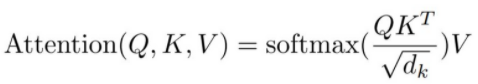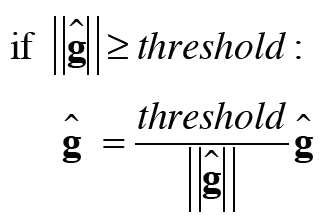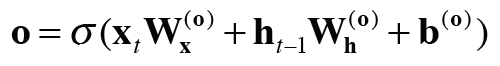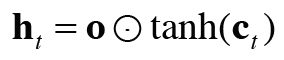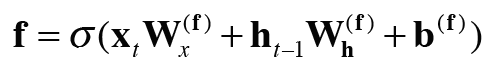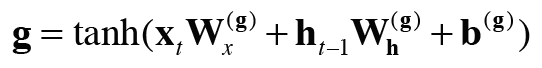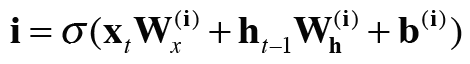알고리즘을 어떻게 공부해야할까 어느 사이트를 참고해야할까 엄청 고민하던 찰나에, 우연히 보게된 글에서 LeetCode로 공부하는게 좋다길래 참고하여 공부하려고 한다! Easy고 나발이고 x밥인 나는 이 사람 말대로 이것도 어려웠다ㅋㅎ,, 괜찮아.. 열심히 하면 늘겠지!
생각해보니까 문제 안올림ㅋㅋㅋ
# 내 코드
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
output = []
for i in range(len(nums)) :
target -= nums[i]
if target in nums[i+1:] :
output.append(i)
output.append(nums[i+1:].index(target)+i+1)
return output
target += nums[i]
return
Runtime , Memory
메모리 사용량은 적지만 시간이 굉장히 오래걸리는 내 코드... Discussion에 올라와있는 코드들은 딕셔너리를 사용하여 효과적으로 속도를 향상시킬 수 있었다.
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
dic = {}
for i, n in enumerate(nums):
if n in dic:
return [dic[n], i]
dic[target-n] = i
Runtime, Memory
근데 또 Discussion에서 나온 의견으로는 nums = [11, 2, 2, 7, 11, 15] , target = 9 일 때, 정답은 [1,3]인데 위의 코드로 하면 [2,3]이 나오는 오류가 발생한다... 근데 내코드는 잘 됨 헤헷 속도를 잃고 정확성을 얻었다 암튼 코딩 하수인 나는 리스트도 enumerate가 된다는 새로운 사실을 알았으니 그것만으로도 만족 헤헷,,, 그리고 딕셔너리 사용이 속도면에서 효과적이라는 것을 알았으니 이것도 만족 헤헷...
이 논문은 8명의 리서처가 만든 모델이다. (2차 면접 때 공부해오라고 하셨던 논문이었는데 ppt 만들면서 이걸 언급하니까 굳이 왜 넣으냐고 하셨음ㅋㅋㅋㅋ 내가 생각해도 그렇긴한데ㅋㅋㅎ,, 그냥 말문 트려고 여기서도 또 넣는다 ㅎㅋ) 2017년 12월 6일에 나온 논문으로 굉장히 유명한 논문이다. 대략적으로 말하자면 이 논문은 기존의 RNN 모델의 단점을 보완하고자 Attention만을 활용하여 만든 모델 구조라고 보면 되겠다. 그렇다면 더 자세히 보도록 하자.
RNN 구조의 문제점
Recurrent Neural Network
RNN은 Recurrent Neural Network의 약자로 순환신경망이라는 뜻이다. RNN의 나름 자세한 설명은 여기를 참고하길 바란다. 여기서는 논문 이야기만으로도 빡빡하니 대략적으로 RNN에 대해 설명하고 넘어가도록 하겠다. 우리는 왜 RNN을 사용하는가? 그 이유는 시계열 데이터를 예측하기 위해서이다. 대표적인 시계열 데이터로는 자연어가 있겠다.
나는 방금 밥을 먹었다. 그래서 지금 나는 배가 ( ).
여기서 괄호 안에 들어올 말을 예측하기 위해서는 앞의 데이터에 대한 정보도 함께 갖고 있어야 한다. 나는 방금 밥을 먹었기 때문에 지금은 배가 고프지 않을것이다. 따라서 괄호 안에는 '고프지 않다'가 들어가는 것이 맞다고 볼 수 있겠다. 이렇게 문맥을 파악해야만 단어를 유추할 수 있는 자연어를 처리하기 위해 우리는 RNN, 즉 순환신경망을 사용한다. RNN은 데이터의 입력 순서를 기억하며 맥락을 파악하고 원하는 위치에 나오는 문장을 예측한다.
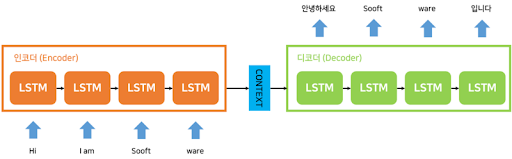
seq2seq 구조
위의 이미지는 RNN 종류 중 하나인 LSTM으로 구성된 seq2seq 구조를 보여준다. 자, 그러면 이제 본론으로 들어가 RNN의 문제점이 무엇인지 보도록 하자. 위의 이미지를 보면 Hi I am Sooft ware 가 Encoding 층의 입력 데이터로 주어지고 이것을 인코더의 LSTM이 잘 기억하고 학습하여 Decoder의 LSTM으로 전달하며 Decoder는 안녕하세요 Sooft ware 입니다 라는 문장을 출력한다. 이 구조에서 문장 길이에 비례하는 만큼의 (혹은 비례하는 만큼의 크기인 매개변수) LSTM이 필요하다는 것을 볼 수 있고 LSTM이 순차적으로 정보를 입력받고 넘겨주는 것을 볼 수 있을 것이다.
Encoder의 입력 데이터가 Hi I am Sooft ware 로 짧아서 다행이지, 만약 The animal didn't cross the street because it was too tired 와 같이 긴 문장에서 it이 가르키는 것이 무엇인지 seq2seq 구조의 모델은 이해할 수 있을까?
이와 같이 학습되는(입력되는) 문장이 길어지면 길어질수록 서로 멀리 떨어진 문장에 대한 정보가 줄어들면서 제대로된 예측을 할 수 없는 것을 Long-term dependency problem 이라고 한다.
또한 순차적으로 연산을 하다보니 병렬화가 불가능하여 연산 속도가 저하된다는 단점 또한 존재한다. 컴퓨터는 고도로 병렬 연산에 최적화되어있기 때문에 병렬 연산을 하지 못한다는 것은 아주 큰 손해이다.
다시 한번 정리하자면 결국 기존 RNN 구조는 Long-term dependency problem과 병렬 연산 불가능으로 인한 연산 속도 저하의 문제점이 있다고 볼 수 있다.
위의 RNN의 단점을 보완하고자 기존의 seq2seq 구조에서 오직 Attention만을 사용하는 것을 바로 Transformer라고 하며 논문에서 설명하고 있는 모델의 구조가 바로 Transformer를 의미한다. Attention에 대한 자세한 내용은 여기를 참고하길 바란다. 결론적으로 Attention이란, 단어의 전체적인 정보를 저장하는 것이라고 이해하면 된다. (너무 간략하기 짝이 없으니 꼭 더 찾아보길 바란다.)
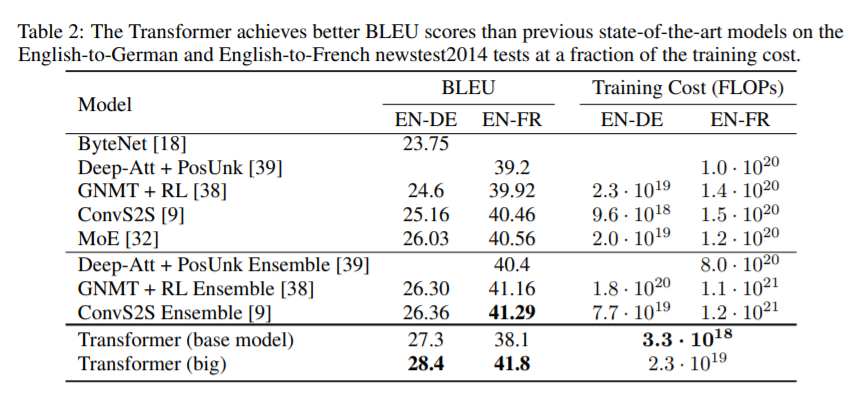
Transformer가 얼마나 성능이 좋은지를 나타내는 그래프 (논문에 있음)
위의 그래프는 모델 별 BLEU score와 Training Cost를 보여준다. 결론적으로 Transformer는 다른 Model들에 비해 Training Cost도 적으면서 높은 BLEU 점수를 받았다는 것을 자랑 보여주는 것이다. 이렇게 완벽하고 멋진 Transformer의 구조에 대해 이제 자세히 알아보도록 하자.
Transformer 구조
논문 순서와는 약간 다르게 나는 모델의 입력 데이터부터 순차적으로 올라가도록 하겠다.
Input(Embedding & Positional Encoding)
Input 데이터는 수백만개의 문장 데이터이다. 이 문장 데이터를 어떻게 컴퓨터가 이해할 수 있을까? 컴퓨터는 최강 공돌이 공순이라서 숫자밖에 모르는 바보인데 말이다. 그래서 우리는 바보한테 맞춰줘야 한다. 우리는 문자인 단어를 숫자로 변경한다. 그 과정을 Embedding이라고 한다. Embedding을 통해 우리는 문자인 단어들을 각각 잘 나타낼 수 있는 숫자로 변경한다. 그리고 숫자로 변환된 데이터(벡터 형태이다)를 입력 데이터로 준다. 여기서 Transformer의 단점을 보완해주고자 Positional Encoding이라는 계층을 지나게 된다.
Transformer는 RNN의 단점을 해결하고자 나온 모델로, 결론적으로 말하자면 병렬 계산이 가능하다. 따라서 단어들이 순차적으로 들어오지 않고 뭉태기로 들어와도 단어들의 순서를 이해하면서도 병렬적으로 연산이 가능하다. 이것이 가능하게 하는 것을 Positional Encoding 계층이다. 사실 벡터(뭉태기)로 들어오는 단어들에 대한 위치정보는 알 수 없다. 그렇기 때문에 기존에 우리가 RNN을 사용했던 이유는 단어간의 순서와 맥락을 파악하기 위해서였다. 하지만 Transformer는 Positional Encoding 계층을 사용하면서 뭉태기(벡터)의 단어 데이터들에 상대적인 위치 데이터를 제공하며 병렬연산을 가능하게 한다.
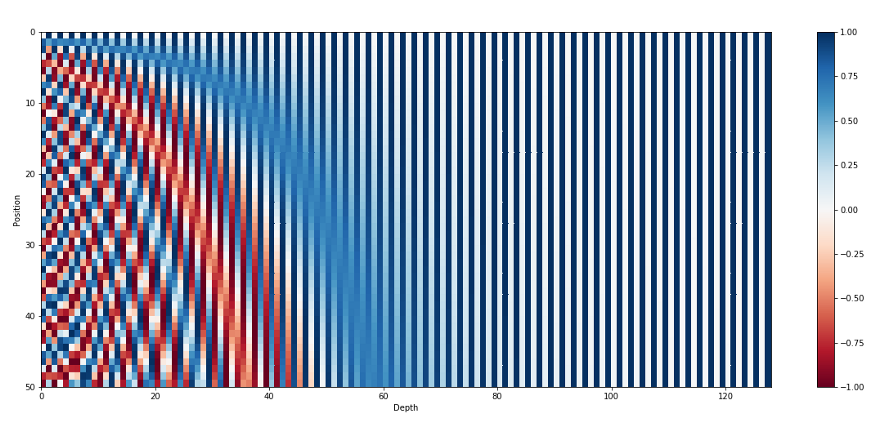
사실 이 부분에 대해서 수학적인 부분은 명확히 이해를 하지 못했기 때문에(ㅎ) 대충 느낌적으로만 설명하면 결국에 sin, cos인 정현파는 -1~1사이의 값을 갖고 서로 겹치지 않기 때문에, 이것을 홀수 짝수로 나누어 연산을 하고 기존의 Embedding과 단순히 합산을 하면 위의 이미지처럼 서로 겹치지 않는, 상대적인 위치 정보를 가진 최종적인 데이터를 만들 수 있게 되고 이것이 Transformer의 Input으로 주어지게 된다. Positional Embedding에 대해 수식적인 이해를 필요로 한다면 여기를 참고하길 바란다.
결론적으로 Input 이전의 과정들은 문자를 숫자로(Embedding) 변경한 뒤, 상대적인 위치 정보를 주입(Positional Encoding)시킨다.
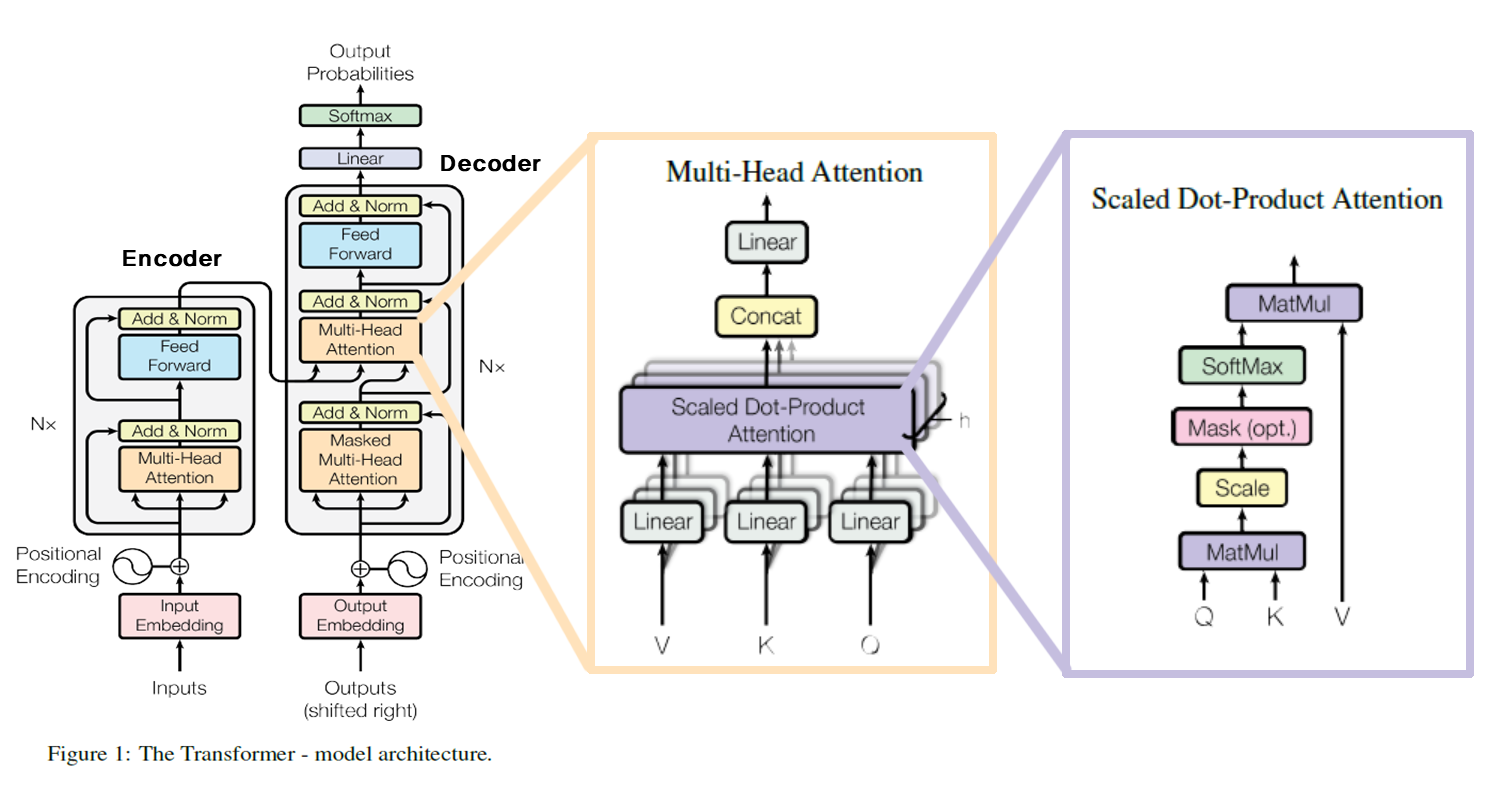
Transformer의 Encoder와 Decoder는 세부 계층으로 Multi-Head Attention과 Feed Forward 구조를 가진 상당히 유사한 모습을 갖고 있다. 따라서 나는 (Masked) Multi-Head Attention에 대해 그리고 그 세부를 구성하는 Scaled Dot-Product Attention에 대해 설명하는 구조로 설명하도록 하겠다.
