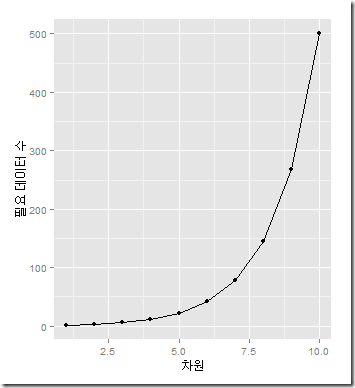
우리는 데이터가 많으면 많을수록 더 좋은 학습 모델을 만들 수 있다고 얘기했다. 반대로 데이터가 적을 경우, 그 데이터를 늘리기 위해 여러가지 방법들에 대해서도 이야기했다. 하지만 데이터가 적음에도 불구하고 용량이 큰 경우에 대해서는 이야기하지 않았다. 지금부터 그러한 경우에 대해서 얘기해보고자 한다. 데이터가 적은데 용량이 크다니 이게 무슨 어불성설인가! 이 말은 즉슨 데이터량은 적지만 각각의 데이터에 할당된 정보량, 즉 차원(Dimension)이 많은 경우를 뜻한다. 쉽게 이해하기 어려우니 예를 들자면 대표적으로 이미지를 들 수 있겠다. 우리가 다루는 이미지는 대부분 픽셀로 이루어져있다. 픽셀이 많을수록 고해상도이다. 하지만 이미지는 단 하나이다. 이런 경우가 차원이 많은 경우라고 볼 수 있다. 데이터(그림)는 하나이지만, 그 안에 있는 차원(픽셀)이 많은 경우 우리는 학습을 하는데 어려움을 겪게 되고 많은 데이터를 필요로 한다. 이러한 것을 Curse Of Dimensionality(차원의 저주)라고 한다.
차원이 커질수록 필요한 데이터도 많아진다.
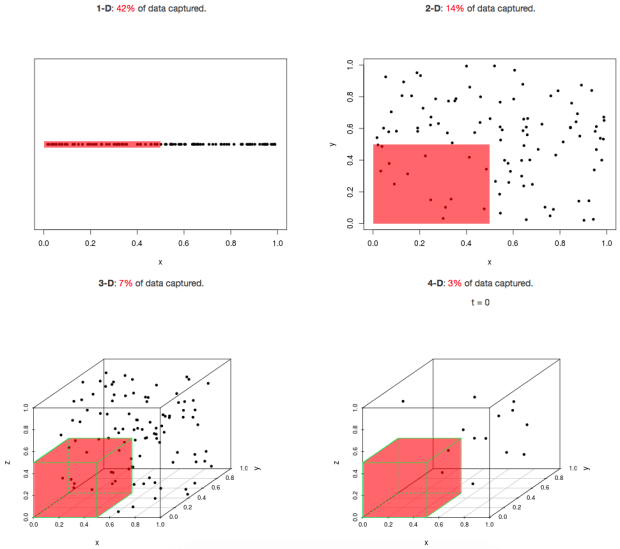
이러한 경우는 우리가 여태까지 공부해왔던 것처럼 직관이 성립하지 않으며 차원이 적으면 데이터들이 가깝게 뭉쳐있지만 차원이 크면 데이터들간의 거리가 커지면서 전체 공간에서 데이터가 차지하는 공간이 적어진다. 데이터가 차지하는 공간이 적어진다는 것은 새롭게 예측한 데이터도 훈련에 사용한 데이터와 멀리 떨어져 있을 가능성이 높다는 것을 뜻하고 예측모델을 만들기 위해 훨씬 더 많은 작업을 해야하지만 저차원보다 예측 결과가 좋지 못할 가능성이 높아진다.
차원이 커질수록 데이터가 차지하는 공간이 적어진다.
우리는 어떻게 차원의 저주에서 벗어날 수 있을까? 우선 첫째로 데이터의 양을 늘리는 방법이 있겠다. 하지만 데이터의 양을 늘리는 것도 어느정도의 한계가 존재한다. 그렇다면 어떻게 해야할까? 그 방법으로 바로 차원 축소가 있다.
