NLP(Natural Language Processing)
NLP란 자연어 처리를 의미하며, 이는 인간의 언어를 컴퓨터에게 이해시키기 위한 기술이라고 생각하면 된다. 어떻게 인간의 언어를 컴퓨터에게 이해시킬 수가 있을까? 우선 언어를 이해시키기 위해서는 언어를 구성하면서 의미가 있는 가장 작은 단위인 '단어'에 대해 이해해야 한다. 어떻게 하면 컴퓨터가 '단어의 의미'를 이해할 수 있을까? 이 방법을 알기 위해서 우선 우리는 자연어 처리에 대한 역사에 대해 알 필요가 있다.
시소러스
'단어의 의미'를 나타내는 방법으로 가장 쉽지만 가장 비효율적인 것은 국어사전과 같이 '사람이 직접 단어의 의미를 정의하는 방식'이다. 시소러스는 정확히는 유의어 사전으로, '뜻이 같은 단어(동의어)'나 '뜻이 비슷한 단어(유의어)'가 한 그룹으로 분류되어 있다. 또한 자연어 처리에 이용되는 시소러스는 단어 사이의 '상위와 하위' 혹은 '전체와 부분' 등, 세세한 관계까지 정의해둔 경우도 있다. 이처럼 모든 단어에 대한 유의어 집합을 만든 후, 단어간의 연결을 정의하면 이러한 네트워크를 통해 컴퓨터는 단어 사이의 관계를 이해할 수 있다.
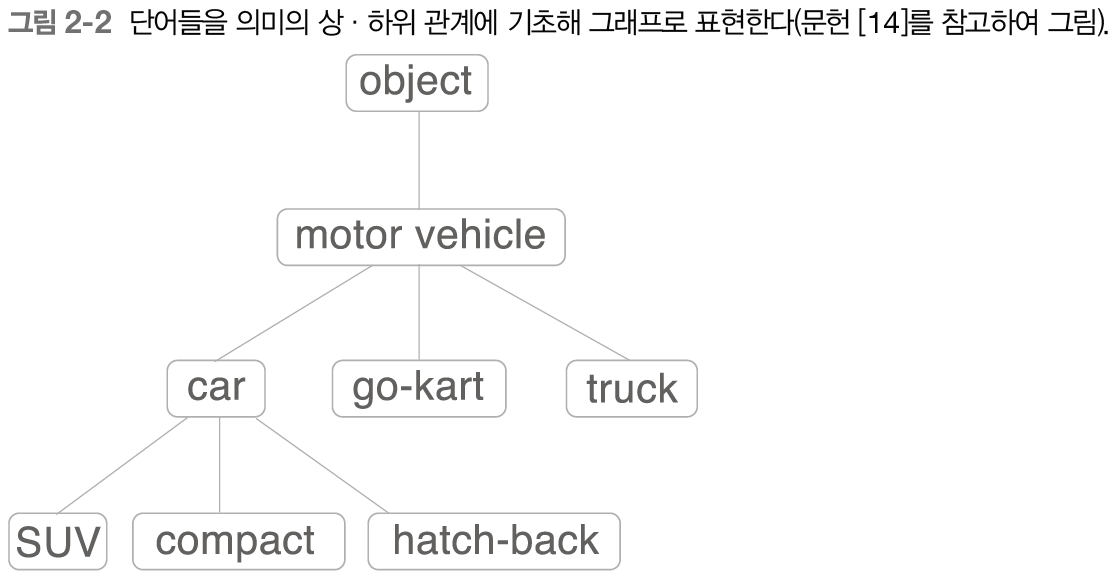
WordNet은 자연어 처리 분야에서 가장 유명한 시소러스로, 프린스턴 대학교에서 1985년부터 구축하기 시작하여 현재까지 많은 연구와 다양한 자연어 처리 애플리케이션에서 활용되고 있다. WordNet은 앞서 설명했던 단어 네트워크를 이용할 수 있으며 단어 간의 유사도를 구할 수 있다.
시소러스의 단점
하지만 시소러스의 문제점은 치명적인 단점이 존재한다.