Scaled Dot-Product Attention (Self-Attention)
Scaled Dot-Product Attention의 구조는 위와 같다. Q,K를 행렬곱 연산을 한 후, 1/sqrt(dk)로 Scaling을 하고, 선택적으로 Mask를 한 후, Softmax를 거쳐 그 값을 V와 다시 한번 행렬곱 연산을 한다. 이에 대한 내용은 수식적으로는 아래의 이미지와 같다. 수식을 이해하기에 앞서서 왜 우리는 1/sqrt(dk)로 Scaling을 하며, 선택적으로 Mask를 사용하는걸까?
1/sqrt(dk)로 Scaling하는 이유는, QK^T 연산을 하게 되면 행렬 크기가 커지게 되면서 벡터가 커지게 된다. 따라서 벡터를 구성하는 숫자의 개수가 여러개가 되기 때문에 Softmax를 적용하면 거의 대부분의 숫자들이 0에 가깝게 된다.(Softmax는 확률을 나타내는 함수이기 때문에 각 행렬의 위치들이 얼만큼의 확률을 나타내는지를 보이기 때문에 행렬이 클수록 모든 데이터들이 0에 가까워질 수 밖에 없다.) 따라서 각 숫자들의 값들의 차이를 극단적으로 나누기 위해 (대부분의 숫자들이 0에 가까운 것을 막기 위해) 1/sqrt(dk)로 Scaling하게 된다.
또 선택적으로 Mask를 하는 이유는, Decoder의 초반 Multi-Head Attention이 Masked Multi-Head Attention을 사용하기 때문인데, 그 이유는 결론적으로 우리는 시계열 데이터를 정확히 예측하고자 하기 때문에 전체 정보를 미리 알려주는 것이 아니라 순차적으로 데이터를 제공하며 유추하기를 원하기 때문에 Mask를 사용하여 순서가 되지 않은 데이터의 정보(Attention)를 숨기는 과정을 거친다. 이렇게 Mask를 사용하는 이유는 Input Data가 벡터로 전체 데이터가 한번에 들어가기 때문이다.
아무튼 다시 Scaled Dot-Product Attention의 수식을 보면 다음과 같다.
여기서 Q, K, V가 뭘까? 풀어 말하자면
Q : 영향을 받을 단어
K : 영향을 주는 단어
V : 영향에 대한 가중치
라고 이해하면 되겠다.
이 Scaled Dot-Product Attention에 대해서는 유튜브를 참고하는 것이 훨씬 빠른데 내가 공부할 때 큰 도움이 되었던 유튜브들을 몇 개 링크 걸도록 할테니 꼭 참고하길 바란다. 이건 강요다.Transformer구조를 이해하기 위해서는 이 Scaled Dot-Product Attention에 대한 이해가 필수적이나 글로 풀어쓰는데는 한계가 존재하기 때문에 링크를 꼭 참고하길 바란다. 유튜브유튜브블로그
아무튼 이 Scaled Dot-Product Attention에 대해 아주 간단히 설명하자면,각각의 단어가 다른 단어들과 얼마나 밀접한 관련이 있는지에 대한 정보까지 모두 담은 구조라고 이해하면 되겠다. 이에 대한 자세한 내용은 위의 유튜브들로 이해하고 블로그로 다시 한번 이해하면 이해가 잘 되리라 믿는다.
그리고 실제 Transformer에서 Q, K, V는 모두 동일하다. Decoder 중간에 위치한 Multi-Head Attention을 제외하고는 모두 Q, K, V가 동일하기 때문에 Self-Attention이라고도 불리고, 이러한 이유 때문에 기재한 영상들이 Q,K,V를 동일한 값으로 계속 설명해주는 것이다. Decoder 중간에 위치한 Multi-Head Attention은 영향을 받을 단어인 Q(구조 이미지에서 Output을 의미, 한글로 말하자면 Decoder에 입력되는 단어 벡터를 의미한다.)를 제외하고 Encoder의 Output이 K와 V로 입력된다.
Self-Attention을 사용하는 이유는 논문에 기재되어있는데, 결론적으로 연산량이 적고 속도가 빠르다는 장점이 있기 때문에 Self-Attention을 사용한다는 이야기이다. 여기에 대해 더 자세한 내용은 여기와 여기를 참고하길 바란다.
Self-Attention을 사용하는 이유
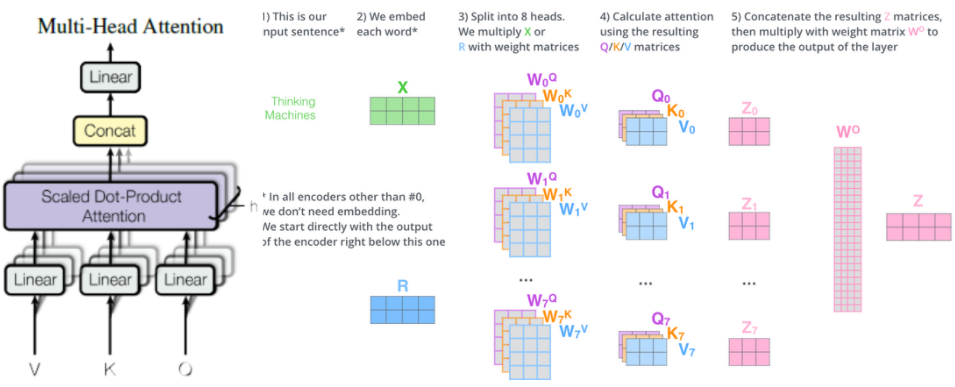
Multi-Head Attention
Multi-Head Attention에 앞서 Scaled Dot-Product Attention을 설명한 것은 Multi-Head Attention의 핵심 구조가 Scaled Dot-Product Attention이었기 때문이다. Multi-Head Attention은 굉장히 간단하다. 입력으로 들어온 V, K, Q를 Linear 계층으로 보낸다. 이 Linear 계층은 Pytorch 기준이고 Keras로는 Dense 계층을 의미한다. 결론적으로 완전연결계층을 의미한다. 완전연결계층이란 가중치와 편향을 연산하는 계층이다. 위의 이미지를 보면 입력 데이터로 단 한개(2X4 Shape)의 데이터가 들어가지만, 여러개의 가중치(위의 이미지에서는 0~7까지 총 8개이다)로 연산을 하면서 데이터가 8개로 쪼개진다. Q0~7, K0~7, V0~7 이런 식으로 말이다. 또한 2X4 Shape과 가중치의 Shape인 4X3이 행렬곱을 하므로 최종적으로 출력되는 데이터의 Shape은 2X3이다. 이것을 Scaled Dot-Product Attention 에 입력하게 되면 연산 과정에 의해 같은 Shape인 2X3이 나오게 되고 이것이 그림에서 나오는 Z0~7이다.
이것들을 Concat한 후(Concat을 하게 되면 2X3 Shape인 데이터들이 가로로 붙으면서 2X24(3*8) Shape이 되고 이를 가중치 W(24X4 Shape)와 연산하면 최종적인 출력 Z(2X4)가 나온다.
내가 굳이굳이 Shape을 쓰는 이유는 이게 내 2차 면접의 주요 내용이었기 때문인데, 실제로 Transformer 구조에서 매우 중요하다. Transformer는 결론적으로 Input Shape과 Output Shape이 2X4로 동일하다.
따라서 Encoder 및 Decoder를 여러개 쌓아도 되기 때문에 효율적으로 코드를 작성할 수 있고 계산할 수 있다.
또 사실 여러개의 Head를 사용하지 않아도 같은 연산 결과가 나오는데, 굳이 Multi-Head를 사용한 이유는 컴퓨터는 병렬 연산 최강자이기 때문에 여러개의 병렬 연산을 동시에 할 수 있어 속도면에서 이득을 취할 수 있기 때문에 같은 결과가 나오면서 속도도 빠르게 계산하고자 Multi-Head를 사용하는 것이다.
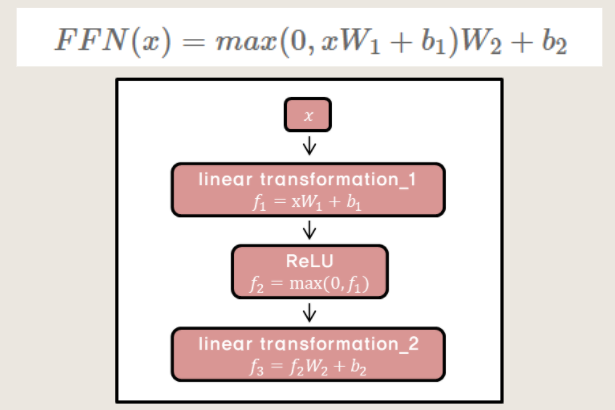
Feed-Forward Network
FFN 구조
Feed-Forward Network 구조는 별거 없다. 다시 한번 완전 연결 계층을 지난 후, ReLU 계층을 지나고 또 완전 연결 계층을 지나는 구조이다.
Add&Norm
Multi-Head Attention 구조 이후, Feed-Forward 구조 이후 Add&Norm 계층은 ResNet과 같이 이전 데이터를 단순 합산(Add)하며 기존의 데이터에 대한 정보를 잃지 않고 Normalization, 정규화를 하는 계층이다.
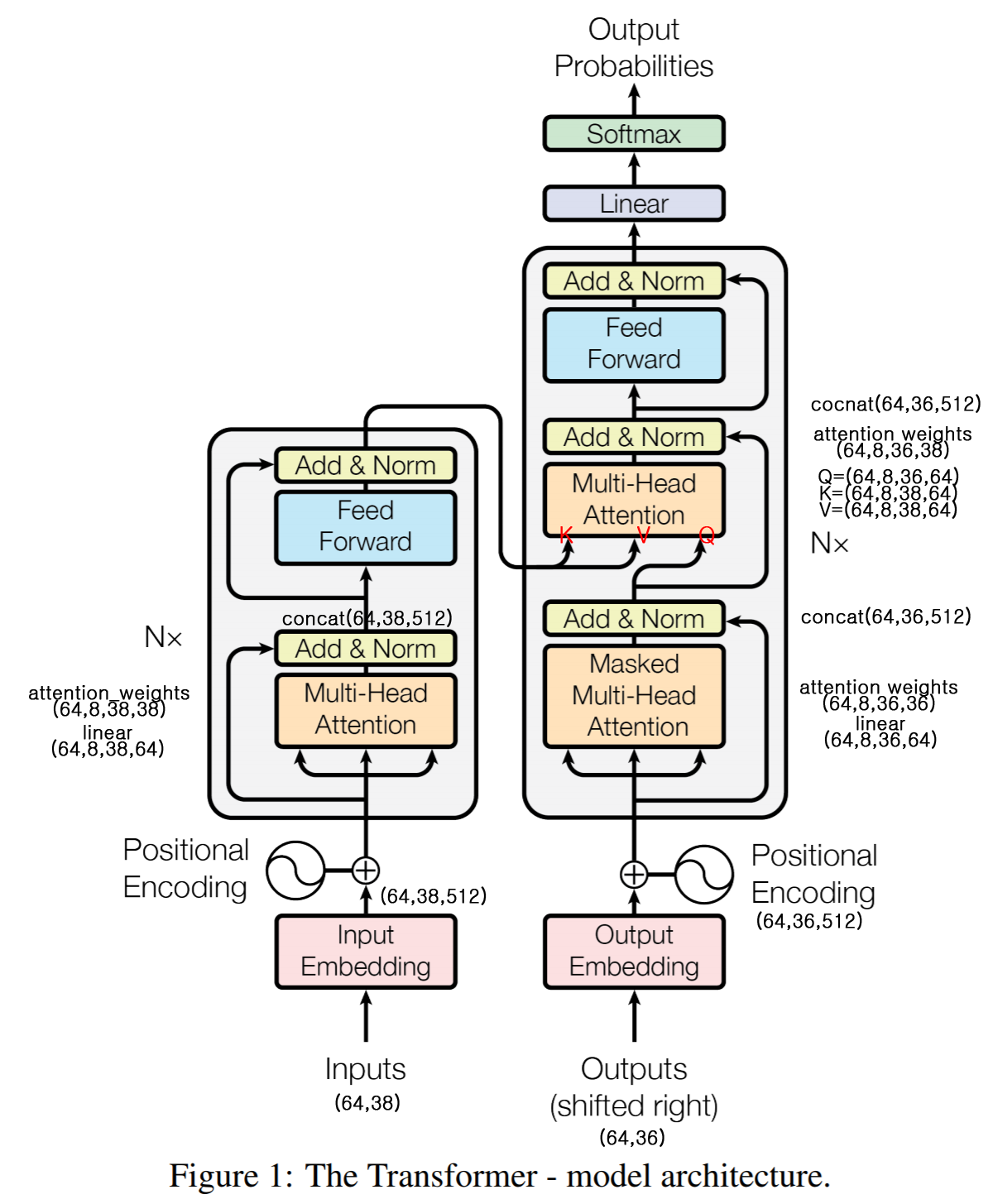
구글 리서처들이 대거 투입하여 만든 모델이기 때문에 따뜻하게도 구글의 Tensorflow에 Transformer를 구현하는 코드가 올라와 있다. 모두 여기를 참고하여 이론 뿐만 아니라 코드 또한 이해하길 바란다. 위의 이미지는 실제 Q,K,V의 Shape이 어떻게 되는지를 나타낸 이미지이다. 여기서 attention weights란, Scaled Dot-Product Attention에서 softmax(QK^T/sqrt(dk))를 연산한 Shape이라고 이해하면 되겠다. 즉, V와 행렬곱연산을 하기 직전의 Shape이라고 이해하면 되겠다.
이제부터 Multi Speaker Tacotron에 대해 설명하도록 하겠다. 필자인 나는 공부하는 입장이니까 내가 이해하는 한으로 최대한 자세하게 설명하도록 하겠다. 하지만 공부하는 입장이기 때문에 틀리는 부분도 있을 거라는걸 명심해 주길 바란다... RNN은 정말 너무 어렵다 ㅠ_ㅠ...
Tacotron 구조
위의 이미지가 구글의 Tactoron 구조이다. 이미지의 출처는 논문이기 때문에 참고하길 바란다. 참고로 논문 처음의 참여자들의 이름에 * 표시가 있는 분들은 타코를 좋아하고 † 표시가 있는 분들은 초밥을 더 좋아한다고 한다. 타코를 좋아하는 사람들이 더 많아서 타코트론이 되었다는 멋진 녀석.... 공대생들의 찐광기를 느낄 수 있는 부분
Tactron 구조 세부적으로 보기
Encoder
Tacotron Encoder
위의 이미지가 타코트론의 Encoder의 세부적인 내용이다. 우선 첫번째로 Character embeddings를 보도록 하겠다.
Character embeddings
사실 Character embeddings에 대해 아주 완벽하게 이해를 하지는 못했다. 내가 책으로 공부하기로는 단어의 one-hot encodding과 가중치의 matmul 연산의 불필요함을 줄이기 위해 한번에 단어 ID로 단어의 분산표현을 만들어내는 것이 Embedding이라고 이해했는데 Tacotron의 논문에서는 입력 인코더는 각 문자가 원-핫 벡터로 표현되고 연속 벡터에 포함되는 문자 시퀀스라고 설명되어 있어서 나의 지식과 혼동되고 있다.(ㅠㅠ) 뭐 아무튼 이래나 저래나 Character embeddings의 핵심은 단어의 분산표현을 나타낸다는 것이고, 결론적으로 이것을 쉽게 말하자면 단어를 숫자 데이터로 변환해준다는 뜻이다.
