이전에 소개했던 word2vec은 기존의 자연어 처리 방법보다 효과적이지만, 치명적인 단점이 존재하는데 맥락이 길어지면 길어질수록 그와 비례해 가중치 매개변수가 늘어나 연산량이 늘어난다는 점이다. 이 문제 때문에 우리는 결국 엄청난 말뭉치의 데이터를 학습하는데 어려움을 겪게 된다. 이 단점의 근본적인 원인은 우리가 이전에 배웠던 신경망들은 전부 feed forward 유형의 신경망이었기 때문이다. feed forward란 흐름이 단방향인 신경망을 의미하고 feed forward는 시계열 데이터의 성질(패턴)을 충분하게 학습할 수 없다.
그 이유를 간단하게 말하자면 feed forward 방식은 단방향의 신경망으로, 흐름을 따라갈수만 있지 기억할 수 없기 때문이다. 자연어나 기타 시계열 데이터는 데이터의 흐름성을 기억하며 그 흐름성의 특징을 기억해야하기 때문에 기존의 feed forward 방식의 신경망으로는 시계열 데이터를 다룰 수 없다. 따라서 우리는 시계열 데이터를 처리할 때 RNN이라는, 직역하면 순환 신경망인 신경망을 사용한다.
RNN(Recurrent Neural Network)
RNN은 기존의 feed forward방식의 한계점을 개선하고자 순환하는 경로가 있다. 순환하는 경로가 뭐고 왜 필요한걸까? 순환하는 경로는 다른 말로 닫힌 경로라고도 불리며, 이 경로가 존재해야 데이터가 같은 장소를 반복해 왕래할 수 있고 그 데이터가 순환하며 과거의 정보를 기억하는 동시에 새로운 정보를 끊임없이 갱신할 수 있다.
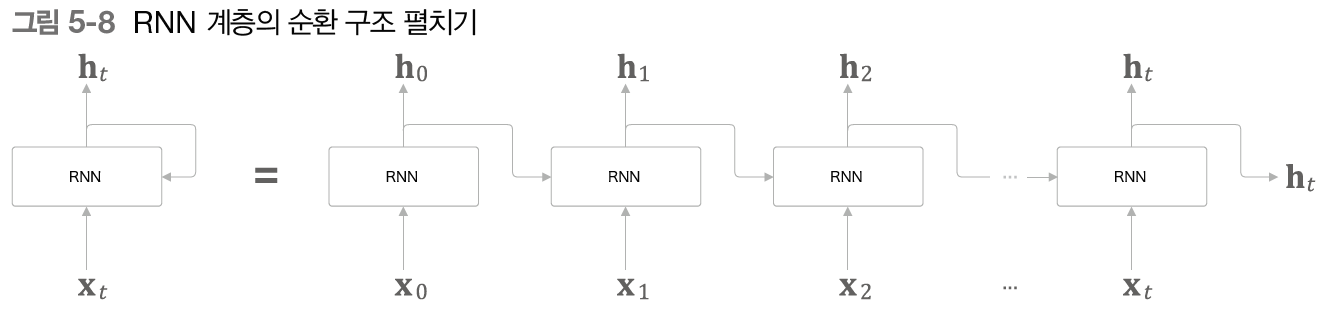
Xt는 RNN 계층에 입력되는 시계열 데이터를 의미하며 그 입력에 대응한 출력이 ht로 나오게 된다. Xt를 조금 더 자세히 설명하자면 문장 데이터인 경우, 각 단어의 분산 표현(단어 벡터)이 Xt가 되며, 이 분산 표현이 순서대로 하나씩 RNN 계층에 입력됨을 의미한다. 위의 계층은 결론적으로 오른쪽으로, 즉 한 방향으로 뻗어나가는 구조를 갖고, 이는 feed forward 신경망과 같은 구조이나 각 RNN 계층이 그 계층으로의 입력(X1)과 전의 RNN 계층으로부터의 출력(h0)을 받아 두 정보를 바탕으로 현 시각의 출력을 계산한다.
이때문에 RNN 의 가중치는 2개인데 하나는 입력 x를 출력 h로 변환하기 위한 가중치 Wx이고 하나는 RNN 출력을 다음 시각의 출력으로 변환하기 위한 가중치 Wh이다. 위의 이미지를 보면 각 RNN의 계산 결과인 ht는 출력이 되면서 다음 RNN 계산에 입력되는데, 이 ht는 각 RNN의 출력 결과물로 상태를 의미한다. 따라서 RNN 계층을 상태를 갖는 계층 혹은 메모리(기억력)가 있는 계층이라고 표현한다. 또한 RNN의 출력 ht는 은닉 상태 또는 은닉 상태 벡터라고도 한다.