우선적으로 시대 변화에 대응하기 어렵다는 것이다. 이에 대해 간단히 설명하자면 최근에 새롭게 생긴 단어인 내로남불, 창렬, 혜자와 같은 단어에 대해서 사람이 직접 입력하기 전까지 이해하지 못한다는 것이다.
두번째로는 사람을 쓰는 비용이 크다는 것이다. 위의 '시대 변화에 대응하기 어렵다'는 단점에 대한 해결책으로 사람이 일일이 새롭게 생겨난 단어에 대해 입력해줘야하는데, 그러기엔 너무나 단순 노동 뿐만 아니라 인건비가 많이 든다.
세번째로는 단어의 미묘한 차이를 표현할 수 없다. 이에 대한 예시로는 우리나라의 대표적인 만능 문자 '헐'이 있겠다. 사람들은 단순히 문자로 되어있는 글에서도 '헐'의 의미를 유추하고 파악할 수 있으나 시소러스로는 '헐'의 미묘한 차이를 이해할 수 없다.
통계 기반 기법
위의 시소러스의 단점들을 해결하고자 새롭게 만들어 낸 방법이 통계 기반 기법이다. 통계 기반 기법은 특정 단어를 주목했을 때, 그 주변에 어떤 단어가 몇 번이나 등장하는지를 세어 집계하는 방법이다. 이에 대한 이해를 하기 위해서는 앞으로 내가 기술할 내용들의 흐름을 따라가야 한다. 우리는 통계 기반 기법에서 '말뭉치(corpus)'라는 것을 사용하게 된다. 말뭉치란 자연어 처리 연구나 애플리케이션을 염두에 두고 수집된 대량의 텍스트 데이터를 의미한다. 말뭉치에 담긴 문장들을 보면 문장을 쓰는 방법, 단어 선택 방법, 단어의 의미 등 자연어에 대한 사람의 '지식'이 담겨져 있다. 통계 기반 기법은 결론적으로 사람의 지식으로 가득한 말뭉치에서 자동으로, 그리고 효율적으로 핵심을 추출하고자 하는 기법이다.
말뭉치를 처리하고자 하는 코드적인 부분인 여기를 참고하길 바란다. 간략하게 말하자면 자연어는 순서와 흐름이 존재하므로 ('나는 너를 싫어한다.' 와 '너는 나를 싫어한다.' 의 의미가 다른 이유는 나와 너의 위치의 차이이며, 이는 자연어에서 중요한 특징이다.) 이 순서를 기억하기 위해서 문장을 구성하는 단어들을 순서(단어ID)와 단어에 대한 정보를 각각 저장하는(단어ID->단어, 단어->단어ID) 딕셔너리로 만들어 저장한다.
여기서 잠깐 생각해보면 아무리 말뭉치고 뭐고 생각을 해도 컴퓨터가 자연어를 이해한다는게 이해되지 않지 않는가? (뭔 말장난 같은 문장이여) 컴퓨터는 숫자, 근본적으로는 0과 1을 이해하는 숫자충(충실할 충)이고 자연어는 지극히 언어적이다. 이런 완전히 반대되는 녀석을 어떻게 숫자충인 컴퓨터가 이해할까? 그러기 위해서는 당연하게도 컴퓨터가 이해할 수 있도록 자연어를 처리해야한다. 그 말은 즉, 단어를 숫자로 바꿔야한다는 의미이다. (정말 충격적이지 않은가?! 말이 쉽지 이걸 그래서 어떻게 하는데) 따라서 우리는 단어의 의미를 정확하게 파악할 수 있도록 단어를 벡터로 표현해야 하고 이를 '단어의 분산 표현'이라고 한다.
분포 가설
단어를 벡터로 표현하기 위해서는 어떻게 해야할까? 이를 위해 우리는 이 사실을 알아야 한다. 단어의 의미는 주변 단어에 의해 형성이 된다는 것이다. 이를 분포 가설이라고 하며, 이 분포 가설이 의미하는 바는 매우 간단하다. 단어란, 그 자체에는 의미가 없고, 그 단어가 사용된 맥락(context)이 의미를 형성한다는 것이다. 이를 쉽게 이해하려면 간단히 '헐'을 떠올리면 된다. (이하 설명은 생략하겠다. 한국인이라면 충분히 이해할 수 있다.)