Pre-net
pre-net 세부 구조
Pre-net은 별거 없어 보인다. Fully Connected layer - ReLU - Dropout을 2번 반복하는 구조이다. 사실 처음 타코트론을 공부할 때 이 Pre-net은 단순히 오버피팅을 억제하는 정도로만 이해했었다. 근데 논문을 자세히 살펴보니 이 pre-net의 Dropout이 상당히 중요한 역할을 한다.
Pre-net의 Dropout은 크게 2가지 역할을 하는데 우선 첫번째로 일반화를 해준다는 점에서 매우 중요하다. 일반화란, 학습 데이터와 Input data가 달라져도 출력에 대한 성능 차이가 나지 않도록 하는 것을 의미한다. 즉, training data로 나오는 학습 결과만큼 새로운 입력 데이터에 대해서도 좋은 결과가 나올 수 있도록 돕는 역할이라는 것이다. 뭐, 한마디로 그냥 오버피팅을 억제한다고 생각해도 되겠다.
Pre-net의 Dropout은 bottleneck layer, 즉 병목 layer라는 점에서 중요하다. 병목 layer라고 하면 마치 이 계층이 병목현상을 유발한다는 것처럼 읽히지만 사실 이 계층은 병목 현상을 방지한다고 보면 되겠다. Dropout의 구조는 여기의 이미지를 참고하면 되는데, 쉽게 말하자면 모든 신경망을 사용하지 않고 일부만을 사용하여 학습을 진행하고 이 과정을 여러번 반복해 평균을 내 모든 신경망을 사용한것과 비슷한 효과를 내면서 overfitting, 즉 과적합을 방지한다. 이런 과정을 거치면, 여기서 설명하는 것과 같이 학습에 필요한 계산 비용이 크게 줄어들게 된다.
CBHG란 convolutional 1-D filters, bank, highway networks, gated recurrent unit bidirectional의 첫글자를 따서 지어진 이름이다. CBHG는 크게 보자면 CNN과 RNN으로 구성된 신경망으로, 층이 깊어질수록 복잡하고 추상화된 특징을 추출할 수 있는 CNN의 장점과 시계열 데이터의 전체적인 특징을 파악할 수 있는 RNN의 장점을 모두 합친 모델이다.
CNN 모델을 자세히 살펴보자면 Convolution, Max pooling, Convolution 계층을 지나면서 데이터 특징을 잡을 준비를 한다. (혹은 이미 데이터의 특징을 거의 잡아놨다.) 이 과정에서 바로 Highway Layers로 넘어가지 않고 Residual Connection을 하는데, 이는ResNet을 사용하는 이유와 같은 맥락이라고 보면 된다. 기존의 데이터에 대한 정보를 잃지 않기 위해 우리는 단순 합산을 통해 학습된 데이터와 기존의 데이터의 모든 정보를 갖고 Highway Layers를 통해 특징만을 추출해 낸다.
그 후, Bidirectional RNN으로 데이터를 보내 전체에 대한 흐름의 특징을 파악한다. 여기서 Bidirectional은 양방향이라는 뜻으로, Bidrectional RNN을 사용하는 이유는 시계열 데이터는 순방향 못지 않게 역방향으로도 맥락의 흐름을 유추할 수 있기 때문이다. 따라서 Bidrectional RNN을 사용하여 우리는 과거 시점에서도 미래 시점에 대한 데이터를 받고, 미래 시점에서 과거 시점에 대한 데이터를 받아 맥락의 전체적인 흐름에 대해 파악한다.
어텐션에 대한 자세한 내용은 링크와 동영상, PPT p.121 부터를 참고하길 바란다. 여기서 간단히 핵심만 다시 언급하자면 Attention이란 시계열 데이터에서 어느 부분에 집중할 것인가에 대해 학습하는 것이며, Attention을 사용하면 '일반화'가 가능하다. 즉, 새로운 데이터가 입력되어도 충분히 좋은 결과를 나타낼 수 있도록 도와준다.
Decoder
Tacotron Decoder
Decoder의 아래에 입력 데이터인 <GO> frame은 Decoder, 즉 시계열 데이터의 시작을 알리는 데이터로 큰 의미는 없다. (하지만 반드시 필요) 우리는 이 <GO> frame의 데이터와 Encoder에서 학습된, 문장의 특징을 잘 갖고 있는 단어 임베딩들을 (Encoder CBHG의 맨위쪽, 초록색 Embeddings) Attention 계층에서 학습시키고 (특징을 또한번 잡아내고) 일반 RNN을 사용하여 n개의 스펙토그램으로 출력한다. 이 Spectrogram은 음성 신호로 변환되기 직전의 숫자 데이터로, 발음, 음성에 대한 정보를 담고 있다. 즉, 결론적으로 Encoder에 들어온 단어 데이터들을 Decoder의 Attention과 RNN을 통해 음성 신호로 변환될 수 있는 숫자 데이터로 바꿔준다고 이해하면 되겠다. 이에 대한 자세한 설명은 PPT p.103부터 참고하길 바란다.
이렇게 스펙트로그램 데이터를 만들면 CBHG를 통해 또한번 특징을 잡은 후 하나의 시계열 데이터로 출력한다. 이 데이터를 스펙트로그램을 음성 데이터로 변환해주는 Griffin-Lim을 통해 음성 데이터로 출력한다.
위의 구조가 Tacotron의 구조이다. 정말... 정말 복잡하다... 사실 이해하고 보면 그렇게 어렵지는 않은데 다양한 개념들이 섞여서 헷갈린다. 하지만 그냥 엄청엄청 쉽게 이해를 하자면 악착같이 시계열 데이터들에 대해 특징을 잡아내고 일반화를 하기 위해 노력하는 짓을 n번 반복하여 결과물을 만들어내는 악착같은 모델이라고 이해하면 되겠다.
Multi Spekaer Tacotron - Speaker Embedding
여기서 끝이 아니다. 우리는 Multi Speaker Tacotron을 사용하기 때문에 Multi Speaker에 대해서도 이해해야한다. 사실 이 부분에 대해서는 완벽하게 이해를 아직 하지 못했기 때문에 대략적으로 설명하고 넘어가도록 하겠다. (큐ㅠ)
Multi Speaker Tacotron은 Baidu에서 발표한 Deep Voice2에 기재된 내용으로, 쉽게 말하자면 여러명의 발화자에 대해 적은 메모리 사용량으로도 효과적으로 학습할 수 있다는 내용이다. 이에 대한 자세한 설명은 PPT의 p.159부터 참고하길 바란다.
간략하게 설명하자면 N명의 발화자(Speaker) 정보를 가진 Speaker Embedding을 만들어 Encoder CBHG의 CNN부분(정확히는 residual connection)과 RNN부분에 삽입한다. 그리고 Decoder Pre-net과 RNN에 삽입하여 적은 메모리 사용량으로 효과적으로 여러명의 음성 특징을 학습할 수 있게 한다.
Multi Speaker Tacotron을 사용하면 결론적으로 잘 학습된 Attention이 잘 학습되지 않은 Attention의 학습에 도움을 주어 적은 양의 데이터로도 충분히 좋은 효과를 볼 수 있다. 필자가 이해하기로는 전이학습과는 다르지만, 결론적으로 학습이 잘된 Attention이 학습이 안된 Attention의 학습에 도움을 준다는 것이 전이학습과 비슷한 '결'이지 않을까 싶다. 이 부분에 대해서는 아직 정확하게 알지 못하기 때문에 추가적으로 기재하도록 하겠다.
아무튼 Speaker Embedding을 사용하여 여러 화자에 대한 Attention을 학습하면 내가 원하는 특징(예를 들자면 발화 속도, 억양과 같은)만을 추출하여 다른 화자에게 대입할 수 있다. 이 부분에 대해서도 PPT p.185부터 참고하길 바란다.
설명이 부족하거나 이해가 가지 않는 부분에 대해서는 우리가 참고한 github의 주인인 carpedm20님의 PPT와 동영상을 참고하길 바란다. (이미 너무 남발하긴 했지만ㅋㅋㅋㅋ) 큰 틀에서 이해하기엔 동영상이 최고다... 흑흑 이제 드디어 끝났다.. 타코트론아 많은 깨달음을 줘서 고맙지만,,, 참,, 힘들었다,,,,★
내가 딥러닝을 제대로 이해하기 시작한게 사실상 올해부터였다. 인공지능을 공부했던건 작년부터였지만 그때는 머신러닝을 이해하는 것도 벅찼고 CNN은 더 벅찼으면 RNN은 사실상 포기였다. 하지만 취업이 바로 안되고(ㅠㅠ) 할 것도 없기에 애매하게 아는 것보단 완벽하게 이해하는게 낫겠다 싶어서 국비 지원으로 인공지능을 다시 배웠다. 6개월 과정에서 나는 SQL, LINUX, HADOOP, R 등 엄청 다양한걸 많이 배웠는데 다 이게 피가되고 살이 되지 않겠나 싶다.
암튼 이렇게 구구절절하게 글을 쓰는 이유는 최종 팀프로젝트가 RNN 기반이기 때문이다. 이번에는 책까지 구매해가며 먼저 책을 읽고 수업을 듣고 스터디까지 해서 CNN은 잘 이해했는데 RNN은 그래도 너무 어려운기라! 근데 2번이나 각잡고 배웠는데ㅠㅠ; 이걸 또 포기하기엔 내 자존심이 용납이 안되서 그냥 팀원들한테 욕심으로 RNN과 관련된 프로젝트를 하자고 했고, 다들 OK 해준 덕분에 이 프로젝트를 진행할 수 있었다.
나는 일단 일을 벌려야 한다. 욕심이 있으니까 벌려놓으면 그걸 잘하려고 열심히 하기 때문이다. 결과적으로 RNN과 관련된 프로젝트로 일을 벌린건 잘한 일이었다. 사실 지금도 정확히 RNN을 이해했다고 볼 수는 없겠지만 이 프로젝트를 하겠다고 RNN을 다시 공부하고 또 블로그에 글을 정리해가고 팀원들에게 설명을 해주면서 대충 그 흐름은 파악한 것 같다. 그리고 무엇보다 팀프로젝트 결과가 좋다. 넘 행복하다!!!!
사실 아이디어의 시작은 아주 간단했었다. 거창한 이유로 TTS를 하고 싶었던건 아니고, 매일 9시부터 6시까지 학원에 나가 공부를 했었는데 코로나가 심각해지면서 비대면 수업으로 전환되면서 ZOOM으로 수업을 하게 됬는데 선생님 목소리 데이터가 너무 깨끗한거다! 정말 음질이 너무너무 깨끗했다. 그리고 개인적으로 선생님 목소리도 좋으셔서 음~ 이거 뭔가 데이터가 쓸만할 것 같은걸...? 이라는 생각이 들었었다.
그러다 팀 아이디어 회의에서 RNN과 관련된 프로젝트를 하고 싶다는 내 말에 다들 하나 둘씩 아이디어를 냈는데, 선생님의 목소리로 TTS를 만들어보자는 의견이 나왔다. 처음엔 다들 간단하다고 생각했지만 이걸 구현할 수 있는가는 다른 얘기인건 수많은 공대생들은 다 뼈저린 경험으로 알고 있을 것이다. 나는 그 공대생 중에 하나였고, 이걸 과연 우리 수준에서 구현할 수 있는지에 대해 찾아보기 시작했다.
그러다 이 동영상을 보게 되었다.
딥러닝을 이용한 아이유 음성 TTS PoC
그리고 더보기에 올라온 블로그를 참고하기 시작했다. 이 분은 심지어 라디오 데이터를 사용했는데도 이렇게 잘 나왔는데, 나라고 안될건 없었다. 심지어 데이터 양도 그렇게 많지 않았음에도 충분히 좋은 결과가 나왔었다.
이건.. 이건 할만하다...!!!
그렇게 이 프로젝트에서 가장 소중하고 감사한 carpedm20님의 깃허브를 참고할 수 있게 되었다. 사실 나는 그 전까지만 해도 깃허브를 알기만 했지 도대체 어떻게 쓸 수 있는지를 이해하지 못했는데 이 프로젝트 덕에 깃허브까지 이해를 했다. ㅠㅠ 정말 소중한 프로젝트인걸...?
그래서 열심히 전처리하고 데이터 수집하고,,, 했다. 데이터는 준비 됐다. 양질의 4+시간의 데이터를 수집했고 그 과정에서 아주 간단한 파이썬 코드도 구현했다. 엄청 간단하지만 나름 코드 짠 내가 자랑스러웠다ㅋㅋㅋㅋㅋㅋㅋ 그래서 이제 깃허브를 참고해서 학습하기만 하면 됐다! 그랬다!!!!!! 근데 이게 진~짜 오류가 엄청 났다... 엄청난 양의... 모듈들을 다운 받아야했지만... 그게 왜이렇게 오류들이 나는지.. 솔직히 나는 그 빨간 글자들을 보면서 하기 싫었는데 다행히 팀원분 중에 한 분이 엄청엄청 열심히 오류 수정하면서 환경 구성을 해주셔서 아주 잘~! GPU 환경에서 잘 돌아갈 수 있게 되었다.
우리가 사용한 CUDA version은 8.0이고 cudnn은 6.0을 사용하였다.
암튼 이 주저리 Preview 글에서는 내가 활용했던.. 너무 간단해서 창피하기까지한 파이썬 코드를 같이 첨부하도록 하겠다.
이 코드는 정말 간단하게 총 데이터양이 몇시간인지를 판단해주는 함수 하나랑 csv 파일을 json으로 바꿔주기 위한 전처리 코드들이랑 무음 기준으로 알아서 효과적으로 긴 시간의 음성 데이터를 라벨링하기 쉽게 짤라주는 코드 하나가 있다.
손석희 데이터처럼 구글 API를 사용하고 싶었는데, 선생님은 대본 없이 그냥 말하시다보니 구글 API의 불안정함을 잡아줄 수 있는 부분이 없어서 이건 안타깝게도 그냥 다 사람이 했다... 원래 사람이 최고다... 사람은... 갈린만큼 좋은 결과물을 내놓지...
그리고 프로젝트 이름이 DJ You인 이유는, 음성 합성에 사용했던 선생님의 성이 유씨인것도 있지만 사람의 음성만 있으면 그 사람의 특징을 살려내면서 음성합성이 가능한 모델이기 때문에 선생님(Yu)은 물론, 당신(You)도 DJ가 될 수 있다는 의미에서 DJ You로 만들었다.
암튼! 그렇다는 이야기다. 지금까지의 얘기가 이 프로젝트를 하게 된 이유, 전처리에 대한 주저리 정도라면 앞으로는 실제 사용한 모델인 Multi Speaker Tacotron에 대해 설명하도록 하겠다.
