seq2seq
seq2seq는 발음 그대로 sequence to sequence라는 뜻으로 여기서 sequence는 시계열 데이터를 의미한다. 즉, seq2seq는 하나의 시계열 데이터를 다른 시계열 데이터로 변환하는 모델을 의미한다. 예를 들자면 음성 인식 및 챗봇과 같은 것이 있겠다. seq2seq는 2개의 RNN을 사용한다.
seq2seq를 다른 말로 Encoder-Decoder 모델이라고도 한다. 이는 seq2seq가 Encoder와 Decoder를 사용하기 때문이며, Encoder는 입력 데이터를 인코딩(부호화)하고, Decoder는 인코딩된 데이터를 디코딩(복호화)한다.
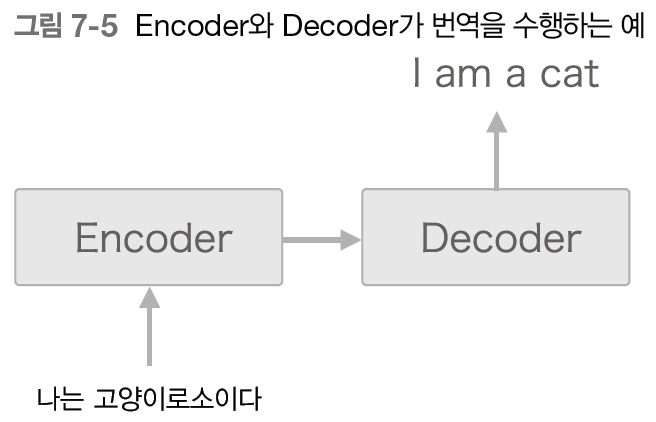
위의 이미지처럼 Encoder가 인코딩한 정보에는 번역에 필요한 정보가 있고, Decoder는 이 정보를 바탕으로 문장을 생성해 출력한다. 이처럼 Encoder와 Decoder를 사용해 시계열 데이터를 다른 시계열 데이터로 변환하는 것이 seq2seq의 전체 그림이며, 우리는 Encoder와 Decoder에서 RNN을 사용한다.
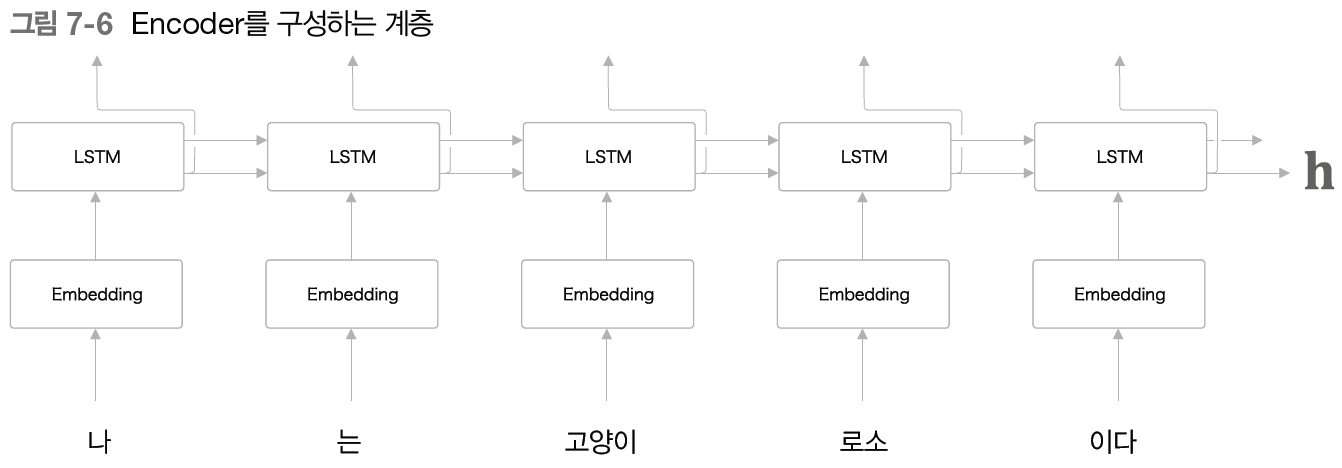
Encoder는 RNN(LSTM)을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환한다. Encoder에서 출력되는 h는 입력 문장(출발어)을 번역하는 데 필요한 정보가 인코딩되며 은닉 벡터 h는 고정 길이 벡터로, 결론적으로 인코딩의 의미는 임의 길이의 문장을 고정 길이 벡터로 변환하는 작업을 뜻한다.