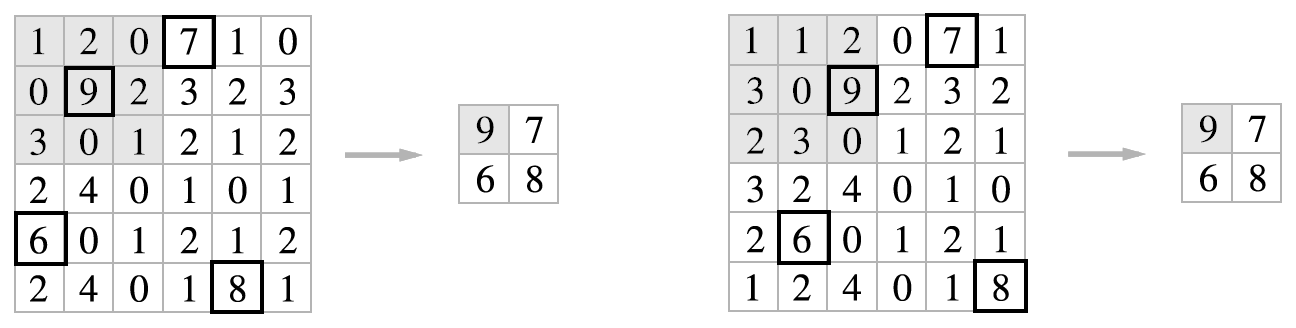
위의 이미지에서 설명하는 내용은 window size에 대한 내용이다. window size란 '맥락의 크기'를 의미하며 '맥락'이란 특정 단어를 중심에 둔 주변 단어들을 의미한다. 따라서 위의 경우에서 windwo size가 1인 경우는 say와 and가 goodbye의 맥락이다. window size가 2인 경우는 you,say,and,i가 goodbye의 맥락이 된다. 이러한 맥락을 벡터로 나타내는 것을 우리는 '동시발생 행렬'이라고 한다.
동시발생 행렬
이에 대한 설명은 아래의 이미지를 통해 직관적으로 이해하고 넘어가겠다.
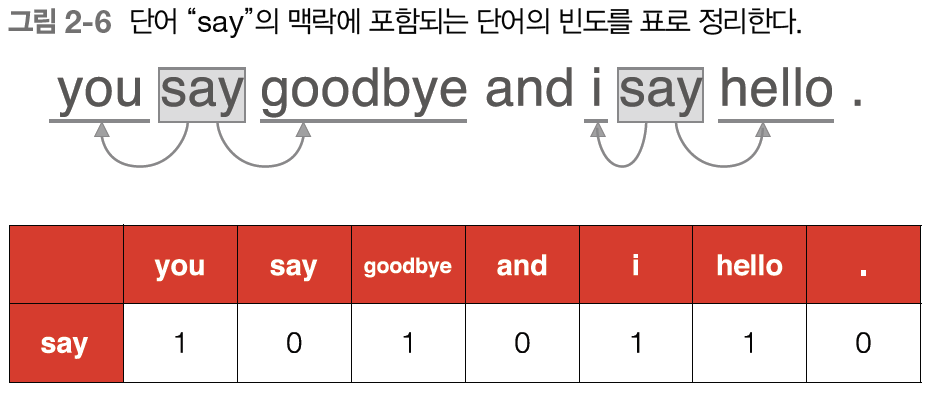
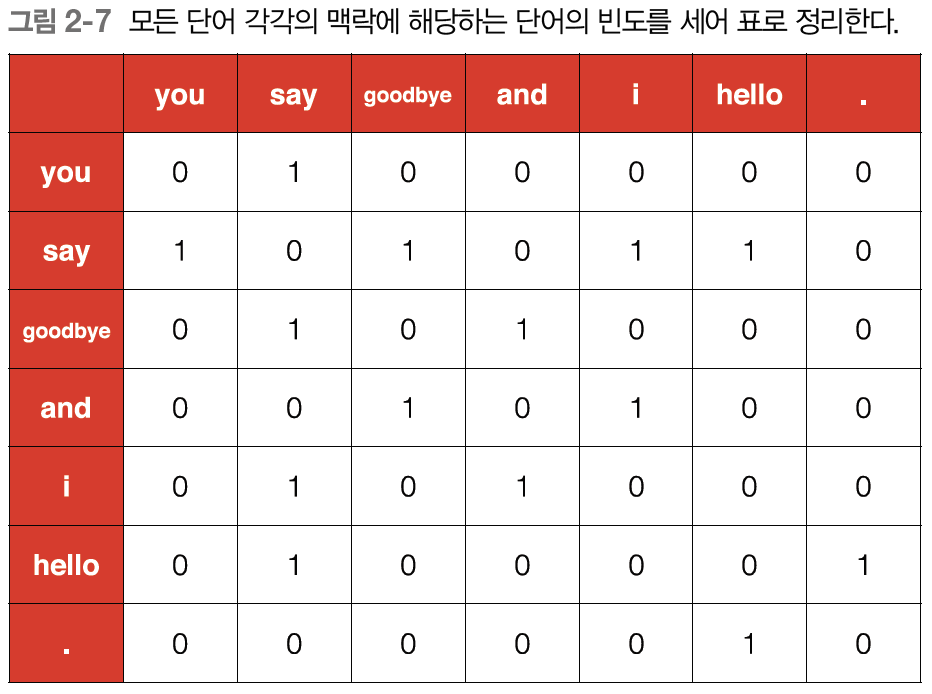
그림 2-7은 모든 단어에 대해 동시발생하는 단어를 표로 정리한 것이다. 이 표의 각 행은 해당 단어를 표현한 벡터가 되며, 이 표가 행렬의 형태를 띤다는 뜻에서 '동시발생 행렬'이라고 한다.
벡터 간 유사도
단어 벡터의 유사도를 나타낼 때는 코사인 유사도를 자주 이용한다. 코사인 유사도의 식은 아래와 같고, 코사인 유사도를는직관적으로 '두 벡터가 가리키는 방향이 얼마나 비슷한가'를 의미한다. 두 벡터의 방향이 완전히 일치한다면 1, 완전히 반대라면 -1이 된다.