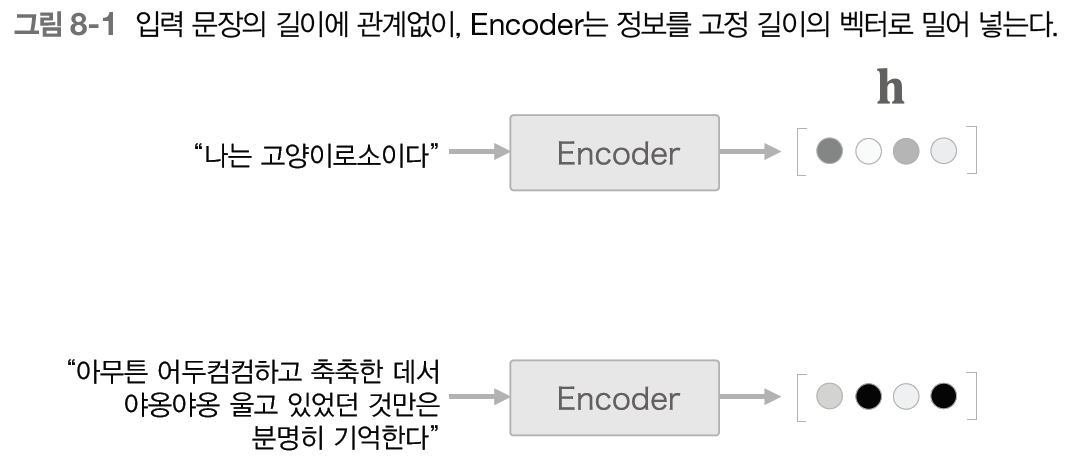
seq2seq는 Encoder가 시계열 데이터를 인코딩하고, Encoder의 출력은 h(은닉 벡터)이며 h는 고정 길이의 벡터였다. 하지만 데이터가 모두 항상 동일한 길이일수도 없는 노릇이고 이것을 매번 고정 길이의 벡터로 출력하는 것은 데이터의 손실 및 공간 낭비의 문제가 발생하게 된다.
문장이 길어도 고정 길이 벡터로 출력된다.
Encoder 개선
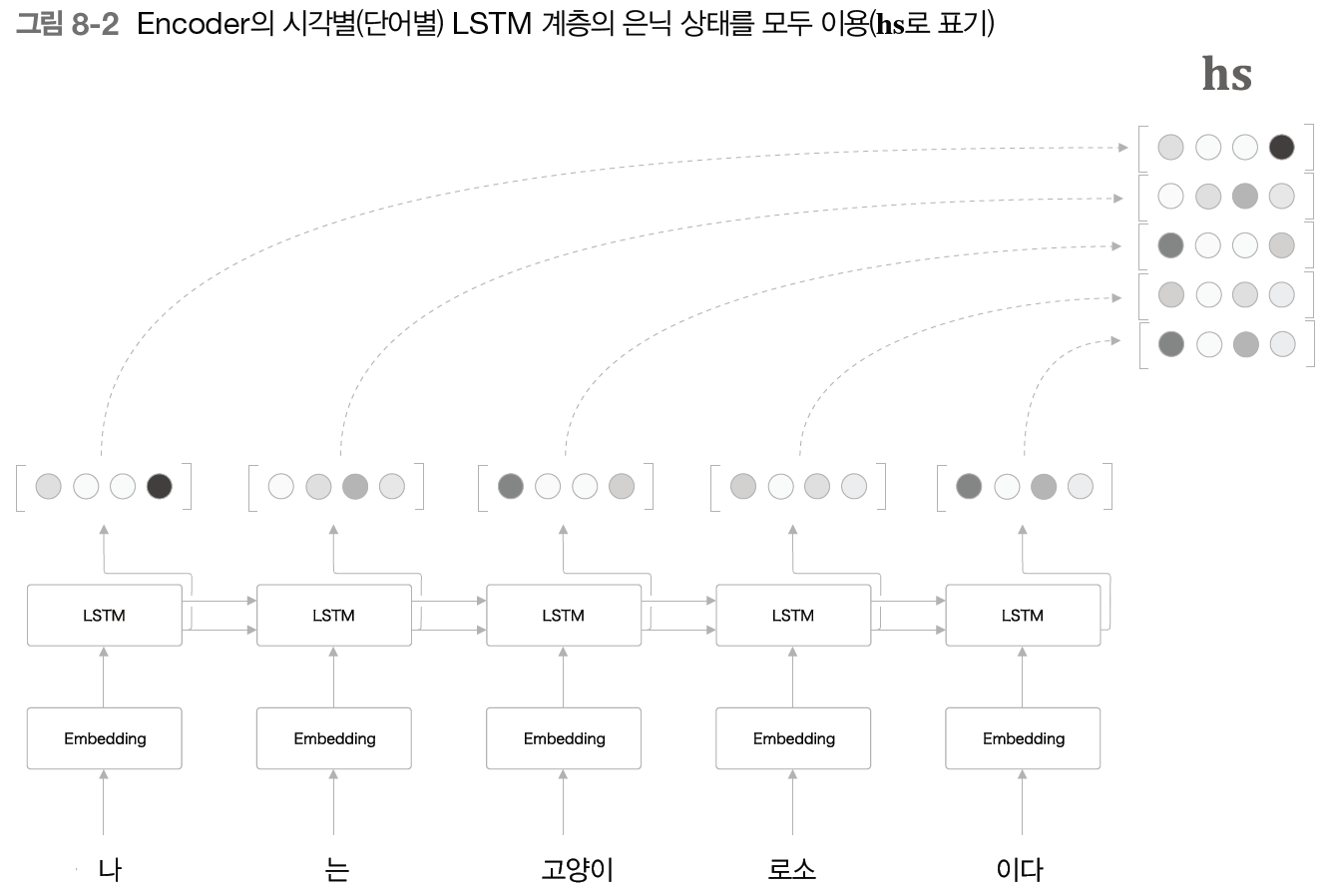
이전에 설명한 seq2seq에서 우리는 RNN(LSTM)의 마지막 은닉 상태(h)만을 Decoder에 전달했다. 하지만 위의 문제점을 해결하기 위해서는 Encoder의 출력은 고정 길이 벡터가 아닌, 문장 길이에 따라 바꿔주는 것이 좋다. 따라서 우리는 이 문제점을 해결하고자 시각별 RNN(LSTM) 계층의 은닉 상태 벡터를 모두 이용한다.
모든 시각의 은닉 상태 벡터를 hs라고 한다.
위의 이미지처럼 각 시각(단어)의 은닉 상태 벡터를 모두 이용하면 입력된 단어와 같은 수의 벡터를 얻을 수 있다. 이는 코드로는 RNN 계층의 초기화 인수로 return_sequences=True로 설정하면 모든 시각의 은닉 상태 벡터(hs)를 반환하게 된다. 단순히 모든 시각의 은닉 상태 벡터를 꺼내는 것만으로, 우리는 입력 문장 길이에 비례한 정보를 인코딩 할 수 있게 되었다.
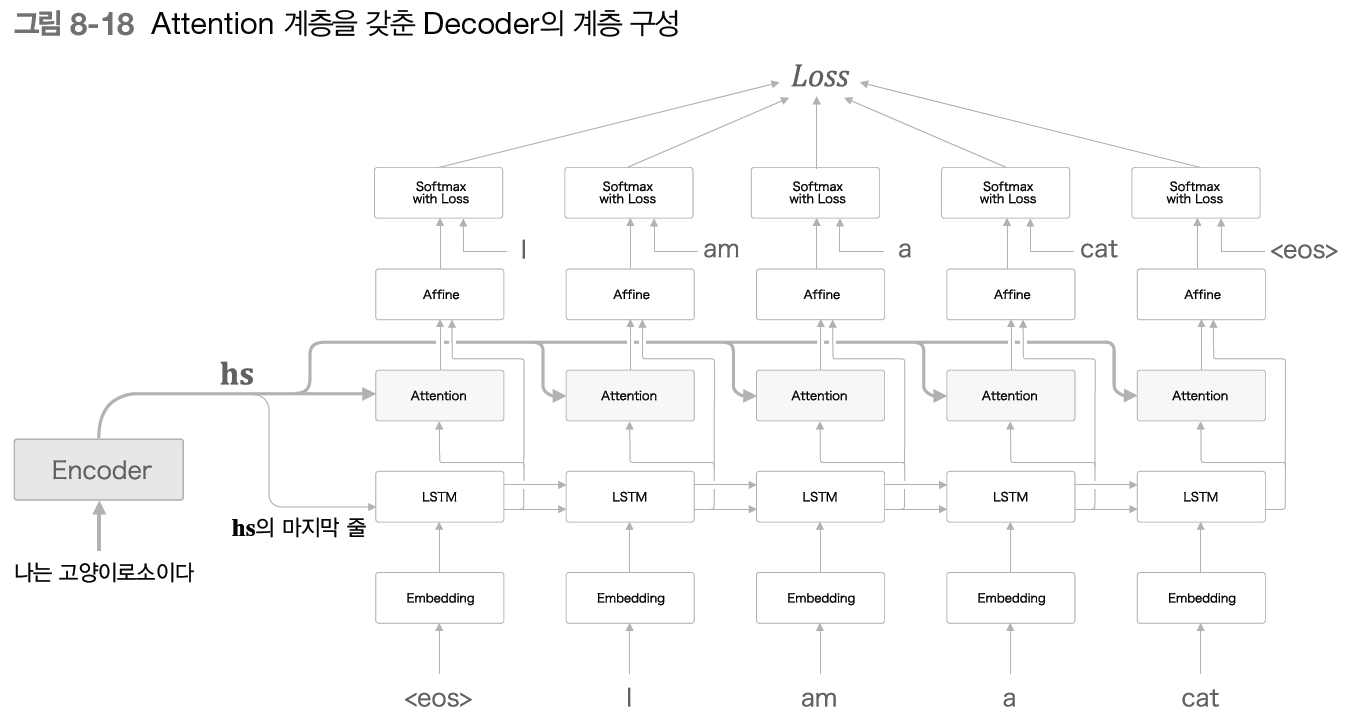
개선된 Encoder에서 보내는 hs를 활용하기 위해서는 Decoder 또한 개선해야 한다. 기존의 Decoder는 기존의 Encoder가 마지막 은닉 상태 벡터만을 Decoder로 넘겼기 때문에, hs 전체를 활용할 수 있도록 개선해야 한다. 그렇다면 Decoder는 어떻게 hs 전체를 활용할 수 있을까?
우리는 기존에 한개만 받던 h를 뭉태기(hs)로 받게되었다. 이 말은 즉슨, 문장 전체에 대한 정보를 입력받을 수 있다는 소리다. 이 덕에, 우리는 입력과 출력의 여러 단어 중 어떤 단어끼리 서로 관련되어 있는가에 대한 대응 관계를 학습할 수 있게 되었다. 이러한 구조를 어텐션(Attention)이라고 하며, 어텐션은 필요한 정보에만 주목하여 그 정보로부터 시계열 변환을 수행하도록 한다.
위의 그림은 어텐션이 사용된 개선된 Decoder이다. 여기서 어텐션 계층의 입력 데이터는 Encoder로부터 받는 hs와 시각별 LSTM 계층의 은닉상태 벡터(h)이다. 어텐션 계층에서의 계산을 통해 필요한(중요한) 정보만이 Affine 계층으로 출력된다.
어텐션의 기본 아이디어는 Decoder에서 출력 단어를 예측하는 매 시각마다, Encoder에서의 전체 입력 문장을 다시 한 번 참고한다는 것이다. 여기서 어텐션은 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 된다.
어텐션 계층의 대략적인 개념을 설명했으니, 그래서 어텐션 계층이 어떻게 동작하는지 살펴보도록 하자. 우리는 어텐션 계층이 필요한 정보만을 추출해낸다고 이해했다. 하지만 어텐션 계층도 결국에는 학습을 통해 갱신되는 계층이다. 학습을 통해 갱신됨은 역전파를 활용하여 매개변수값을 조정해 나가는 것이고 이것은 미분을 의미한다. 미분에는 '선택'이라는 개념은 없다. 그렇다면 우리는 어떤 계산을 해야하는걸까?
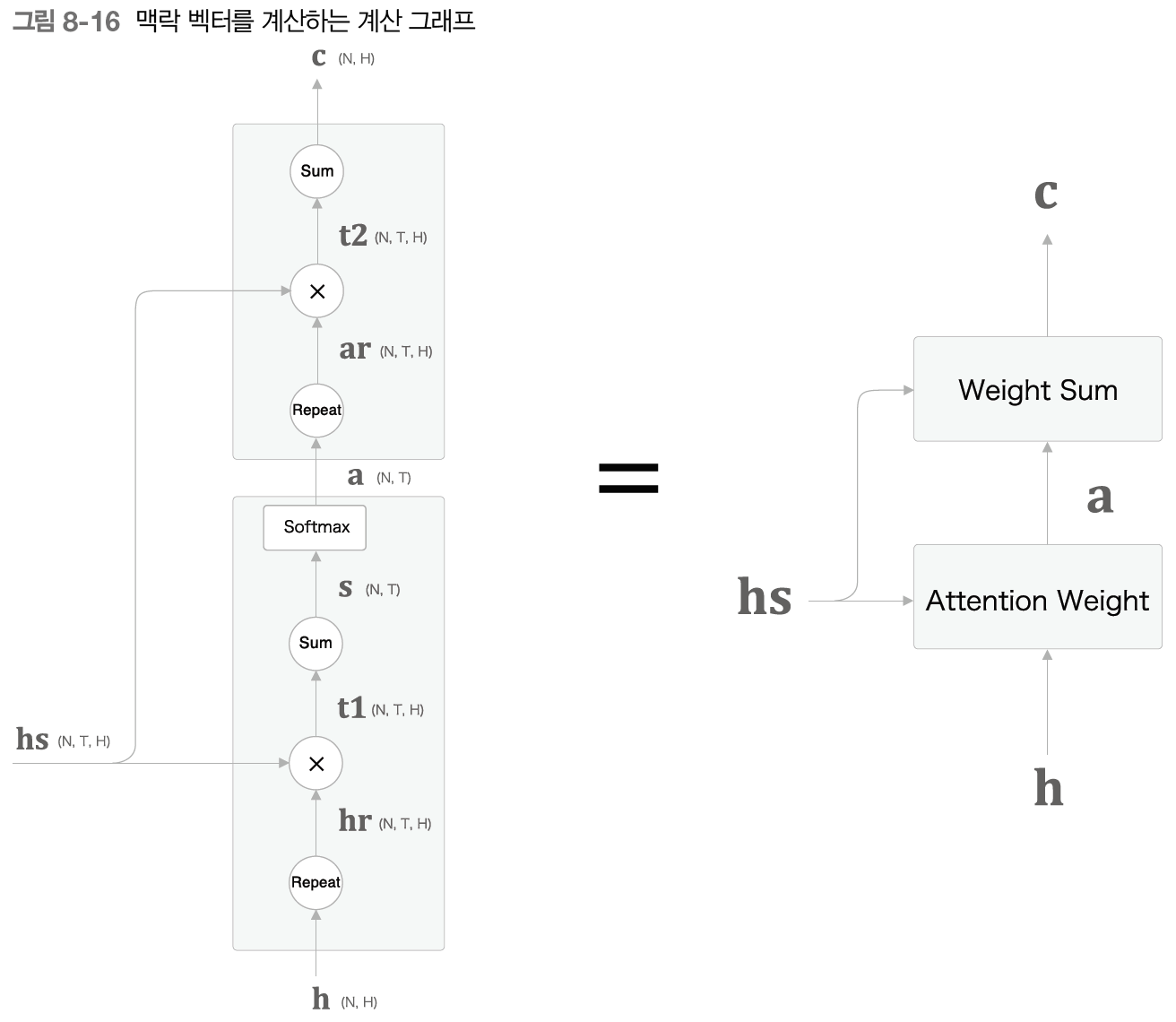
Attention 계층의 세부 연산을 보여주는 이미지
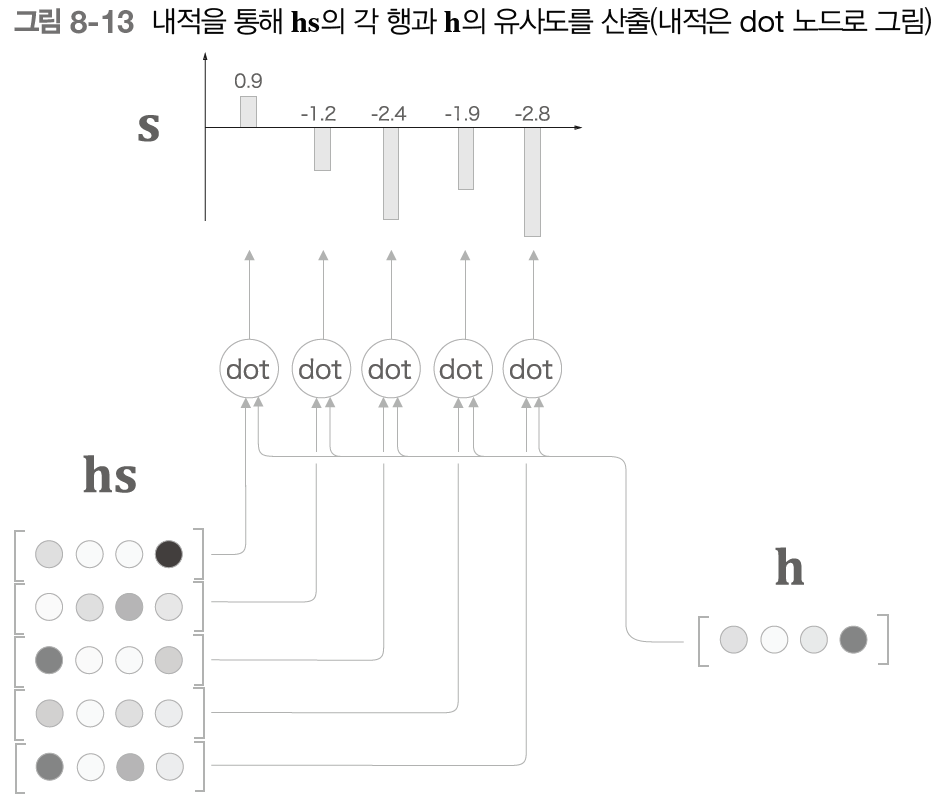
위의 이미지를 보면 Attention 계층은 크게 2가지의 중요 연산으로 나눠 볼 수 있다. 여기서 입력 데이터인 hs는 Enocoder에서 입력되는 모든 은닉 상태의 데이터이며, h는 hs를 활용하여(정확히는 hs 벡터의 마지막 줄) LSTM 계층 연산을 통해 출력된 은닉 상태 벡터(h)이다. Attention Weight은 Encoder가 출력하는 각 단어의 벡터 hs에 주목하여 해당 단어의 가중치 a를 구하고, Weight Sum은 a와 hs의 가중합을 구해 맥락 벡터 c를 출력한다.
