어텐션(Attention)은 seq2seq의 문제점을 개선하기 위해 나온 해결책이다.
seq2seq의 문제점
seq2seq는 Encoder가 시계열 데이터를 인코딩하고, Encoder의 출력은 h(은닉 벡터)이며 h는 고정 길이의 벡터였다. 하지만 데이터가 모두 항상 동일한 길이일수도 없는 노릇이고 이것을 매번 고정 길이의 벡터로 출력하는 것은 데이터의 손실 및 공간 낭비의 문제가 발생하게 된다.
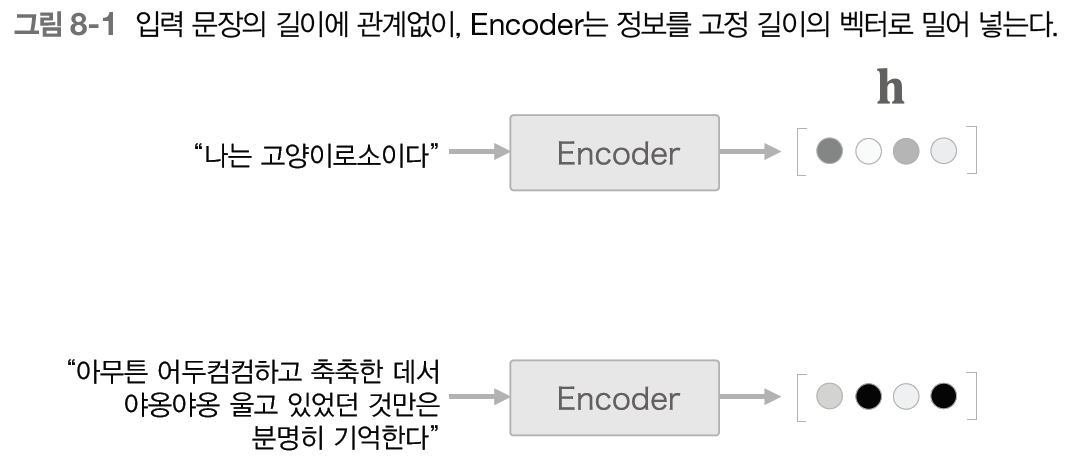
Encoder 개선
이전에 설명한 seq2seq에서 우리는 RNN(LSTM)의 마지막 은닉 상태(h)만을 Decoder에 전달했다. 하지만 위의 문제점을 해결하기 위해서는 Encoder의 출력은 고정 길이 벡터가 아닌, 문장 길이에 따라 바꿔주는 것이 좋다. 따라서 우리는 이 문제점을 해결하고자 시각별 RNN(LSTM) 계층의 은닉 상태 벡터를 모두 이용한다.
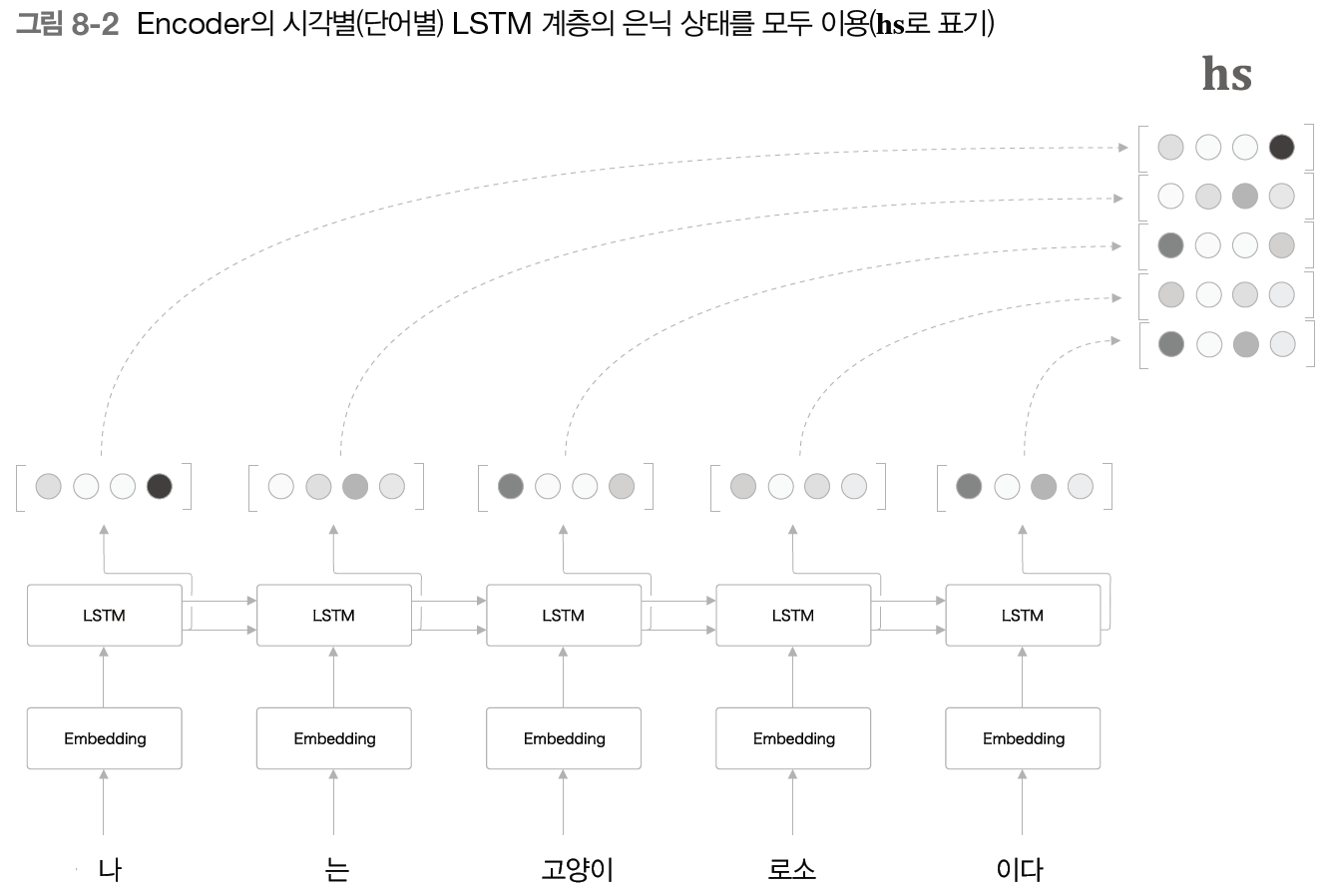