Dimensionality Reduction (차원 축소)
차원 축소는 말 그대로 차원 축소이다. 어떻게 차원 축소가 차원의 저주에서 벗어날 수 있는걸까? 당연스럽게 느껴지지만 정확한 이유에 대해서는 잘 모르겠다. 이에 대한 이해를 돕기 위해 우리는 다양한 동물 중 고양이에 대해 분류하는 모델을 만드려고 한다고 가정해보자. 우리가 학습을 위해 수집한 데이터들은 다양한 픽셀(차원)의 고양이 이미지로 구성되어 있을 것이다. 또, 고양이는 먼치킨, 코숏, 아메리칸 숏헤어, 샴 등 다양한 종류의 고양이가 존재할 것이다. 이런 다양한 이미지의 전체 픽셀(차원)을 고려하여 학습하는 것은 굉장히 까다롭고 어려울 것이다. 하지만 자세히 보면 고양이를 특정 짓는 것은 일정하다. 고양이의 눈, 코, 입이 가장 대표적인 고양이의 특징일 것이다. 또한 이러한 고양이의 특징을 파악할 수 있는 픽셀(차원) 또한 한정되어있다. 이러한 경우 우리는 일정 픽셀(차원)에 대해서만 학습해도 충분히 우리가 원하는 모델을 만들어 낼 수 있다. 이러한 경우처럼 전체 차원인 관찰 공간(Observation Space)이 아닌 유의미한 특정 차원인 잠재 공간(Latent Space)에 대해서만 학습하여 원하는 모델을 만들어내기 위해 차원 축소를 사용한다.
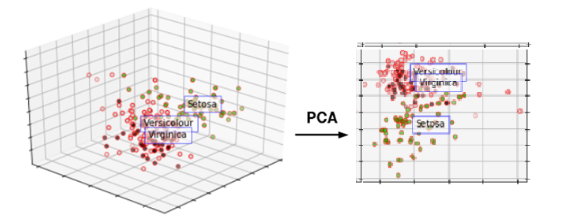
주성분 분석은 말 그대로 전체 차원에서 가장 주요한 성분을 순서대로 추출하는 기법을 말한다. 여러 변수의 값을 합쳐서 그 보다 적은 수의 주요 성분을 새로운 변수로 하여 데이터를 표현하기 때문에 차원을 축소할 때 사용할 수 있는 기법이다. PCA에 대해 친절하고 자세히 설명해주는 유튜브 영상을 첨부하겠다. 또 이 유튜브 영상에 대해 자세히 설명해주는 블로그 또한 첨부하겠다.
가장 폭 넓은, 즉 분산이 가장 크게 되는 축은 데이터를 가장 폭 넓게 설명할 수 있다. 따라서 분산이 가장 큰 축을 제 1주성분이라고 한다. 이처럼 분산의 정도에 따라 차등적으로 주성분을 만들어나가는데, 몇까지의 주성분을 사용하는지에 대해서는 맨 위의 PCA를 누르면 참고할 수 있는 블로그를 참고하길 바란다.
ROC(Receiver Operating Characteristic) Curve는 모든 분류 임계값에서 분류 모델의 성능을 보여주는 그래프로 x축이 FPR(1-특이도), y축이 TPR(민감도)인 그래프이다. 즉 민감도와 특이도의 관계를 표현한 그래프이다. ROC Curve는 AUC(Area Under Curve : 그래프 아래의 면적)를 이용해 모델의 성능을 평가한다. AUC가 클수록 정확히 분류함을 뜻한다. 즉, 위의 그래프에서 A = 0.95인 모델은 95%의 확률로 제대로 분류하고 있음을 뜻한다. 그렇다면 ROC Curve의 x축과 y축을 담당하는 FPR과 TPR이란 무엇일까?
앞으로 기술하는 내용에 대해 더 자세한 내용은 이 블로그를 참고하기를 바란다. 상당히 친절하게 설명되어있다.
위의 표에서 Pr(e) : 2명의 평가자들의 데이터로부터 계산된 확률적 일치, 즉 우연히 일치할 확률을 구해보자.