Attention Weight
단어의 가중치(기여도)를 나타내는 벡터인 a는 어떻게 구하는걸까?
Decoder의 LSTM 계층의 은닉 상태 벡터는 h이며, 우리는 이 h가 Encoder의 입력 데이터인 hs와 얼마나 비슷한가를 수치로 나타내고자 한다. 이를 위해서 우리는 벡터의 내적을 이용한다. 벡터의 내적은 두 벡터가 얼마나 같은 방향을 향하고 있는가를 의미하며, 이는 벡터간의 유사도를 표현하는 척도로 사용될 수 있다.
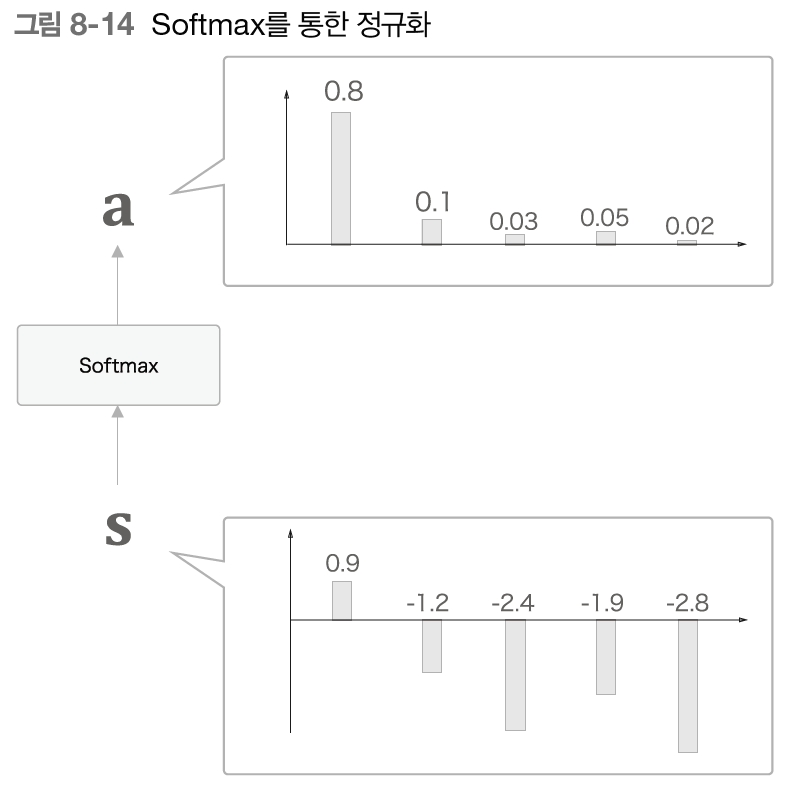
위의 이미지처럼 h와 hs의 내적으로 각 단어 벡터의 유사도를 구한 결과가 s이다. 이 s는 정규화 하기 이전의 값으로, 점수라고도 한다. 이 s를 정규화하기 위해 softmax함수를 적용시켜 나온 결과가 바로 우리가 원하는 가중치 a이다.
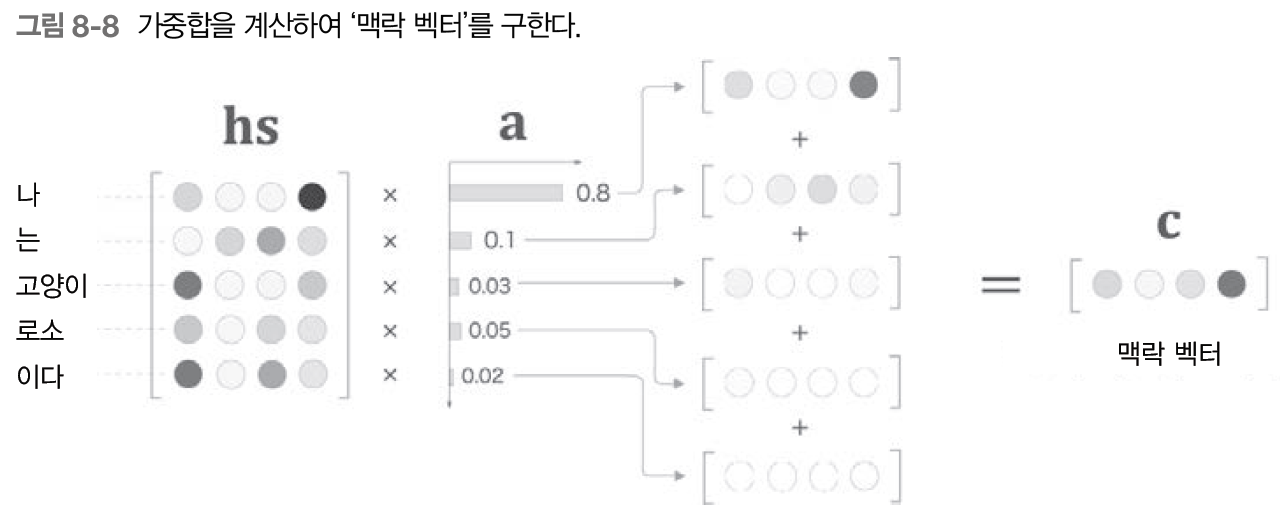
Weight Sum
Weight Sum 계층은 (Attention 계층 안에서도 크게 2가지로 나뉘기 때문에 계층이라고 부르겠다) 모든 은닉 상태 벡터(hs)와 가중치를 나타내는 행렬(a)이 연산(행렬곱)하여 그 결과를 합해 맥락 벡터(c)를 얻어낸다.
이렇게 어텐션은 두 시계열 데이터 사이의 대응 관계(얼라인먼트:Alignment)를 학습하게 되며, 중요한 정보를 집중적으로 파악할 수 있다. 어텐션에 대해 더 자세히 이해하고 싶다면 이 블로그를 참고하길 바란다.
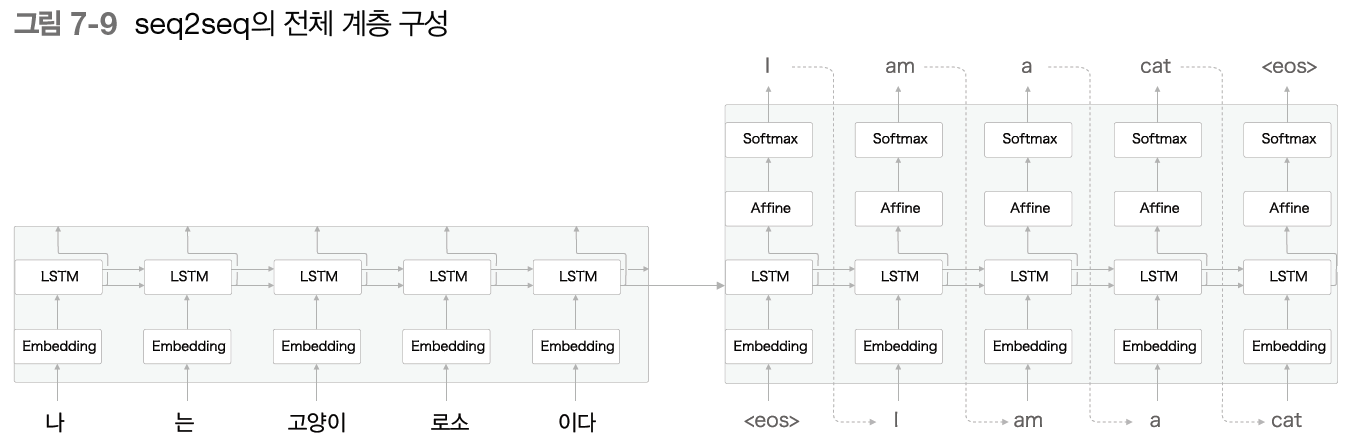
seq2seq는 발음 그대로 sequence to sequence라는 뜻으로 여기서 sequence는 시계열 데이터를 의미한다. 즉, seq2seq는 하나의 시계열 데이터를 다른 시계열 데이터로 변환하는 모델을 의미한다. 예를 들자면 음성 인식 및 챗봇과 같은 것이 있겠다. seq2seq는 2개의 RNN을 사용한다.
seq2seq를 다른 말로 Encoder-Decoder 모델이라고도 한다. 이는 seq2seq가 Encoder와 Decoder를 사용하기 때문이며, Encoder는 입력 데이터를 인코딩(부호화)하고, Decoder는 인코딩된 데이터를 디코딩(복호화)한다.
위의 이미지처럼 Encoder가 인코딩한 정보에는 번역에 필요한 정보가 있고, Decoder는 이 정보를 바탕으로 문장을 생성해 출력한다. 이처럼 Encoder와 Decoder를 사용해 시계열 데이터를 다른 시계열 데이터로 변환하는 것이 seq2seq의 전체 그림이며, 우리는 Encoder와 Decoder에서 RNN을 사용한다.
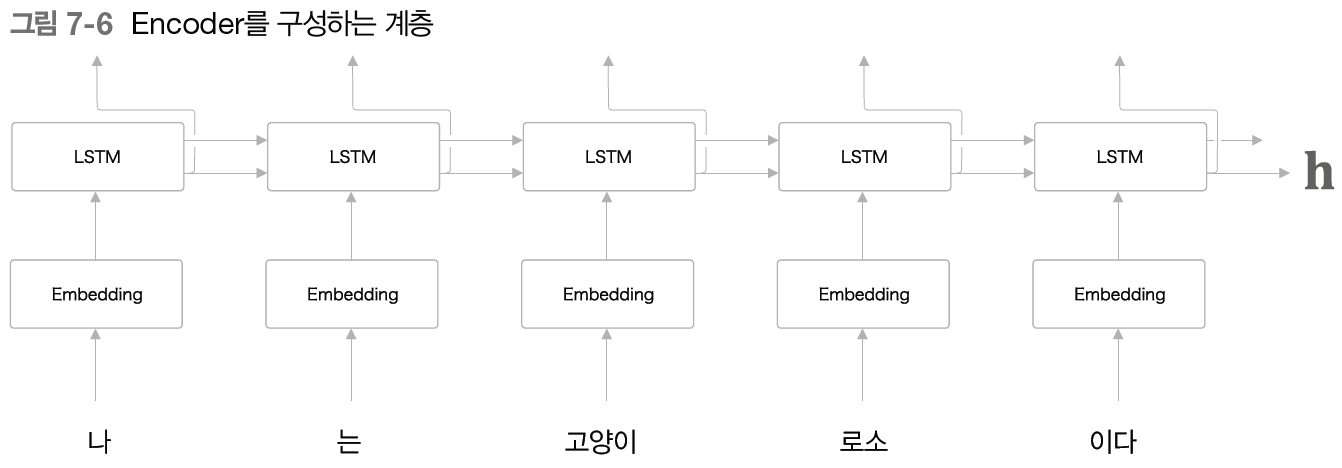
Encoder
Encoder는 RNN(LSTM)을 이용해 시계열 데이터를 h라는 은닉 상태 벡터로 변환한다. Encoder에서 출력되는 h는 입력 문장(출발어)을 번역하는 데 필요한 정보가 인코딩되며 은닉 벡터 h는 고정 길이 벡터로, 결론적으로 인코딩의 의미는 임의 길이의 문장을 고정 길이 벡터로 변환하는 작업을 뜻한다.
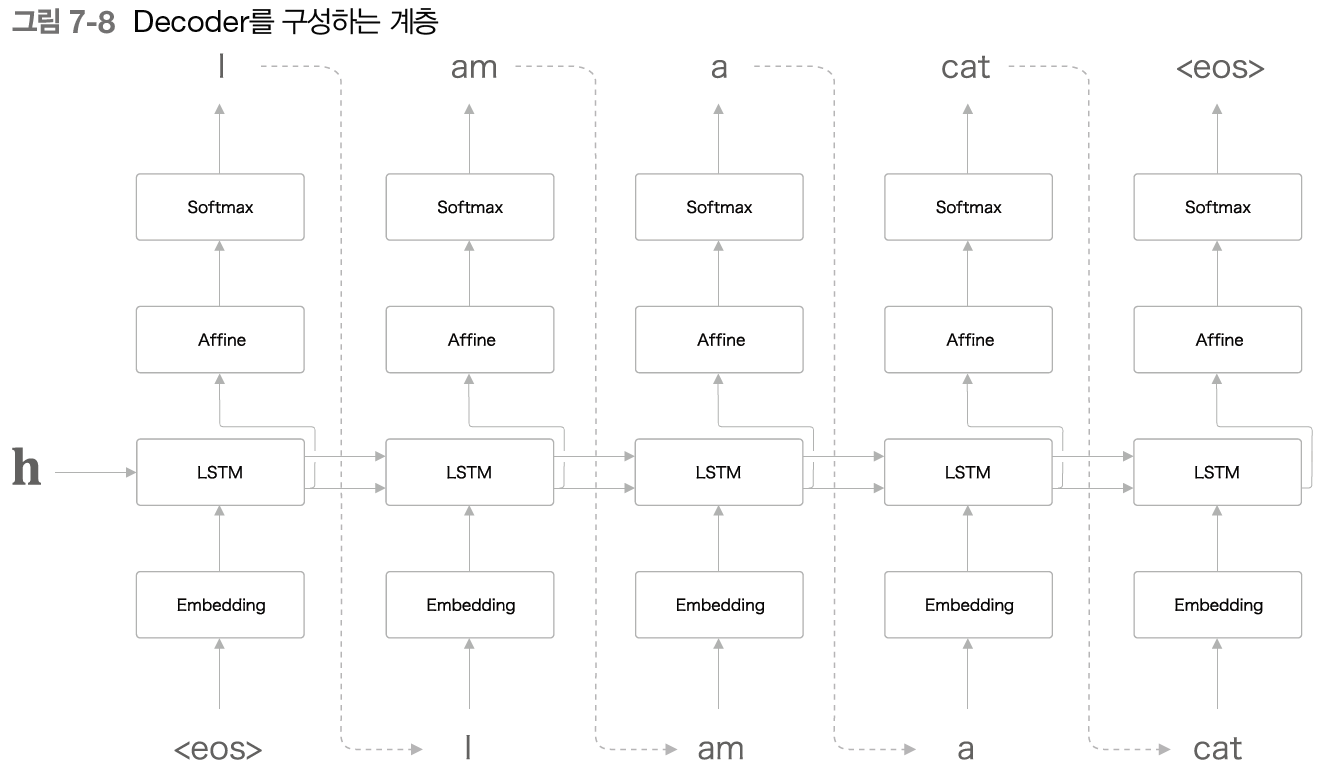
Decoder
Decoder는 RNNLM과 동일한 구조(위에서는 RNN을 LSTM으로 대체함)이지만, LSTM 계층에 h를 입력받고 첫번째 단어가 <eos>라는 특수문자인 것이 큰 차이점이다. <eos>는 문장의 시작을 의미하며, 실질적으로 Decoder는 h의 데이터를 활용하여 문장을 생성해 나간다. Decoder의 첫번째 LSTM 셀은 h와 <eos>, 이 2개의 입력을 바탕으로 새로운 은닉 상태h를 계산하고 이를 Affine 계층과 Softmax 계층을 거쳐 다음에 등장할 확률이 높은 "I"를 예측한다. 이 과정을 문장의 종료를 의미하는 <eos>가 나올때까지 반복하는 것이 Decoder의 개념이다.