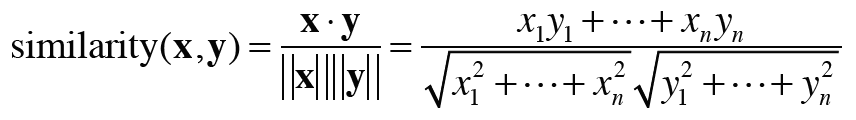
놀랍게도 이 코사인 유사도를 사용하면 유의어 및 반의어에 대해 컴퓨터가 이해한다. 이렇게 단어에 대한 네트워크를 이해하기 위해서는 큰 말뭉치가 필요하다. (역시 현대사회에선 다다익선)
PMI(상호정보량)
동시발생 행렬의 원소는 두 단어가 동시에 발생한 횟수를 나타낸다. 하지만 이것의 치명적인 단점이 있는데, 한국말에서는 조사, 영어에서는 관사가 이 단점의 원흉이다. 영어 문법을 보면 수량을 알기 위해서나 단어를 특정하기 위해 사용되는 a,an,the가 실제 명사(car) 다음에 오는 동사(drive)보다 동시발생 행렬의 개념('등장 횟수가 높을수록 관련성이 강함')에 의해 훨씬 관련성이 높게 나온다는 것이다. 결국 우리는 앞서 설명한 동시발생 행렬로 유의미한 단어의 관계성을 파악할 수 없다. 이를 해결하기 위한것이 PMI이다.
PMI란 점별 상호정보량이라는 척도로, 확률의 개념이 포함되어 단어의 연관성을 나타내는 행렬이다.
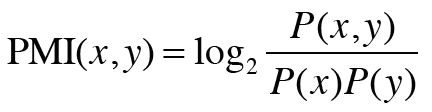
P(x)는 x가 일어날 확률을, P(y)는 y가 일어날 확률을, P(x,y)는 x와 y가 동시에 일어날 확률을 의미한다. 위의 식을 보면 PMI는 결론적으로 값이 높을수록 관련성이 높음을 의미한다. 이 식을 동시발생 행렬을 사용하는 식으로 바꾸면 다음과 같다.