평가자 A(예측)는 합격확률이 0.6, 불합격확률이 0.4이다.
평가자 B(실제)는 합격확률이 0.5, 불합격확률이 0.5이다.
평가자 A와 B 모두 합격을 줄 확률은 0.6 * 0.4 = 0.3 이며, 평가자 A와 B 모두 불합격을 줄 확률은 0.4 * 0.5 = 0.2 로,
Pr(e) = 0.3 + 0.2 = 0.5이다.
위의 예시표에 대한 카파 통계량은 (0.7(정확도) - 0.5) / (1 - 0.5) = 0.4로 그리 많이 일치하진 않다는 것을 알 수 있다.
카파 통계량이 크면 클수록 모델의 정확도가 우연히 나온 것이 아니라는 것을 알 수 있다.
이것을 이원교차표에 대해서 계산을 하고자 하면 Predicted class의 Positive와 Actual class의 Positive를 곱한 것과 Predicted class의 Negative와 Actual class의 Negative를 곱한 것의 합이 Pr(e)이다.
∴ Pr(e) = Predicted class Positive * Acutal class Positive + Predicted class Negative * Actual class Negative
PR Curve
PR Curve란 x축을 Recall, y축을 Precision으로 두고 시각화한 그래프로 ROC Curve와 마찬가지로 AUC로 평가한다. 주로 데이터 라벨의 분포가 심하게 불균등한 경우, 예를 들면 사람들에게 떡을 2개 주도록 설계된 기계를 상용화하기 위해 테스트할 때 떡을 그 이상이나 이하로 줄 확률보다 설계대로 2개만 줄 확률이 압도적으로 더 높은 (이게 올바른 예시인지는 잘 모르겠다 아 떡먹고 싶네 갑자기) 경우와 같이, 분류의 분포가 심하게 치우쳐진 경우에 사용한다.
출처 : https://m.blog.naver.com/sw4r/221681933731
PR Curve는 ROC Curve와 다르게 1에서부터 줄어드는 형태를 띄고 있다. PR Curve는 불균형한 데이터 셋을 가졌을 때의 핵심 성능평가 방법이다.
F1 점수 (F 척도)
F1 Score는 아래의 그림과 같이 모델의 성능을 하나의 수로 표현하고자 할 때, ROC 곡선이나 PR 곡선의 AUC 외에 많이 사용되는 지표이다.(0~1사이) F1 Score도 정밀도(Precision)와 재현율(Recall)을 이용한다. F1 Score는 모델의 성능을 하나의 숫자로 설명하기 때문에 여러 모델을 나란히 비교할 수 있다.
F1 Score는 정밀도와 재현율의 조화평균으로, 일반적인 산술평균이 아닌 조화평균을 사용하는 이유는 두 지표를 모두 균형있게 반영하여 모델의 성능을 판단하기 위함이다. 조화평균으로 평균을 구하면 작은값을 위주로 평균을 구할 수 있기 때문에 보다 정확한 평균값을 구할 수 있다.
정확도가 만약 높더라도 F1 Score가 현저히 작은 경우는 좋은 모델이라고 볼 수 없기 때문에 F1 Score도 모델의 성능을 파악하는데 중요한 지표라고 할 수 있다. 이에 대한 자세한 설명은 여기를 참고하길 바란다.
F1 Score도 Python과 R(install.packages("MLmetrics"))에 있는 패키지들을 통해 한번에 구할 수 있다.
F1 Score 계산 방법
정밀도(P)와 재현율(R)로 산술평균(Average) 낸 것과 조화평균(F1 Score) 낸 것의 차이를 보여주는 표
Regression(회귀)이 결과값을 추정하는 방식이었다면, Classification(분류)은 카테고리에 분류하는 방식이다.
Classification에서 Linear Regression은 사용할 수 없다. 왜냐하면 Classification은 0 또는 1값만 가지는데, linear regression은 그 범위 이상의 값을 가질 수 있기 때문이다. 따라서 Linear Regression을 Classification에서 사용하기 위해서는 0 또는 1 사이의 값만 내보내는 Hypothesis 함수가 필요하다.