이처럼 seq2seq는 2개의 LSTM(Encoder의 LSTM과 Decoder의 LSTM)로 구성되며 Encoder의 LSTM에서 생성된 은닉 벡터인 h가 Decoder의 LSTM에 전해지면서 서로 다른 시계열 데이터로의 변환이 이루어질 수 있게 된다.
추가적으로 seq2seq 역시 신경망이기 때문에 미니배치 학습이 가능한데, 여기서 문제가 발생한다. 만약 seq2seq에 입력되는 문장의 길이들이 모두 동일하지 않고 다른 경우에 어떻게 미니배치 학습을 시킬 수 있을까? 미니배치는 미니배치에 속한 샘플들의 데이터 형상이 모두 똑같아야 하기때문에 패딩(padding)을 사용하여 전체 데이터의 길이를 일정하게 맞춰준다. 패딩은 원래의 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 기법이다.
seq2seq 개선
1. 입력 데이터 반전(Reverse)
입력 데이터를 반전시키는 것만으로도 놀랍게도 seq2seq의 학습 속도는 빨라지고 정확도도 향상된다. 이에 대한 이론적인 부분에 대해서는 정확히 아는 바가 없지만, 참고한 책의 저자는 직관적으로 기울기 전파가 원활해지기때문이라고 한다. 나는 고양이로소이다.가 I am cat이 되기까지, '나'로부터 'I'까지 가기 위해서는 '는','고양이','로소',이다'까지 총 4가지 단어 분량의 LSTM 계층을 거쳐야하고 이는 기울기에 영향을 줄 수 있다. 따라서 입력 데이터를 반전하면 데이터가 대응하는 변환 후 단어와 가까워지는 경향이 많기 때문에 기울기가 더 잘 전해져서 학습 효율이 좋아진다고 이해할 수 있다.
2. 엿보기(Peeky)
이것은 DenseNet과 비슷한 개념을 갖고 있다. 즉, Decoder의 처음에 입력되면서 Encoder의 가장 중요한 정보를 갖고 있는 h가 단순히 Decoder 처음에만 입력되는 것이 아니라 다른 계층, 즉 Decoder 전체 계층에 전하는 것이다. 이처럼 중요한 정보를 하나의 LSTM 계층이 갖는 것이 아니라 모든 LSTM 계층이 갖게 되면 더 올바른 결정을 내릴 가능성이 커진다.
앞서 설명한 RNN은 성능이 좋지 못하다.(ㅠㅠ 도대체 언제 좋은거 만들건데요) 그 원인은 대개 장기 의존 관계, 즉 긴 시계열의 패턴을 파악 및 학습하기 어렵다는 것이다. 따라서 앞서 설명한 RNN은 가장 기초적인 RNN의 개념 정도로만 이해하고 실제로 쓰이는 계층은 주로 LSTM과 GRU이다. 이 LSTM과 GRU는 기존의 RNN에 게이트라는 구조가 더해져 있어 시계열 데이터의 장기 의존 관계를 학습할 수 있다. 게이트가 무엇이고 어떤 구조이길래 장기 의존 관계를 학습할 수 있게 되었는지 LSTM을 통해 살펴보도록 하자.
기존 RNN의 문제점
LSTM을 설명하기 앞서, 기존 RNN이 데이터의 장기 의존 관계를 학습하기 어려운 이유에 대해 자세히 설명하도록 하겠다. 기존의 RNN이 장기 의존 관계를 학습하기 어려운 이유는 BPTT에서 기울기 소실 혹은 기울기 폭발이 일어나기 때문이다. 앞서 BPTT에서 설명했다시피, BPTT는 시간 크기가 커질수록 기울기가 불안정하다. 이와 관련해서 RNNLM을 활용한 하나의 예시를 들도록 하겠다.
철수는 교실 책상에 앉아 있다. 영희는 교실로 들어갔다. 영희는 ___에게 인사를 했다.
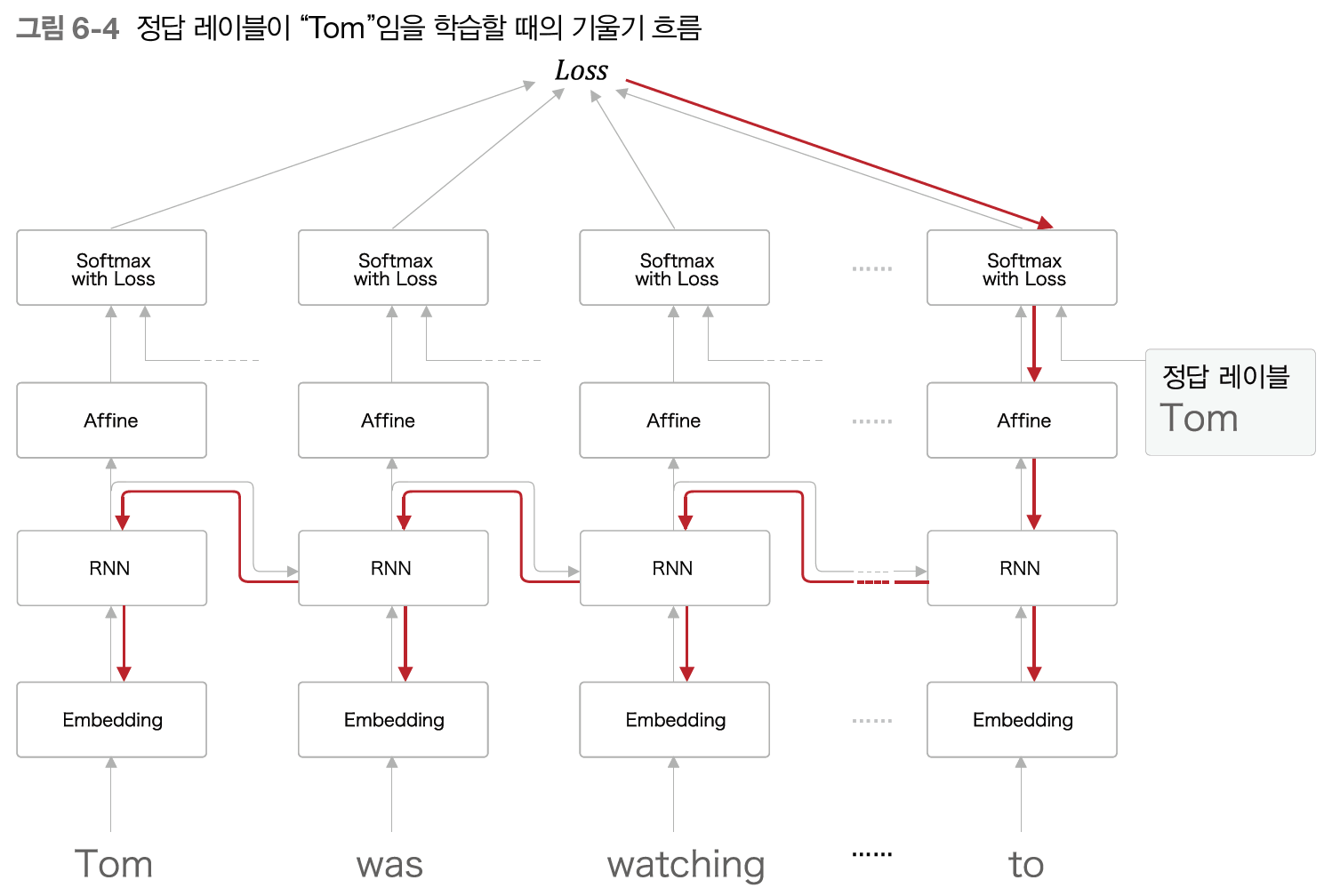
여기서 ___에 들어갈 말은 무엇일까? 이것을 알기 위해서는 사람이나 RNN이나 똑같다. 우리는 영희가 '철수'에게 인사를 한다는 것을 문맥의 흐름으로 유추할 수 있다. 그렇기 위해서는 철수가 교실에 있다는 정보를 기억해야한다. RNN도 동일하다. 영희가 '철수'에게 인사를 한다는 것을 앞서 학습했던 문장을 기억하여 예측할 수 있다. 이런 정보를 RNN 계층은 은닉 상태에 인코딩해 보관해둔다.
그렇다면 이 예제에서 RNNLM은 어떻게 학습을 할까? 정답으로 '철수'가 주어졌을 때 RNNLM은 그 시점(정답이 주어진 시점)으로부터 과거 방향으로 기울기를 전달하게 된다.
Tom을 철수라고 생각해 이해하자.
RNN 계층은 과거 방향으로 의미 있는 기울기를 전달함으로써 시간 방향의 의존 관계를 학습할 수 있다. 하지만 기울기 소실, 혹은 폭발이 일어난다면 유의미한 기울기가 전달되지 못하고 그 결과 가중치 매개변수가 제대로 갱신되지 않아 학습이 잘 되지 않는다. 그렇다면 기존 RNN 계층에서 왜 기울기 소실 혹은 폭발이 일어나는 것일까?
기울기 소실 및 폭발 원인
1. 활성화 함수 (tanh)
기존 RNN의 활성화 함수로는 tanh함수를 주로 사용하는데, 이는 모든 신경망의 기울기 소실 이유와 동일한 양상을 띠게 된다. tanh함수를 역전파시키면 층이 깊어질수록 기울기값이 점점 작아지는 문제가 발생하게 되기 때문이다.
2.MatMul(행렬 곱) 노드
기존 RNN의 역전파 시 기울기는 MatMul 노드에 의해서도 변화하게 된다. (여기서는 기울기 폭발을 생각하기 위해 tanh함수의 역전파는 무시하도록 한다.) 기울기는 MatMul 노드를 지나가는 횟수에 비례해 폭발적으로 증가 혹은 감소하게 된다. MatMul 노드의 값이 1 이상인 경우는 층이 깊어질수록 곱해지면서 기울기 폭발이 일어나고, 1 이하인 경우는 층이 깊어질수록 기울기 감소가 일어나게 된다. 지금 설명은 MatMul 노드가 스칼라값이지만 행렬일 경우에는 행렬의 특잇값(데이터가 얼마나 퍼져 있는지를 나타냄)이 척도가되어 특잇값의 최댓값이 1보다 크면 지수적으로 증가하고, 1보다 작으면 지수적으로 감소할 가능성이 높다고 예측한다.
기울기 폭발에 대한 대책으로는 기울기 클리핑(gradient clipping)을 사용한다. 기울기 클리핑의 식은 다음과 같다.
기울기 클리핑
신경망에서 사용되는 모든 매개변수에 대한 기울기를 하나로 처리한다고 가정(모든 매개변수에 대한 기울기의 합)하고, 이를 g라고 표현했다. 이때 ||g||이 문턱값을 초과하면 두번째 줄의 수식과 같이 기울기를 수정하는 것을 기울기 클리핑이라고 하며 이는 기울기 폭발을 효과적으로 잘 대처한다.
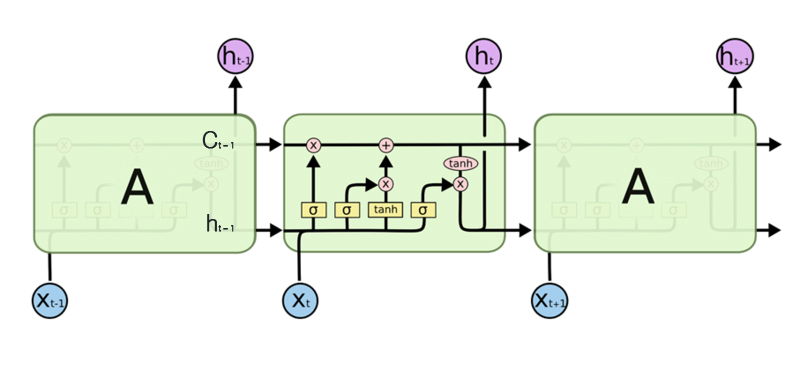
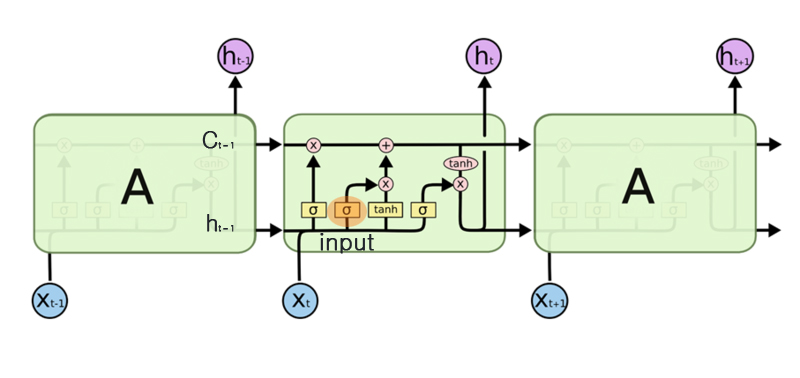
기존 RNN 계층의 기울기 소실 문제를 해결하기 위한 게이트를 추가한 것이 바로 LSTM이다. LSTM은 기울기 소실이 일어나기 매우 어려운 구조로 되어있기 때문에 대부분의 시계열 데이터 처리의 가장 기본으로 LSTM을 주로 사용한다.
σ 는 Sigmoid 함수를 의미한다.
기억 셀(memory cell)
LSTM은 은닉 벡터인 h뿐만 아니라 c라는 경로도 있다. c를 기억 셀(memory cell)이라 하며, LSTM 전용의 기억 메커니즘이다. 기억 셀의 특징은 은닉 벡터인 h와 다르게 데이터를 LSTM 계층 내에서만 주고받고 다른 계층으로는 출력하지 않는다는 것이다. ct는 시각 과거부터 시각 t까지에 필요한 모든 정보가 저장되어 있다. ct는 은닉 상태 ht의 계산에 사용되기 때문에(ht=tanh(ct)) 은닉 상태와 기억 셀의 원소 수는 동일하다.
LSTM을 구성하는 다양한 게이트들을 설명하기에 앞서 게이트의 정의에 대해 설명하도록 하겠다. 게이트는 데이터의 흐름을 제어하는 역할을 한다. LSTM에 사용하는 게이트는 열기, 닫기 뿐만 아니라 어느 정도의 데이터를 흘려 보낼지에 대한 제어도 할 수 있다. 이것 역시 데이터로부터 자동으로 학습되는 정보이다. 게이트는 게이트의 열림 상태를 제어하기 위해 전용 가중치 매개변수를 이용하며, 이 가중치 매개변수는 학습 데이터로부터 갱신된다. 게이트의 열림 상태를 제어하는 것을 학습하는데 사용되는 함수는 Sigmoid 함수이다.