BPTT(Backpropagation Through Time)
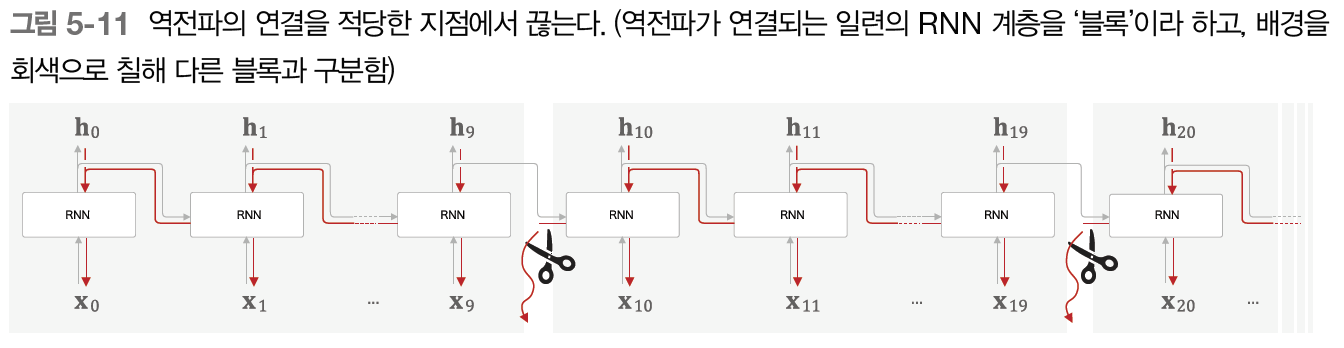
위의 이미지와 같이 순환 구조를 펼친 후의 RNN에는 일반적인 오차역전파법을 적용할 수 있다. 이를 시간 방향으로 펼친 신경망의 오차역전파법이라는 뜻으로 BPTT라고 한다. 우리는 BPTT를 통해 RNN을 학습할 수 있게 되는데, 긴 시계열을 학습할 경우에는 메모리 사용량 증가 및, 시간 크기가 커질수록 기울기가 불안정하다는 문제점이 발생한다. 이를 해결하기 위한것이 바로 Truncated BPTT기법이다.
Truncated BPTT
시간축 방향으로 너무 길어진 신경망을 적당한 지점에서 잘라내어 작은 신경망 여러 개로 만든다는 아이디어를 사용하여, 잘라낸 작은 신경망에서 오차역전파법을 수행하면 기존 BPTT에서 발생할 수 있는 문제점을 해결할 수 있다. Truncated BPTT는 순전파는 그대로 유지하고(계속 연결됨) 역전파의 연결만 끊는다.
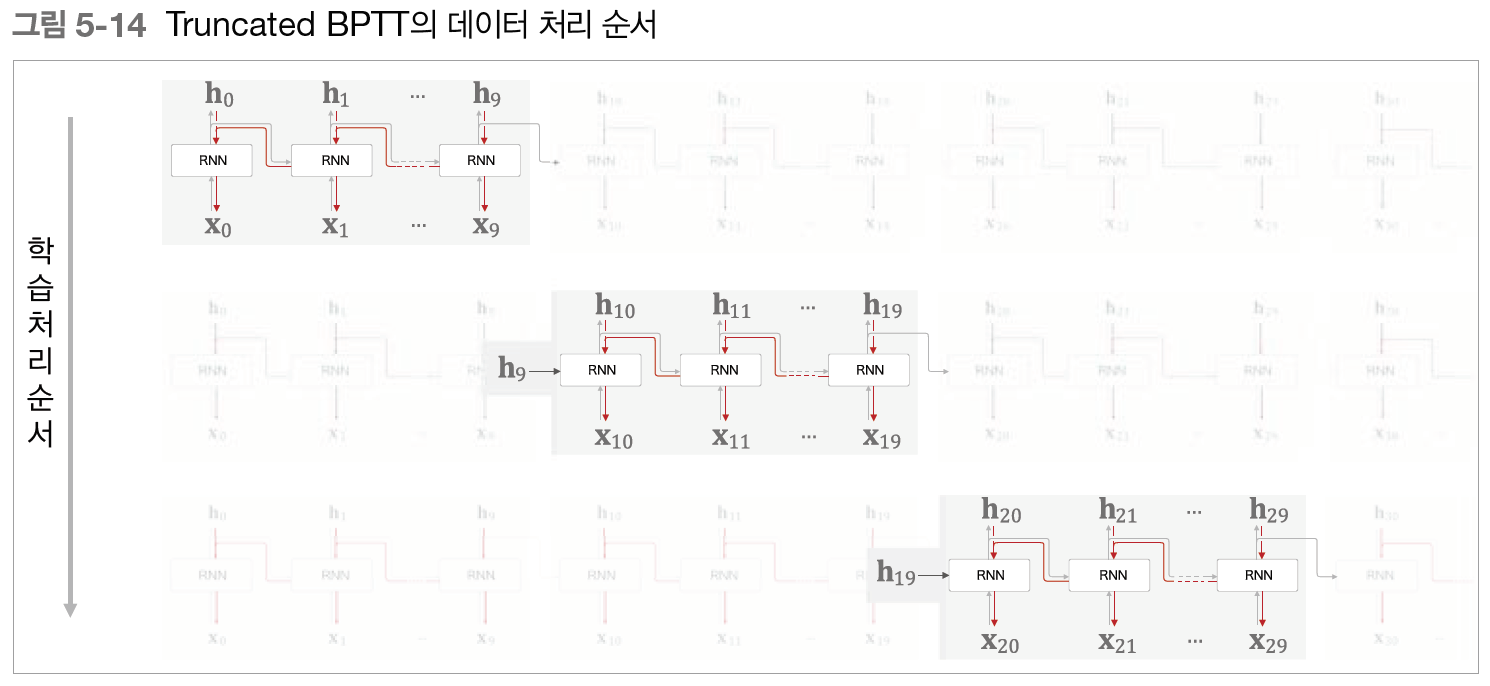
Truncated BPTT 또한 미니배치 학습을 진행할 수 있는데, 미니배치 학습 수행을 할 경우, 데이터를 제공하는 시작 위치를 각 미니배치(각 샘플)로 옮겨준 후 순서대로 제공하면 된다. 