위의 그림에서 왼쪽에 위치한 선형 회귀의 그래프를 보자. 그래프의 y축은 -4 ~ 4 까지 분포되어 있는 것을 알 수 있다. 이런 경우는 앞서 공부했던 Regression으로는 풀리지만 0과 1만을 나타내는 Classification에서는 적용되지 못한다. 왜냐하면 y값이 선형적인 값으로 -4 ~ 4 까지 분포하고 있으니까 말이다. 이런 Regression의 한계점을 해결하여 Classification에서도 문제를 풀기 위해서 우리는 Logistic Regression을 사용한다. (똑똑한 인간들 덕에 이만큼 발달된 사회에서 산다지만 내가 밥 벌어먹으려고 공부하다보니 드는 생각은 똑똑한 것들 다 없어졌으면) 오른쪽 그래프를 보자. Logistic Regression은 y값이 0 ~ 1 까지 밖에 없다. 그 사이에 있는 값들은 일정한 기준을 통해 0 또는 1로 구분할 수 있을 것이고 그렇게 되면 우리는 Regression을 Classification에 적용하여 풀 수 있게 될 것이다.
Linear Regression을 Logistic Regression으로 바꿔주기 위해 우리는 Sigmoid Function을 사용한다.
Sigmoid(Logistic) Function
𝑃(𝑦=1|𝑥;𝜃) +𝑃(𝑦=0|𝑥;𝜃) = 1
여기서 만들어진 함수는 1번 class일 확률과 0번 class 일 확률의 합이 항상 1이 되어야 한다.
Cost Function (비용 함수)
우리는 Linear Regression을 Classification에서도 활용하도록 Sigmoid Function을 사용하여 Logistic Regression으로 바꿨다. 그렇기 때문에 우리가 예측한 데이터가 실제 데이터와 얼마나 유사한지에 대해 판단하는 Cost Function 식도 바꿔야 한다. 왜 바꿔야할까?귀찮아죽겠는데
Linear Regression의 Cost Function을 사용하는 경우 / Non-convex Fucniton
기존의 Linear Regression의 Cost Function을 Logistic Regression에 사용하는 경우는 위의 이미지와 같은 문제가 발생한다.
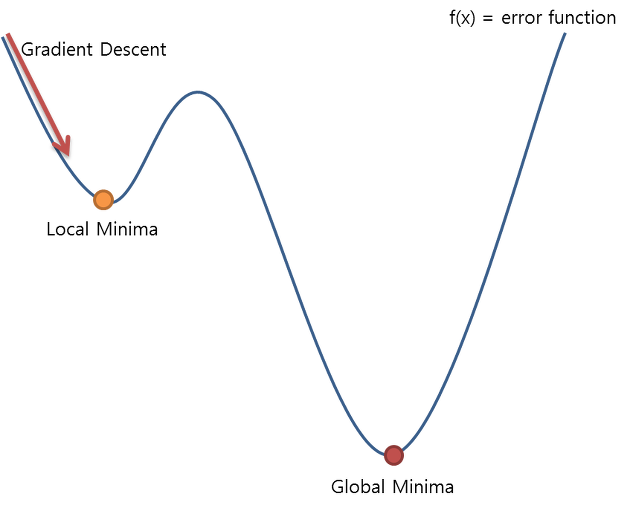
(Local Minima(모델과 데이터에 따라 경사도가 0인 지점이 여러 개 존재할 수 있는 문제)가 생기는 문제)
왜 Local Minima가 생길까? 그 이유는 로지스틱 회귀에서 사용하는 sigmoid가 비선형 함수이기 때문에 Non-convex Function이 되기 때문이다.
위의 그림에서 볼 수 있다시피 가장 최소값 이전에 구간의 최소값이 존재하므로 우리의멍청한컴퓨터는 가장 최소값(Global Minima)을 찾기도 전의 최소값(Local Minima)을 그 함수의 가장 최소값으로 판단할 것이다. 따라서 기존의 Cost Function은 모델의 정확성을 판단하는데 어려움이 있다.