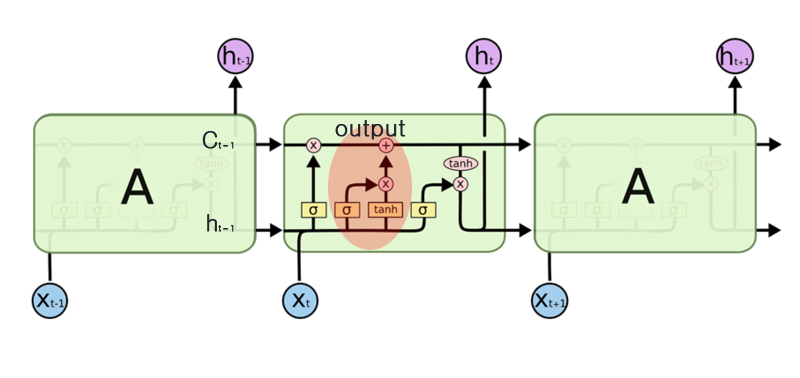
output 게이트
ouput 게이트
output 게이트는 ht(=tanh(ct))의 각 원소에 대해 그것이 다음 시각의 은닉 상태에 얼마나 중요한가를 조정한다. 즉, 데이터를 얼마나 흘려보낼지를 결정하는 게이트이다. output 게이트의 열림 상태는(몇 %를 흘려보낼까) 입력 xt와 이전 상태 ht-1로부터 구한다.
output 게이트 수식
이 output 게이트 식과 tanh(c)의 원소별 곱(아마다르 곱)은 h로 출력된다.
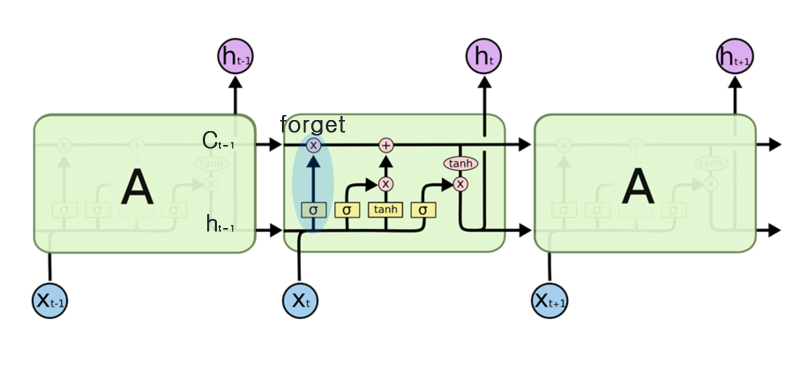
forget 게이트
forget 게이트는 기억셀이 불필요한 기억을 잊도록 돕는 게이트이다.
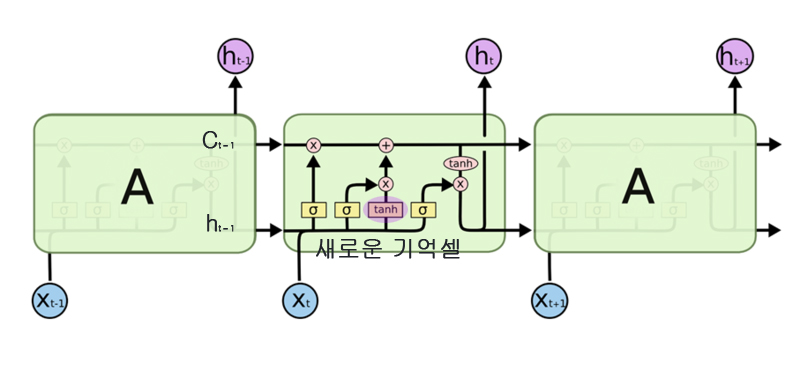
새로운 기억 셀
forget 게이트를 거치면서 이전 시각의 기억 셀로부터 잊어야 할 기억이 삭제된 후, 새로 기억해야 할 정보를 기억셀에 추가해야 한다. 이를 위해 우리는 tanh 노드를 추가한다. tanh 노드가 계산한 결과가 이전 시각의 기억 셀(ct-1)에 더해진다. 이는 기억 셀에 새로운 정보를 추가하는 것으로, 여기서 사용되는 tanh는 게이트가 아니다. tanh를 사용하는 목적은 기억 셀에 새로운 정보를 추가하는 것이 목적이다. 따라서 새로운 기억셀에 대한 식은 다음과 같다.
g는 새로운 기억으로 이전 시각의 기억 셀인 ct-1에 더해진다.
input 게이트
input 게이트는 새로운 기억인 g에 추가하는 게이트로, g의 각 원소가 새로 추가되는 정보로써의 가치가 얼만큼인지를 판단한다. 새 정보를 무비판적으로 수용하는 것이 아니라, 적절히 선택하는 것이 이 게이트의 역할이다.
결론적으로 LSTM은 기존의 RNN과 달리 기억 셀이라는 것이 존재하고 이 기억 셀을 잘 활용하기 위해 output, forget, input 게이트가 사용된다. 이 기억 셀은 역전파시 +와 x노드만을 지나고, +노드는 역전파시 상류에서 전해지는 기울기를 그대로 흘리기 때문에 기울기 소실이 발생하지 않으며 기억 셀에서 사용되는 x노드는 행렬 곱이 아닌 원소별 곱이기 때문에 매번 새로운 게이트 값을 이용하므로 곱셈 효과가 누적되지 않아 기울기 소실이 발생하지 않는다.
LSTM의 x노드는 forget 게이트가 제어하며, forget 게이트가 잊어야 한다고 판단한 기억 셀의 원소에 대해서는 기울기값이 작아지고 잊지 말아야 한다고 판단한 기억 셀의 원소에 대해서는 기울기 소실 없이 그대로 전파된다.
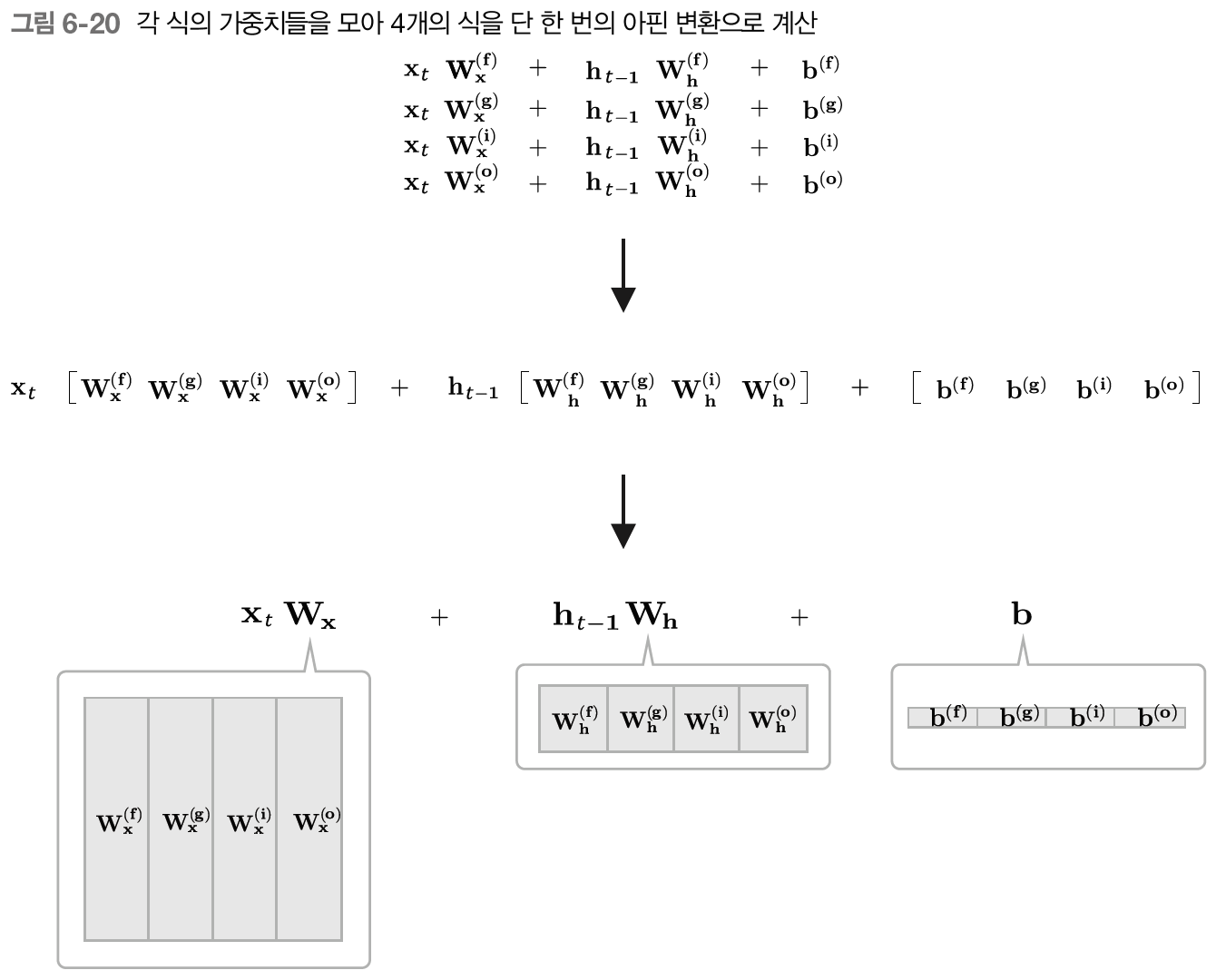
LSTM에 사용되는 게이트들의 식을 보면 다음과 같이 4개의 가중치(또는 편향)를 하나로 모을 수 있고, 원래 별개로 4번의 계산을 수행해야 했던 것이 단 1회의 계산만으로 동일한 결과를 얻을 수 있게 된다.
추가적으로 RNN의 개선방안에 대해 간략하게 이야기하고 넘어가겠다.
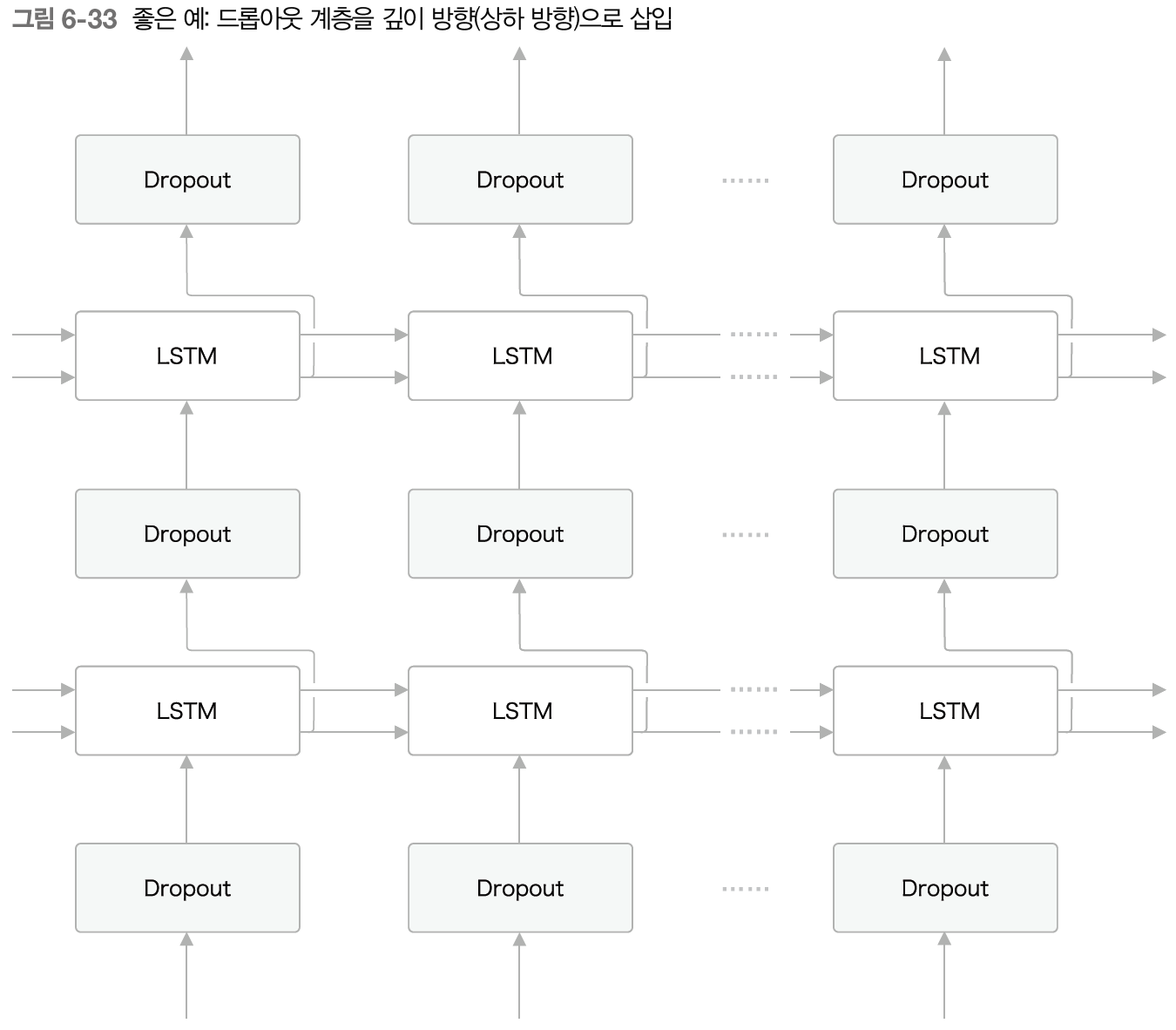
RNN도 여타 신경망과 같이 overfitting의 문제가 발생한다. 이를 해결하기 위해서는 훈련 데이터의 양 늘리기와 모델의 복잡도 줄이기, 정규화, 드롭아웃(drop out)이 있다. 이 중에서 드롭아웃에 대해 살펴보면, RNN에서는 dropout 계층을 어디에 삽입해야할까? 정답은 상하 방향으로 삽입하는 방법이다.
dropout 계층 사용의 좋은 예
이렇게 상하 방향으로 드롭아웃을 삽입하는 이유는 드롭아웃을 시계열 방향으로 삽입하면 학습 시 시간이 흐를수록 드롭아웃에 의한 노이즈가 축적되어 정보가 사라질 수 있기 때문이다. 상하 방향으로 드롭아웃을 삽입하면 시간 방향(좌우 방향)에 영향을 주지 않는다.
하지만 의지의 인간은 기존의 드롭아웃 말고 새로운 드롭아웃을 만들어 시간 방향에도 드롭 아웃을 사용할 수 있게 했는데 자세한 내용은 여기를 참고하길 바란다.
또한 가중치 공유는 RNN의 성능을 높이는데 큰 도움을 준다. Embedding 계층의 가중치와 Affine 계층의 가중치를 연결하는 방법인 가중치 공유는 두 계층의 가중치를 공유함으로써 학습하는 매개변수 수가 크게 줄어드는 동시에 정확도도 향상된다.
이로써 LSTM에 대한 설명은 끝이 났다. 필자가 처음에 LSTM을 공부할 땐 제대로 이해가 안갔는데 3번 정도 읽으니 이해가 갔다.(ㅠㅠ) 모두들 힘내봅시다!
이전에 소개했던 word2vec은 기존의 자연어 처리 방법보다 효과적이지만, 치명적인 단점이 존재하는데 맥락이 길어지면 길어질수록 그와 비례해 가중치 매개변수가 늘어나 연산량이 늘어난다는 점이다. 이 문제 때문에 우리는 결국 엄청난 말뭉치의 데이터를 학습하는데 어려움을 겪게 된다. 이 단점의 근본적인 원인은 우리가 이전에 배웠던 신경망들은 전부 feed forward 유형의 신경망이었기 때문이다. feed forward란 흐름이 단방향인 신경망을 의미하고 feed forward는 시계열 데이터의 성질(패턴)을 충분하게 학습할 수 없다.