위의 이미지처럼 각 시각(단어)의 은닉 상태 벡터를 모두 이용하면 입력된 단어와 같은 수의 벡터를 얻을 수 있다. 이는 코드로는 RNN 계층의 초기화 인수로 return_sequences=True로 설정하면 모든 시각의 은닉 상태 벡터(hs)를 반환하게 된다. 단순히 모든 시각의 은닉 상태 벡터를 꺼내는 것만으로, 우리는 입력 문장 길이에 비례한 정보를 인코딩 할 수 있게 되었다.
Decoder 개선 - Attention 계층 사용
개선된 Encoder에서 보내는 hs를 활용하기 위해서는 Decoder 또한 개선해야 한다. 기존의 Decoder는 기존의 Encoder가 마지막 은닉 상태 벡터만을 Decoder로 넘겼기 때문에, hs 전체를 활용할 수 있도록 개선해야 한다. 그렇다면 Decoder는 어떻게 hs 전체를 활용할 수 있을까?
우리는 기존에 한개만 받던 h를 뭉태기(hs)로 받게되었다. 이 말은 즉슨, 문장 전체에 대한 정보를 입력받을 수 있다는 소리다. 이 덕에, 우리는 입력과 출력의 여러 단어 중 어떤 단어끼리 서로 관련되어 있는가에 대한 대응 관계를 학습할 수 있게 되었다. 이러한 구조를 어텐션(Attention)이라고 하며, 어텐션은 필요한 정보에만 주목하여 그 정보로부터 시계열 변환을 수행하도록 한다.