Logistic Regression의 Cost Function
Logistic Regression의 Cost Function은 위와 같다. 빨간색 선은 y=0, 즉 실제 데이터가 0일 때의 그래프이다. x축인 h(x)는 Logistic Regression을 통해 우리가 예측한 값으로 예측값인 h(x)가 실제 데이터의 값인 0과 일치하면 Cost는 0이고, 그와 반대로 예측값을 1로 잘못 예측할 경우 Cost가 기하급수적으로 증가한다. 이는 잘못 예측한 값에 대해 패널티를 주는 개념으로 모델의 예측 정도를 판단하는데 도움이 된다. 파란색 선은 y=1, 즉 실제 데이터가 1일 때의 그래프이고 위의 설명과 같게 예측값과 실제 값이 모두 일치하는 1일 경우에는 Cost가 0, 잘못 예측했을 때는 큰 Cost를 주어 모델이 잘못 예측되었음의 지표를 알려주게 된다. 따라서 Logistic Regression의 Cost Function은 모두 convex하다.
Logistic Regression의 경사하강법
Gradient Descent
Gradient Descent에 대해서는 앞에서 공부한 Regression에서 자세히 설명하였으므로 여기서는 수식에 대해서만 적겠다. 어쨌든 Logical Regression도 경사하강법(Gradient Descent)을 사용하여 Cost를 최소화하는 계수를 찾는다는 것이다.
단순히 위의 Logistic Regression과 같은 그래프 모양이 나타난다면 우리는 대부분 0.5를 기준으로 0.5보다 낮은 값은 0으로, 0.5보다 큰 값은 1로 판단할 것이다.
이런 경우는?!
하지만 세상의 모든 일이 그렇듯 우리가 예상했던 것처럼 항상 저렇게 예쁜 모양으로 나타나지는 않는다. 위의 이미지처럼 특이하지만 명확히 구분할 수 있는 모양이 나온다. 이런 경우에 대한 분류는 참고할만한 사이트들의 링크를 거는 것으로 넘어가겠다. 자세히 설명하자니 방대하고, 다른 블로그에서도 충분히 설명을 잘해주셨기 때문이다.
1. SVM (Support Vector Machine : 서포트 백터 머신)
두 범주를 잘 분류하면서마진(margin)이 최대화된초평면(hyperplane)을 찾는 기법으로 기본적으로 선형분류를 한다.
앞선 머신러닝종류에 대한 글에서 Regression에 대한 설명이 너무 간략했다. 이번 글에서는 Regression에 대해 자세하게 설명하고자 한다.
Regression은 분포된 데이터를 방정식(Hypothesis)을 통해 결과의 값을 예측하는 것을 뜻한다.
Linear Regression (선형 회귀)
Linear Regression은 H(x) = Wx + b 로 나타낼 수 있다. H(x)는 우리가 도출하고자하는 예측 값이다. x는 우리가 갖고 있는 데이터들을 의미한다. 수많은, 그리고 다양한 특징을 갖는 데이터들을 하나의 수식으로 나타내는 W와 b의 값을 구하는 것이 Linear Regression의 최종 목표라고 할 수 있겠다. 그렇다면 어떻게 W와 b를 구할 수 있을까?
여기 이미지를 보자. 빨간색 점은 우리가 갖고 있는 데이터이다. 이렇게 다양한 위치에 존재하는 데이터의 전체적인 경향성을 파악하기란 여간 어려운 일이 아니다. 그래서 우리는 이런 다양한 데이터들을 전체적으로 예측할 수 있는 모델을 만들기 위해 갖고 있는 데이터와 예측한 함수에 대한 오차값을 사용한다. 그림에 있는 초록색 선이 예측한 모델과 주어진 데이터간의 오차이다. 우리는 갖고 있는 모든 데이터에 대해 이 오차 값이 제일 적은 모델을 선택해야 원하는 예측값을 얻을 수 있을 것이다.
Cost Function (비용 함수)
Cost Function, 이 그림에서 𝜃0은 b, 𝜃1은 W를 의미한다.