그 이유를 간단하게 말하자면 feed forward 방식은 단방향의 신경망으로, 흐름을 따라갈수만 있지 기억할 수 없기 때문이다. 자연어나 기타 시계열 데이터는 데이터의 흐름성을 기억하며 그 흐름성의 특징을 기억해야하기 때문에 기존의 feed forward 방식의 신경망으로는 시계열 데이터를 다룰 수 없다. 따라서 우리는 시계열 데이터를 처리할 때 RNN이라는, 직역하면 순환 신경망인 신경망을 사용한다.
RNN(Recurrent Neural Network)
RNN은 기존의 feed forward방식의 한계점을 개선하고자 순환하는 경로가 있다. 순환하는 경로가 뭐고 왜 필요한걸까? 순환하는 경로는 다른 말로 닫힌 경로라고도 불리며, 이 경로가 존재해야 데이터가 같은 장소를 반복해 왕래할 수 있고 그 데이터가 순환하며 과거의 정보를 기억하는 동시에 새로운 정보를 끊임없이 갱신할 수 있다.
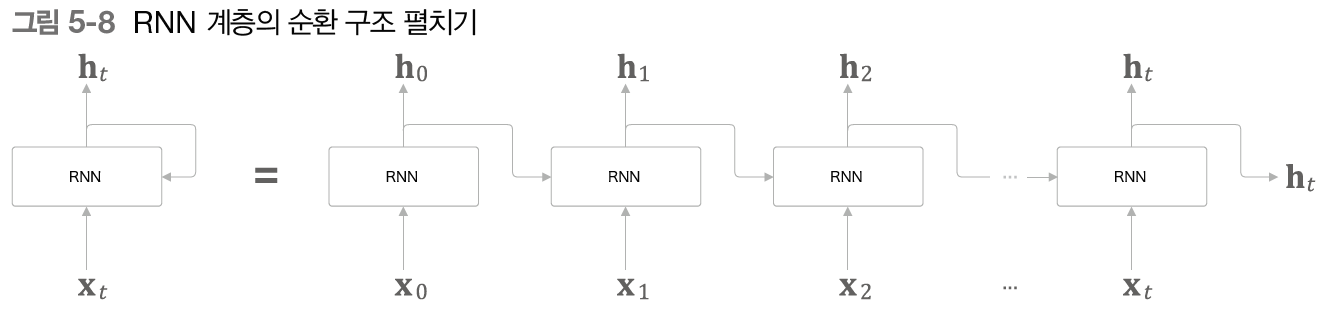
Xt는 RNN 계층에 입력되는 시계열 데이터를 의미하며 그 입력에 대응한 출력이 ht로 나오게 된다. Xt를 조금 더 자세히 설명하자면 문장 데이터인 경우, 각 단어의 분산 표현(단어 벡터)이 Xt가 되며, 이 분산 표현이 순서대로 하나씩 RNN 계층에 입력됨을 의미한다. 위의 계층은 결론적으로 오른쪽으로, 즉 한 방향으로 뻗어나가는 구조를 갖고, 이는 feed forward 신경망과 같은 구조이나 각 RNN 계층이 그 계층으로의 입력(X1)과 전의 RNN 계층으로부터의 출력(h0)을 받아 두 정보를 바탕으로 현 시각의 출력을 계산한다.
이때문에 RNN 의 가중치는 2개인데 하나는 입력 x를 출력 h로 변환하기 위한 가중치 Wx이고 하나는 RNN 출력을 다음 시각의 출력으로 변환하기 위한 가중치 Wh이다. 위의 이미지를 보면 각 RNN의 계산 결과인 ht는 출력이 되면서 다음 RNN 계산에 입력되는데, 이 ht는 각 RNN의 출력 결과물로 상태를 의미한다. 따라서 RNN 계층을 상태를 갖는 계층 혹은 메모리(기억력)가 있는 계층이라고 표현한다. 또한 RNN의 출력 ht는 은닉 상태 또는 은닉 상태 벡터라고도 한다.
BPTT(Backpropagation Through Time)
위의 이미지와 같이 순환 구조를 펼친 후의 RNN에는 일반적인 오차역전파법을 적용할 수 있다. 이를 시간 방향으로 펼친 신경망의 오차역전파법이라는 뜻으로 BPTT라고 한다. 우리는 BPTT를 통해 RNN을 학습할 수 있게 되는데, 긴 시계열을 학습할 경우에는 메모리 사용량 증가 및, 시간 크기가 커질수록 기울기가 불안정하다는 문제점이 발생한다. 이를 해결하기 위한것이 바로 Truncated BPTT기법이다.
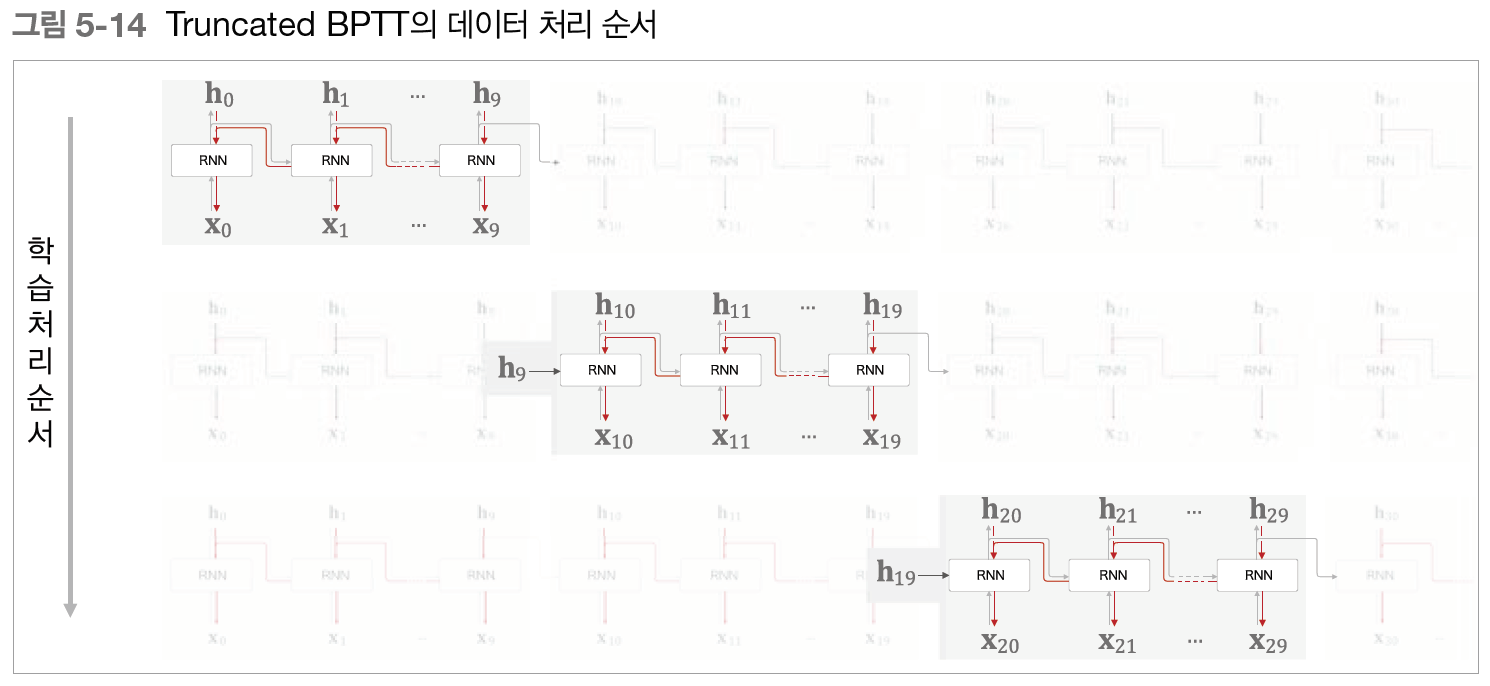
Truncated BPTT
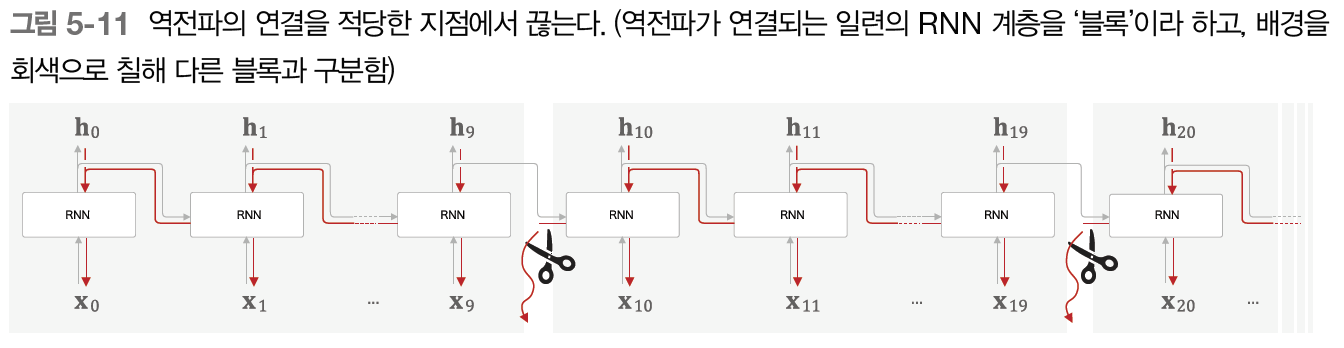
시간축 방향으로 너무 길어진 신경망을 적당한 지점에서 잘라내어 작은 신경망 여러 개로 만든다는 아이디어를 사용하여, 잘라낸 작은 신경망에서 오차역전파법을 수행하면 기존 BPTT에서 발생할 수 있는 문제점을 해결할 수 있다. Truncated BPTT는 순전파는 그대로 유지하고(계속 연결됨) 역전파의 연결만 끊는다.
Truncated BPTT 또한 미니배치 학습을 진행할 수 있는데, 미니배치 학습 수행을 할 경우, 데이터를 제공하는 시작 위치를 각 미니배치(각 샘플)로 옮겨준 후 순서대로 제공하면 된다. 또한 데이터를 순서대로 입력하다 끝에 도달하면 다시 처음부터 입력하도록 하여 RNN의 특징을 살리면서 미니배치 학습을 할 수 있다. Truncated BPTT는 긴 시계열 데이터 학습 시 메모리 사용량 증가와 기울기 불안정 문제를 해결하기 위해 역전파의 경우에만 신경망을 일정하게 끊어 역전파를 구하는 방법이다. 이 Truncated BPTT는 데이터를 순서대로 제공하는 것과 미니배치별로 데이터를 제공하는 시작 위치를 옮기는 것이 데이터 제공 면에서 가장 중요하다.
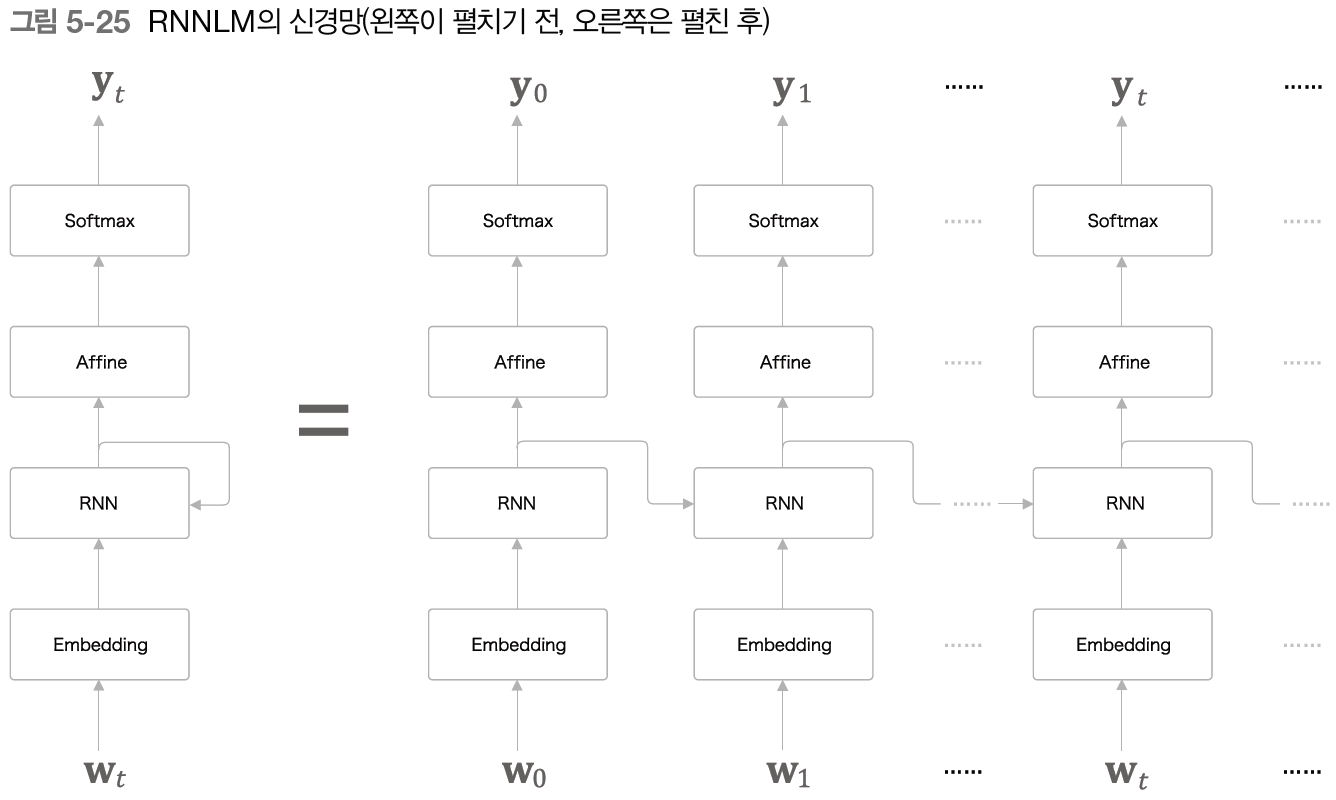
위의 그림은 RNN Language Model(RNNLM)로, 자연어를 처리하는 RNN이라고 보면 된다. 단어ID인 Wt가 들어가 Embedding 계층을 통해 단어의 분산 표현(딴어 벡터)으로 변환된다. 이 분산 표현이 RNN에 들어가고 RNN의 출력 데이터는 은닉상태(ht)를 Affine층으로 출력함과 동시에, 다음 시각의 RNN 계층으로 출력하게 된다.
RNN을 이용하여 자연어를 처리(RNNLM)하면 이전에 설명했던 word2vec 신경망과는 달리 이전의 데이터에 대한 정보도 기억하고 있다. RNN은 과거의 정보를 응집된 은닉 상태 벡터(ht)로 저장해두고 있다. 이 정보를 Affine 계층에, 그리고 다음 시각의 RNN 계층에 전달하는 것이 RNN 계층이 하는 일이다.
이러한 RNNLM은 지금까지 입력된 단어를 '기억'하고, 그것을 바탕으로 다음에 출현할 단어를 예측한다. 이것이 가능한 이유는 RNN 계층이 과거에서 현재로 데이터를 계속 흘려보내주기 때문에 과거의 정보를 인코딩해 저장(기억)할 수 있기 때문이다.
언어 모델은 주어진 과거 정보(단어)로부터 다음에 출현할 단어의 확률분포를 출력한다. 이 때 언어 모델의 예측 성능을 평가하는 척도로 퍼플렉서티(Perplexity,혼란도)를 자주 사용한다. 퍼플렉서티는 확률의 역수로, 퍼플렉서티가 작으면 작을수록 좋은 모델이다. 이것에 대해 조금 더 자세히 말하자면, 퍼플렉서티는 분기수로 해석할 수 있으며 이 말은 퍼플렉서티가 1에 가까우면 단어의 후보가 1개라는 의미이고, 퍼플렉서티가 5이면 단어의 후보가 5개라는 의미이다. 따라서 퍼플렉서티가 작으면 작을수록 분기수, 즉 단어의 후보 수도 적기 때문에 좋은 모델이 된다.