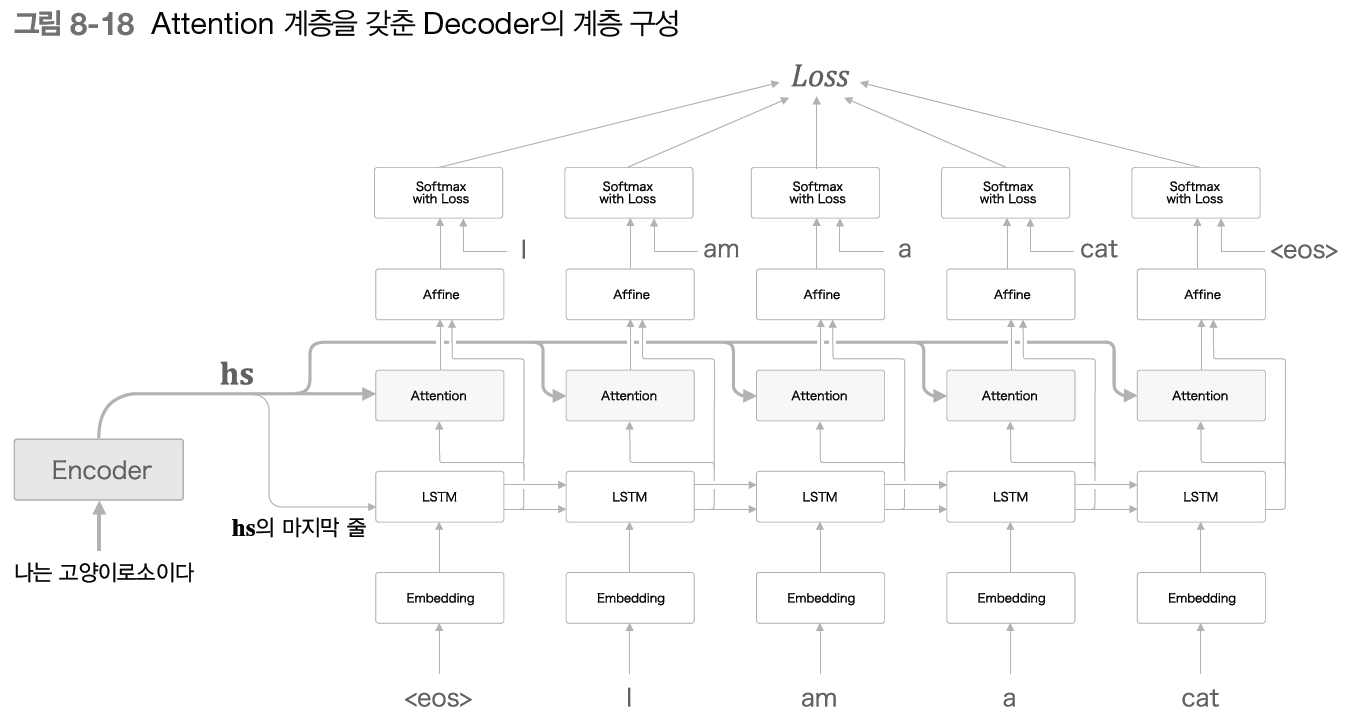
위의 그림은 어텐션이 사용된 개선된 Decoder이다. 여기서 어텐션 계층의 입력 데이터는 Encoder로부터 받는 hs와 시각별 LSTM 계층의 은닉상태 벡터(h)이다. 어텐션 계층에서의 계산을 통해 필요한(중요한) 정보만이 Affine 계층으로 출력된다.
어텐션의 기본 아이디어는 Decoder에서 출력 단어를 예측하는 매 시각마다, Encoder에서의 전체 입력 문장을 다시 한 번 참고한다는 것이다. 여기서 어텐션은 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 된다.
어텐션 계층의 대략적인 개념을 설명했으니, 그래서 어텐션 계층이 어떻게 동작하는지 살펴보도록 하자. 우리는 어텐션 계층이 필요한 정보만을 추출해낸다고 이해했다. 하지만 어텐션 계층도 결국에는 학습을 통해 갱신되는 계층이다. 학습을 통해 갱신됨은 역전파를 활용하여 매개변수값을 조정해 나가는 것이고 이것은 미분을 의미한다. 미분에는 '선택'이라는 개념은 없다. 그렇다면 우리는 어떤 계산을 해야하는걸까?