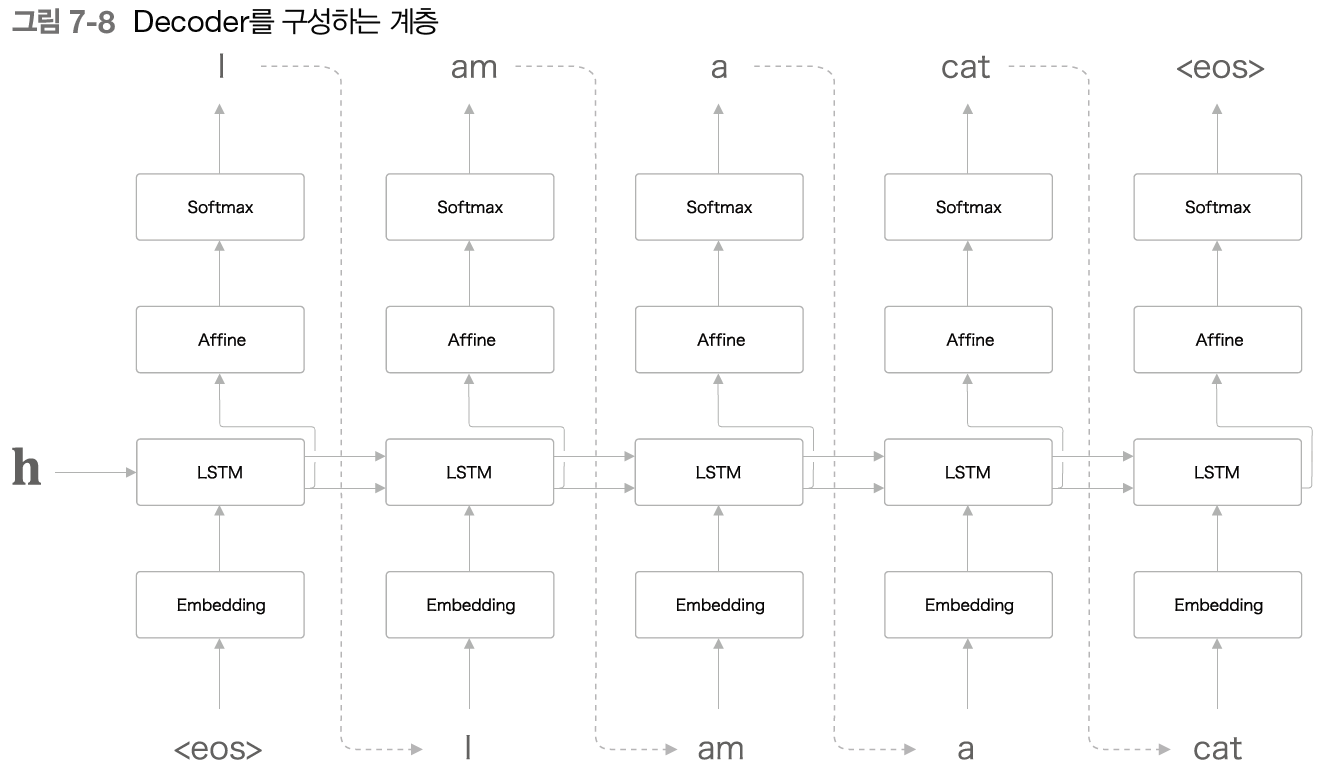
Decoder는 RNNLM과 동일한 구조(위에서는 RNN을 LSTM으로 대체함)이지만, LSTM 계층에 h를 입력받고 첫번째 단어가 <eos>라는 특수문자인 것이 큰 차이점이다. <eos>는 문장의 시작을 의미하며, 실질적으로 Decoder는 h의 데이터를 활용하여 문장을 생성해 나간다. Decoder의 첫번째 LSTM 셀은 h와 <eos>, 이 2개의 입력을 바탕으로 새로운 은닉 상태h를 계산하고 이를 Affine 계층과 Softmax 계층을 거쳐 다음에 등장할 확률이 높은 "I"를 예측한다. 이 과정을 문장의 종료를 의미하는 <eos>가 나올때까지 반복하는 것이 Decoder의 개념이다.
