튜브1, 유튜브2
R-CNN / SPPNet / Fast R-CNN / Faster R-CNN (계보) 요약
| R-CNN | RoI(Selective Search) ☞ conv ☞ SVM, Bbox reg |
| SPPNet | conv ☞ RoI(Selective Search) ☞ SVM, Bbox reg |
| Fast R-CNN | conv ☞ RoI(Selective Search) ☞ RoI pooling layer ☞ Softmax, Bbox reg |
| Faster R-CNN | conv ☞ RoI(Region Proposal Network) ☞ RoI pooling layer ☞ Softmax, Bbox reg |
'인공지능 > 논문 리뷰' 카테고리의 다른 글
| 1. Attention Is All You Need (3) | 2020.11.02 |
|---|