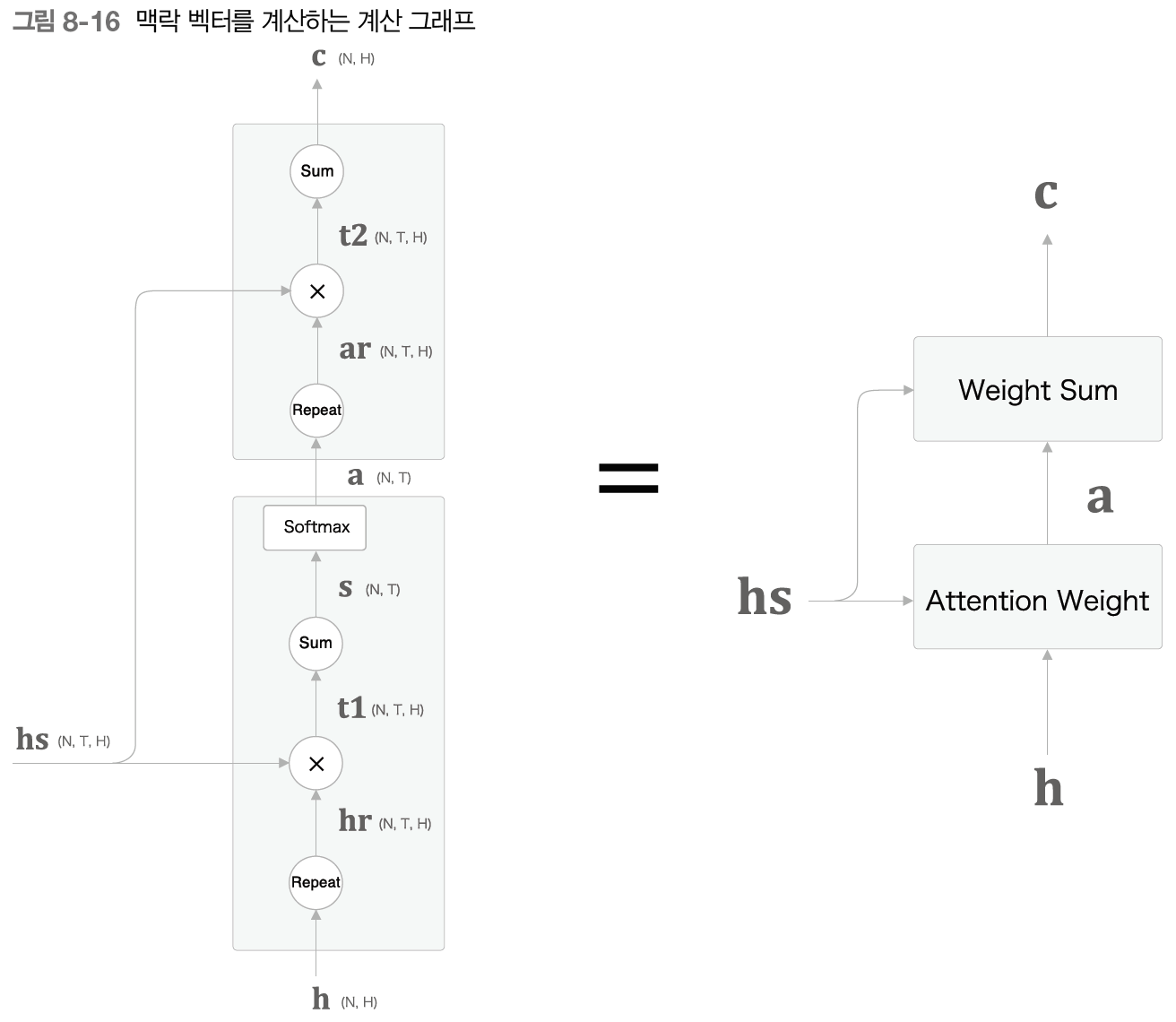
위의 이미지를 보면 Attention 계층은 크게 2가지의 중요 연산으로 나눠 볼 수 있다. 여기서 입력 데이터인 hs는 Enocoder에서 입력되는 모든 은닉 상태의 데이터이며, h는 hs를 활용하여(정확히는 hs 벡터의 마지막 줄) LSTM 계층 연산을 통해 출력된 은닉 상태 벡터(h)이다. Attention Weight은 Encoder가 출력하는 각 단어의 벡터 hs에 주목하여 해당 단어의 가중치 a를 구하고, Weight Sum은 a와 hs의 가중합을 구해 맥락 벡터 c를 출력한다.
Attention Weight
단어의 가중치(기여도)를 나타내는 벡터인 a는 어떻게 구하는걸까?