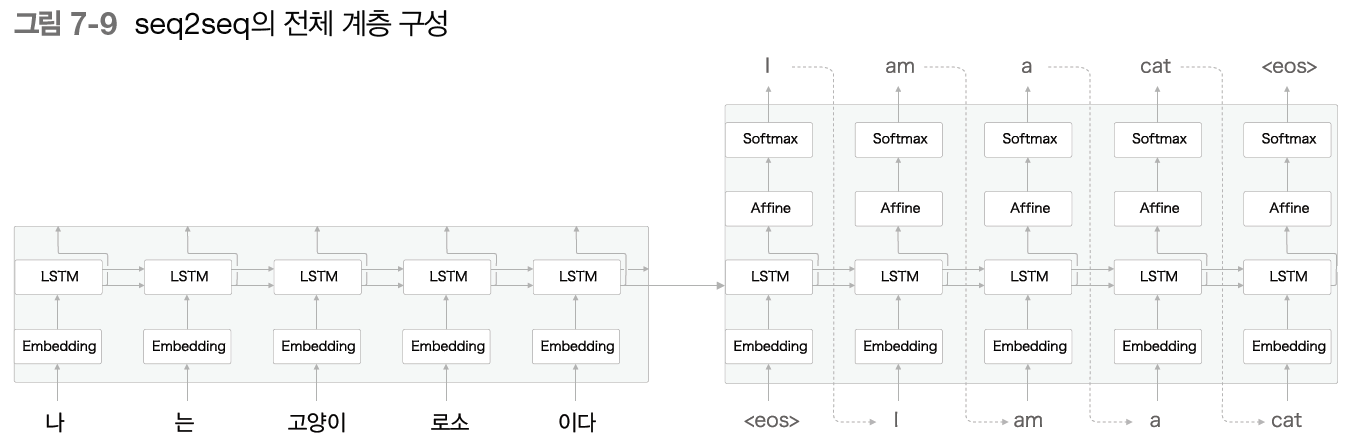
이처럼 seq2seq는 2개의 LSTM(Encoder의 LSTM과 Decoder의 LSTM)로 구성되며 Encoder의 LSTM에서 생성된 은닉 벡터인 h가 Decoder의 LSTM에 전해지면서 서로 다른 시계열 데이터로의 변환이 이루어질 수 있게 된다.
추가적으로 seq2seq 역시 신경망이기 때문에 미니배치 학습이 가능한데, 여기서 문제가 발생한다. 만약 seq2seq에 입력되는 문장의 길이들이 모두 동일하지 않고 다른 경우에 어떻게 미니배치 학습을 시킬 수 있을까? 미니배치는 미니배치에 속한 샘플들의 데이터 형상이 모두 똑같아야 하기때문에 패딩(padding)을 사용하여 전체 데이터의 길이를 일정하게 맞춰준다. 패딩은 원래의 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 기법이다.
seq2seq 개선
1. 입력 데이터 반전(Reverse)
입력 데이터를 반전시키는 것만으로도 놀랍게도 seq2seq의 학습 속도는 빨라지고 정확도도 향상된다. 이에 대한 이론적인 부분에 대해서는 정확히 아는 바가 없지만, 참고한 책의 저자는 직관적으로 기울기 전파가 원활해지기때문이라고 한다. 나는 고양이로소이다.가 I am cat이 되기까지, '나'로부터 'I'까지 가기 위해서는 '는','고양이','로소',이다'까지 총 4가지 단어 분량의 LSTM 계층을 거쳐야하고 이는 기울기에 영향을 줄 수 있다. 따라서 입력 데이터를 반전하면 데이터가 대응하는 변환 후 단어와 가까워지는 경향이 많기 때문에 기울기가 더 잘 전해져서 학습 효율이 좋아진다고 이해할 수 있다.
2. 엿보기(Peeky)
이것은 DenseNet과 비슷한 개념을 갖고 있다. 즉, Decoder의 처음에 입력되면서 Encoder의 가장 중요한 정보를 갖고 있는 h가 단순히 Decoder 처음에만 입력되는 것이 아니라 다른 계층, 즉 Decoder 전체 계층에 전하는 것이다. 이처럼 중요한 정보를 하나의 LSTM 계층이 갖는 것이 아니라 모든 LSTM 계층이 갖게 되면 더 올바른 결정을 내릴 가능성이 커진다.
'인공지능 > 인공지능 이론' 카테고리의 다른 글
| 30. Attention(어텐션) (1) | 2020.10.07 |
|---|---|
| 28. LSTM(Long Short-Term Memory) (2) | 2020.10.05 |
| 27. RNN(순환 신경망) (0) | 2020.10.05 |
| 26. 자연어 처리 2) 단어의 분산 표현 얻는 방법 - 추론 기반 기법(word2vec) (0) | 2020.10.04 |
| 25. 자연어 처리 1) 단어의 의미 이해시키기(단어의 분산 표현 얻는 방법) (0) | 2020.09.28 |