오차는 예측값( h(x) )과 정답( y )의 차이이다. 단순한 차는 양수와 음수를 모두 포함하므로 지표적으로 해석하기 쉽게하기 위해서는 제곱하는 것이 편하다. 따라서 우리는 오차값을 제곱하여 합산한다. 분모에 있는 2m의 m은 데이터의 개수이다. (+ 2로 나누는 것은 미분값(Gradient)을 간소하게 만들기 위해 추가한 것) 위와 같은 식을 우리는 Cost Function(비용 함수)이라고 한다. Cost Function의 값이 낮을수록 좋은 선형방정식이라고 할 수 있다.
convex(볼록함수)를 통해 최소값을 쉽게 찾을 수 있다.
위의 이미지와 같이 쉽다면 인공지능이 얼마나 재미있을까? 하지만 저렇게 쉬운 문제만 있다면 애초에 인공지능까지도 필요 없었을 것이다. 그냥 대충 계산하면 사람도 쉽게 할 수 있으니 말이다. 우리는 대체로 이런 말도 안되는 그래프들을 만나게 될 것이다.
벌써부터 가슴이 답답하다.
최하점을 찾기 꽤나 까다로운 그래프가 아닐 수 없다. 우리는 현재 빨간색 쪽에 있는 별에 위치해 있다. 우리는 제일 최저점인 짙은 파란색에 있는 값들을 알아내야 한다. 그렇다면 어떻게 해야 우리는 저 최저점에 도달할 수 있을까? 이를 위해 우리는 Gradient Descent(경사 하강법)를 사용한다.
Gradient Descent (경사 하강법)
Gradient Descent (경사 하강법)은 1차 근삿값 발견용 최적화 알고리즘이다.
기본 개념은 함수의 기울기(경사)를 구하여 기울기가 낮은 쪽으로 계속 이동시켜서 극값에 이를 때까지 반복시키는 것이다. 즉, Gradient Descent란 Cost를 최소로 만드는 예측직선 h(x)에서 최적의 W를 발견하는 과정이라고 할 수 있다.
수식 극혐
𝛼 : learning rate, 𝛼 > 0
≔ : 할당 (assignment) 연산자
𝜃0, 𝜃1은 한번에 업데이트 해야 함
위의 수식은 Cost Function(비용함수)의 편미분값 * 𝛼값을 기존 𝜃값에서 빼주는 것을 계속 반복하는 방식이다. 이걸 단번에 이해하는 당신은 천재라고 할 수 있겠다. (왜나면 내가 바보이기 싫기 때문) 이해를 돕기 위해 선형 회귀에 대해 잘 설명한 블로그에서 갖고 온 이미지를 보자.
비교적 이해하기 쉬운 이미지라고 생각한다.
위의 이미지를 보면서 다시 수식에 대해 이야기 해보자. Cost Function(비용함수)의 편미분값은 그 지점의 접선 기울기와 같다. Gradient Descent 방법대로 기울기에 𝛼값을 곱한 값을 기존 𝜃값에 빼주면 그래프는 최적점과 조금 더 가까워지게 된다. 이 방법을 여러번 반복하면서 우리가 원하는 최저점을 찾아가는 것이 Gradient Descent라고 할 수 있겠다. 여기서 𝛼값은 어떻게 조정해야할까?
Learning Rate (𝛼)
𝛼, 즉 Learning Rate의 값이 너무 크거나, 너무 작다면 어떤 현상이 발생할까? 이를 잘 설명해주는 이미지가 있다.
내가 이해하는 영어라면 여러분도 이해할 수 있다.
𝛼값이 너무 작은 경우는 천천히 수렴하므로 수렴하기까지의 시간이 너무 오래걸린다.
𝛼값이 너무 큰 경우는 제대로 최저점을 찾지 못할 확률이 높으며 수렴하지 못한다.
𝛼값은 𝐽(𝜃)의 변화 값이 일정 수준이상 작아지면 수렴으로 판정되기 때문에 우선 작은 값으로 시작하여 큰 값으로 늘려나가는 것이 바람직하다고 볼 수 있다.