또한 데이터를 순서대로 입력하다 끝에 도달하면 다시 처음부터 입력하도록 하여 RNN의 특징을 살리면서 미니배치 학습을 할 수 있다. Truncated BPTT는 긴 시계열 데이터 학습 시 메모리 사용량 증가와 기울기 불안정 문제를 해결하기 위해 역전파의 경우에만 신경망을 일정하게 끊어 역전파를 구하는 방법이다. 이 Truncated BPTT는 데이터를 순서대로 제공하는 것과 미니배치별로 데이터를 제공하는 시작 위치를 옮기는 것이 데이터 제공 면에서 가장 중요하다.
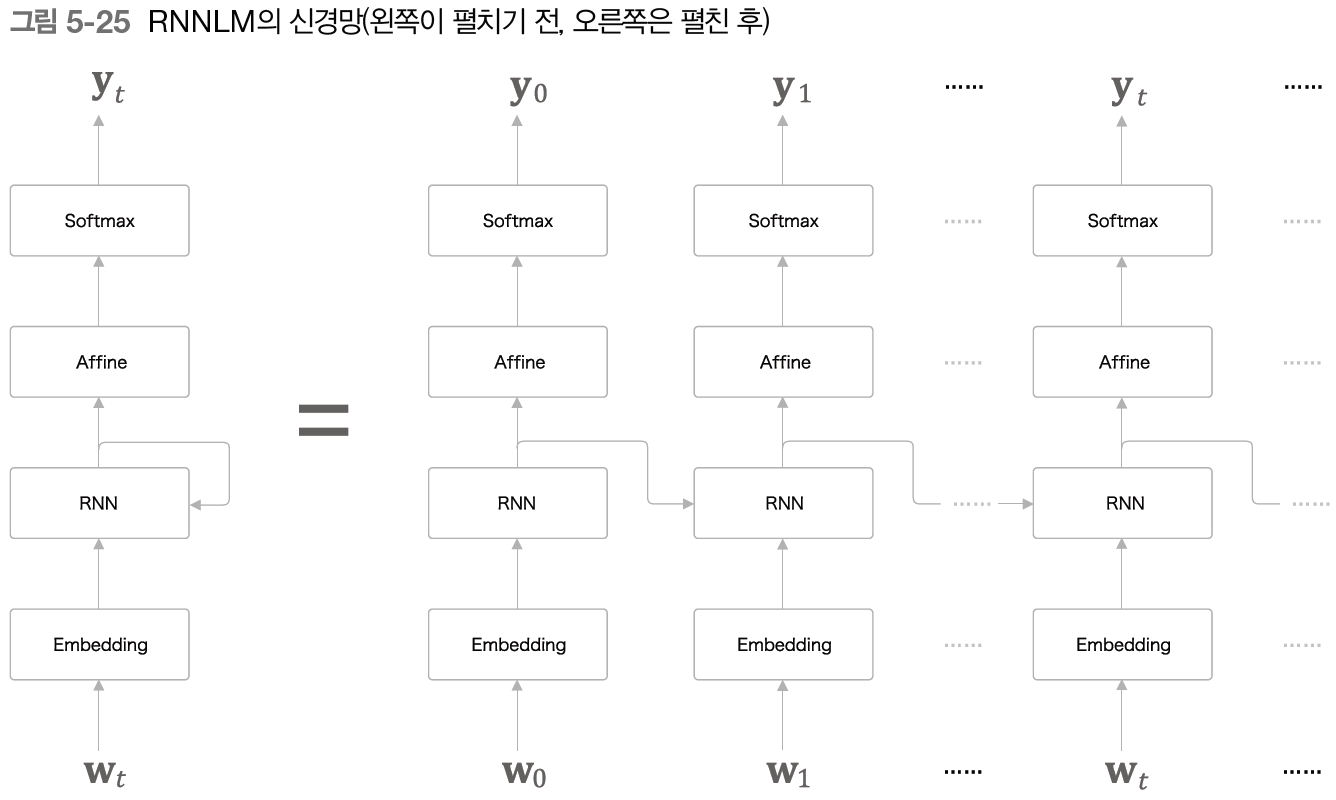
위의 그림은 RNN Language Model(RNNLM)로, 자연어를 처리하는 RNN이라고 보면 된다. 단어ID인 Wt가 들어가 Embedding 계층을 통해 단어의 분산 표현(딴어 벡터)으로 변환된다. 이 분산 표현이 RNN에 들어가고 RNN의 출력 데이터는 은닉상태(ht)를 Affine층으로 출력함과 동시에, 다음 시각의 RNN 계층으로 출력하게 된다.

RNN을 이용하여 자연어를 처리(RNNLM)하면 이전에 설명했던 word2vec 신경망과는 달리 이전의 데이터에 대한 정보도 기억하고 있다. RNN은 과거의 정보를 응집된 은닉 상태 벡터(ht)로 저장해두고 있다. 이 정보를 Affine 계층에, 그리고 다음 시각의 RNN 계층에 전달하는 것이 RNN 계층이 하는 일이다.