Decoder의 LSTM 계층의 은닉 상태 벡터는 h이며, 우리는 이 h가 Encoder의 입력 데이터인 hs와 얼마나 비슷한가를 수치로 나타내고자 한다. 이를 위해서 우리는 벡터의 내적을 이용한다. 벡터의 내적은 두 벡터가 얼마나 같은 방향을 향하고 있는가를 의미하며, 이는 벡터간의 유사도를 표현하는 척도로 사용될 수 있다.
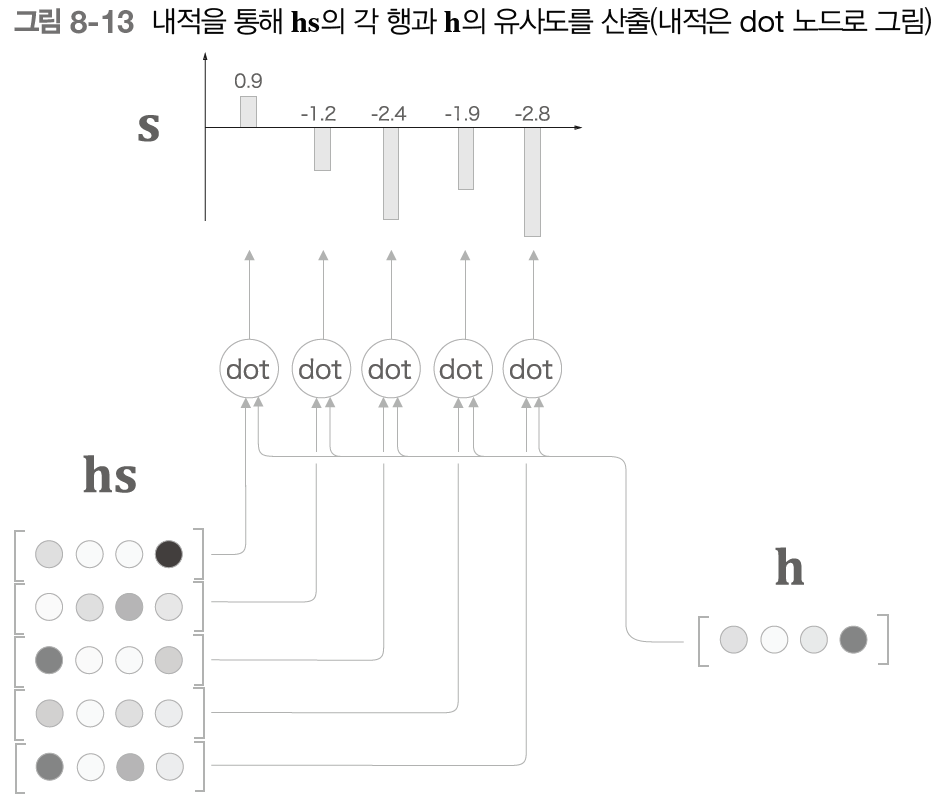
위의 이미지처럼 h와 hs의 내적으로 각 단어 벡터의 유사도를 구한 결과가 s이다. 이 s는 정규화 하기 이전의 값으로, 점수라고도 한다. 이 s를 정규화하기 위해 softmax함수를 적용시켜 나온 결과가 바로 우리가 원하는 가중치 a이다.
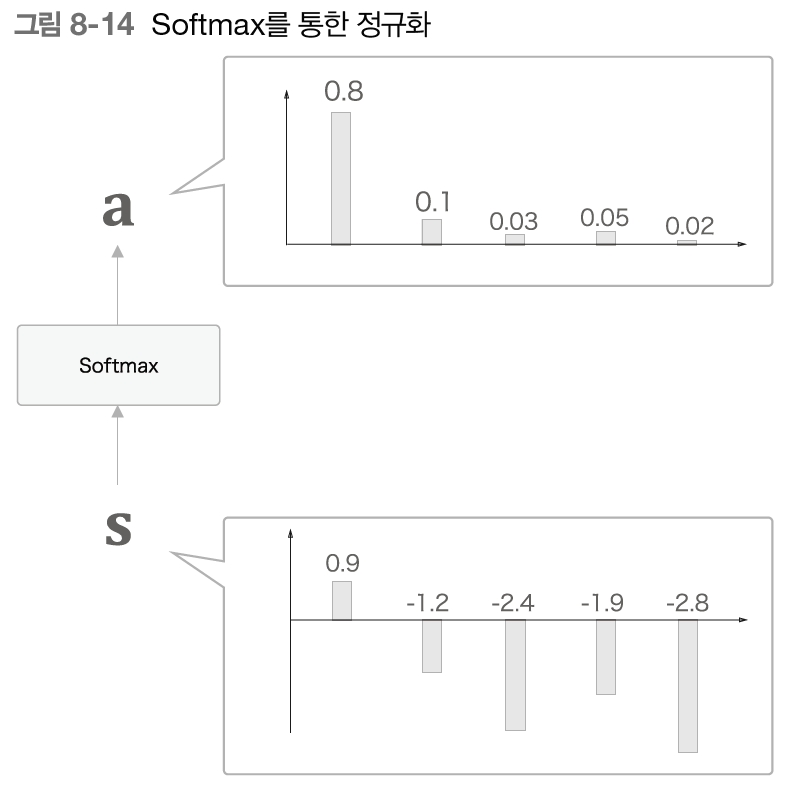
Weight Sum
Weight Sum 계층은 (Attention 계층 안에서도 크게 2가지로 나뉘기 때문에 계층이라고 부르겠다) 모든 은닉 상태 벡터(hs)와 가중치를 나타내는 행렬(a)이 연산(행렬곱)하여 그 결과를 합해 맥락 벡터(c)를 얻어낸다.