우리는 𝛼값을 Hyper Parameter(초매개변수)라고 한다. Hyper Parameter는 사람이 직접 설정해야 하고, Parameter는 훈련데이터와 학습 알고리즘을 통해 모델 내부에서 결정되는 변수를 의미한다. 이에 대한 자세한 설명을 여기를 참고하길 바란다.
최선의 Linear Regression
위의 이미지는 여태껏 설명했던 내용을 토대로 만들어진 Linear Regression이다. 이 모델은 모든 데이터에 대해 최선으로 오차가 적은, 즉 오류가 적은 함수로 우리가 원하는 예측값을 얻을 수 있다.
다중공선성에 대해 잘 설명한 블로그 링크를 걸어두었다. 블로그가 워낙 설명을 잘해주었기 때문에 링크를 타고 들어가 설명을 읽으면 되겠다. 다중공선성의 내용을 간단하게 요약하자면 다음과 같다.
다중 회귀식
α : 회귀계수
X : 독립변수(설명변수)
Y : 종속변수(반응변수)
ε : 오차항
위의 다중회귀식을 보자. 우리는 데이터에 해당하는 X1과 X2가 각각 독립이라는 가정하에 다중회귀식을 구현한다. 두 독립변수가 서로 독립적이어야 회귀식을 제대로 표현할 수 있기 때문이다. 하지만 내 마음과 같지 않게두 독립변수가 독립변수가 아니라 서로에게 영향을 주고 있는 경우가 생긴다. 이런 경우에 다중공선성이 있다고 한다. 이에 대한 자세한 설명은 다음을 눌러 더 자세히 확인하길 바란다. 결론적으로는 다중공선성이 있는 경우 서로 영향을 주는 두 컬럼 중 하나를 삭제하여 회귀식을 구성해야 우리가 원하는 결과를 도출하는 회귀식을 만들 수 있다는 것이다.
지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning)이 그것이다.
여기 머신러닝의 3가지 학습 방법에 대해 간결하며 직관적으로 설명해 주는 블로그가 있다. 참고하길 바란다.
머신러닝 종류
Supervised Learning (지도 학습)
지도학습과 비지도학습은 과거와 현재의 데이터를 학습하여 미래를 예측한다. 하지만 이 둘의 차이점은 지도학습은 데이터에 대한 답이 정해져 있다는 것이다. 우리가 앞서 공부했던 타이타닉이 지도학습의 일종이라고 할 수 있다. 탑승자의 사망 여부를 알 수 있다는 것은 데이터에 대한 답이 이미 주어져있다는 것으로, 우리는 이러한 데이터를 활용하여 학습하고 예측할 수 있다. (마치 공대생들이 솔루션이 있는 상태에서 공부하는 것과 같다. 처음 보면 엥 ㅁㅊ 이게 뭐야 싶은 것도 솔루션과 함께라면 두렵지 않아. 아님 영어 지문의 정답을 아는 상태에서 지문을 읽으면 맥락과 답을 더 쉽게 유추 할 수 있는 것과 같다고 할 수 있겠다.) 지도학습에는 크게 Regression과 Classification으로 나뉜다.
-Regression (회귀)
Regression이란 연속된 값을 예측하는 문제를 뜻한다. 주로 경향성(패턴, 트렌드, 추세)을 예측할 때 사용된다. 주식같은 것도 학습시킬 수 있는 것 같지만 너무 어려워서 다들 다루지 않는 것 같다. Regression을 주로 사용하는 경우는 공부시간에 따른 성적을 예측하는 것과 나이에 따라 연봉의 추이정도와 같이 선형적인 경우이다.
-Classification (분류)
Classification은 주어진 데이터를 정해진 카테고리에 따라 분류하는 방법이다. 가장 쉬운 예로 패논패 과목이 있겠다. 일정 수준을 넘기면 Pass인 과목은 통과했는가, 하지 못했는가로 구분된다. 이러한 경우처럼 맞다 / 아니다로 구분되는 문제를 Binary Classification이라고 부른다.이런 Binary Classification에 대표적인 예로 스팸 메일 예측을 들 수 있겠다. 이러한 경우 우리는 메일은 스팸메일과 정상적인 메일로 구분할 것이다. 맞다 / 아니다로 구분하는 것이 아니고 분류가 여러 개로 되는 경우, 예를 들자면 학점을 예측하는 경우는 A,B,C,D,F 총 5개로 분류하여 예측하기 때문에 이렇게 분류가 여러 개로 되는 경우는 Multi Label Classification이라고 한다.