이러한 RNNLM은 지금까지 입력된 단어를 '기억'하고, 그것을 바탕으로 다음에 출현할 단어를 예측한다. 이것이 가능한 이유는 RNN 계층이 과거에서 현재로 데이터를 계속 흘려보내주기 때문에 과거의 정보를 인코딩해 저장(기억)할 수 있기 때문이다.
언어 모델은 주어진 과거 정보(단어)로부터 다음에 출현할 단어의 확률분포를 출력한다. 이 때 언어 모델의 예측 성능을 평가하는 척도로 퍼플렉서티(Perplexity,혼란도)를 자주 사용한다. 퍼플렉서티는 확률의 역수로, 퍼플렉서티가 작으면 작을수록 좋은 모델이다. 이것에 대해 조금 더 자세히 말하자면, 퍼플렉서티는 분기수로 해석할 수 있으며 이 말은 퍼플렉서티가 1에 가까우면 단어의 후보가 1개라는 의미이고, 퍼플렉서티가 5이면 단어의 후보가 5개라는 의미이다. 따라서 퍼플렉서티가 작으면 작을수록 분기수, 즉 단어의 후보 수도 적기 때문에 좋은 모델이 된다.
'인공지능 > 인공지능 이론' 카테고리의 다른 글
| 29. seq2seq (0) | 2020.10.06 |
|---|---|
| 28. LSTM(Long Short-Term Memory) (2) | 2020.10.05 |
| 26. 자연어 처리 2) 단어의 분산 표현 얻는 방법 - 추론 기반 기법(word2vec) (0) | 2020.10.04 |
| 25. 자연어 처리 1) 단어의 의미 이해시키기(단어의 분산 표현 얻는 방법) (0) | 2020.09.28 |
| 24. im2col 이해하기 - Pooling Layer (0) | 2020.08.13 |