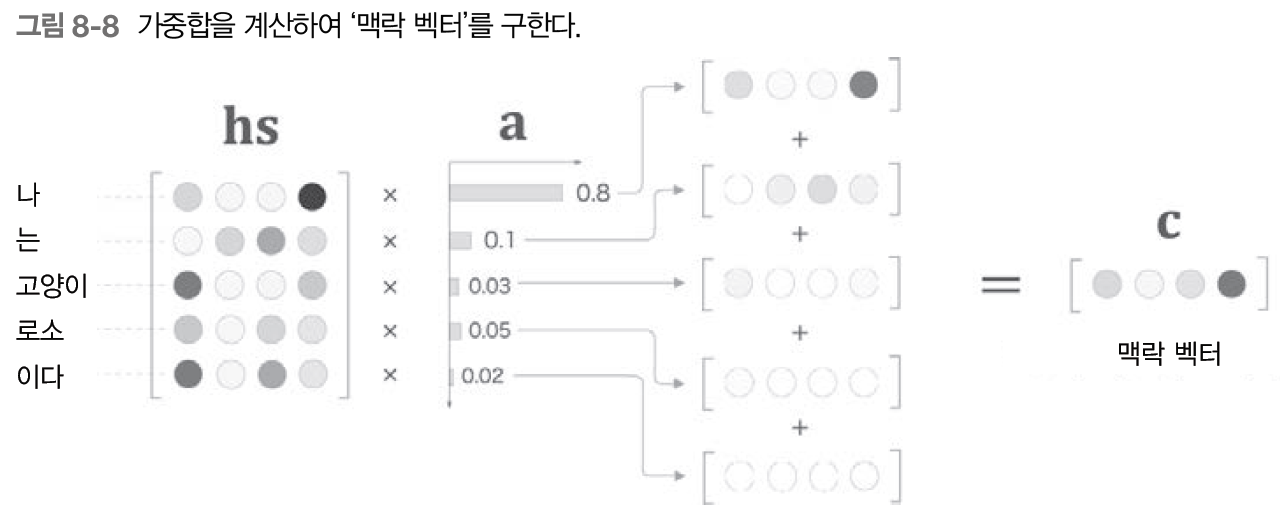
이렇게 어텐션은 두 시계열 데이터 사이의 대응 관계(얼라인먼트:Alignment)를 학습하게 되며, 중요한 정보를 집중적으로 파악할 수 있다. 어텐션에 대해 더 자세히 이해하고 싶다면 이 블로그를 참고하길 바란다.
'인공지능 > 인공지능 이론' 카테고리의 다른 글
| 29. seq2seq (0) | 2020.10.06 |
|---|---|
| 28. LSTM(Long Short-Term Memory) (2) | 2020.10.05 |
| 27. RNN(순환 신경망) (0) | 2020.10.05 |
| 26. 자연어 처리 2) 단어의 분산 표현 얻는 방법 - 추론 기반 기법(word2vec) (0) | 2020.10.04 |
| 25. 자연어 처리 1) 단어의 의미 이해시키기(단어의 분산 표현 얻는 방법) (0) | 2020.09.28 |