Unsupervised Learning (비지도학습)
비지도학습은 지도학습과 달리 답이 없는 데이터로부터 미래를 예측하는 방법이다. (벌써 노답) 데이터에 답이 없기 때문에 노답데이터를 사용하려는 사람이 직접 데이터 간의 숨겨진 유의미한 패턴 등을 파악해야 하기 때문에 어렵다. 비지도학습도 지도학습과 같이 연속적인지(Continous Data) 분류되어있는지(Categorial Data)를 파악하여 학습할 수 있다. 비지도학습은 크게 Dimensionality Reduction와 Clustering으로 나뉜다.
-Dimensionality Reduction (차원 축소)
차원 축소를 설명하자면 길어지니 비지도학습에 대해 자세히 설명할 때 설명하도록 하겠다. 간단히 말하자면 차원이 커지면 그 차원을 설명하기 위해 너무 많은 데이터가 필요하기 때문에 차원을 줄여 데이터 간의 유의미한 특징만을 추출해 내 학습하는 것을 뜻한다.
-Clustering (군집화)
Cluster(군집)이란 유사한 패턴의 데이터들이 서로 가깝게 모여있어 하나의 무리를 이루고 있는 것을 뜻한다. 이러한 군집들을 유의미한 유사도를 갖는 군집만 남기고 불필요한 군집들을 지워나가는 처리 과정을 Clustering(군집화)라고 한다. 지도학습의 Classification(분류)와 유사하나, Classification(분류)은 답이 있는 데이터들로 학습하는 것이고 군집화(Clustering)는 답이 없는 데이터들을 직접 분류하여 학습하는 방법이라는 것을 기억하자.
지도/비지도 학습에 대해 이해하기 쉽게 구분해놓은 이미지
Reinforce Learning (강화 학습)
강화학습이란 컴퓨터가 어떤 행동을 하면 그에 대한 “보상”을 통해 학습하는 것을 뜻한다.
한 예로, 자동차가 벽에 부딪히지 않고 주어진 트랙을 완주하는 것을 학습시킨다고 하자. 이 때, 우리는 벽에 부딪히지 않고 제일 멀리 간 모델에 가장 큰 보상을 준다고 가정하자. 컴퓨터는 학습을 위해 수십대의 자동차 모델을 트랙에 뿌릴 것이다. 그리고 가장 큰 보상을 준 모델과 유사한 모델들로 계속해서 자동차 모델을 만들 것이다. 이 횟수가 반복함에 따라(세대가 증가함에 따라) 더 나은 모델들이 학습될 것이고 마침내 컴퓨터는 벽에 부딪히지 않고 트랙을 완주하는 모델을 만들 것이다.
자동차를 예로 들었지만 결국에 강화 학습은 사람의 학습 방법, 동물의 학습 방법과 같다. 쉬운 예로 강아지에게 '손'을 외쳤을 때 사람의 손에 손을 올려주는 것을 학습시키려고 한다고 하자. 이를 위해 인간은 끊임없이 강아지에게 '손'을 외치며 강아지의 손을 자신의 손에 올릴 것이다. 처음에 강아지는 그런 인간의 행동이 이해가 가지 않을 것이다. 그러다가 우연의 일치로 강아지가 (학습하고자 하는 방향인) 사람의 손에 손을 올리면 '보상'으로 간식을 줄 것이고, 처음엔 우연이었던 손 올리기는 보상에 의해 차츰 학습되어 강아지가 직접 '손'이라는 단어를 인지하며 사람의 손바닥에 손을 올리게 될 것이다.
이처럼 보상을 통해 원하는 결과를 향해 반복적으로 학습해 나가는 방법을 강화학습이라고 한다.