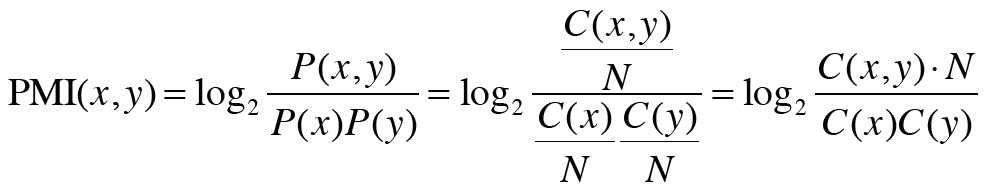
C는 동시발생 행렬이고 N은 말뭉치의 단어 수이며, C(x,y)는 단어 x,y가 동시에 발생하는 횟수, C(x)와 C(y)는 각각 단어 x와 y의 등장 횟수이다. PMI("the","car")의 수치와 PMI("car","drive")의 수치는 다음과 같이 연산되어 나타난다.
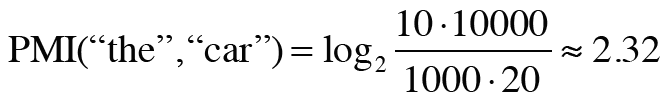
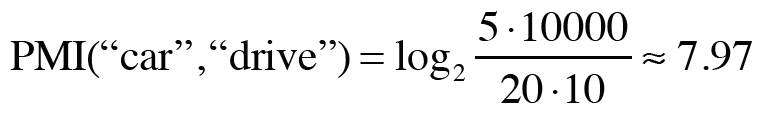
앞서 설명했던 동시발생 행렬의 단점을 완벽하게 보완한 모습을 볼 수 있다. 이렇게 계산이 될 수 있었던 것은 PMI는 단어가 단독으로 출현하는 횟수에 대해서도 고려되었기 때문이다. 관사인 a,an,the는 car 뿐만 아니라 다양한 단어와 함께 나오고, 많이 나온다. 그 모든 횟수를 고려하면 사실 the는 car와 그렇게 크게 관련성이 없다는 것을 알 수 있다.
이 PMI도 단점이 존재하는데, 바로 두 단어의 동시발생 횟수가 0이면 -inf가 된다는 점이다. 이 문제를 피하기 위해 실제 구현시에는 양의 상호정보량(PPMI)를 사용하며 식은 다음과 같다. 별 내용은 없다. PMI가 음수일 때 0으로 취급한다는 의미이다.
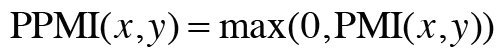
이 PPMI에 대해서도 또 문제점이 존재한다.(완벽이란 없어...^^) 말뭉치의 어휘 수가 증가함에 따라 각 단어 벡터의 차원 수도 증가한다는 문제이다. 즉, 말뭉치의 어휘 수가 10만개라면 벡터의 차원 수도 10만이 된다는 것이다. 또한 심지어 이 벡터의 대부분의 원소는 0이다. 결론적으로 벡터가 차원이 큰것 치고 실속이 없다는 얘기다. 이렇게 실속없고 등치만 큰 벡터는 노이즈에 약하며 견고하지 못하다. 이에 대한 문제를 해결하기 위해 우리는 차원 감소를 수행한다.
차원 감소는 말 그대로 벡터의 차원을 '중요한 정보'는 최대한 유지하며 줄이는 방법이다. 이 방법에 대해서는 특이값분해(SVD) 등 다양한 방법이 있다. 이에 대한 자세한 내용은 여기를 참고하길 바란다. 또한 내가 앞에서 설명했던 차원 감소 방법 중 하나인 주성분 분석(PCA)와 특이값분해(SVD)에 대한 차이점 및 설명에 대해서는 여기를 참고하길 바란다.
결론적으로 통계 기반 기법은 말뭉치로부터 단어의 동시발생 행렬을 만들고, PPMI 행렬로 변환한 후, 안전성을 높이기 위해 SVD를 이용해 차원을 감소시켜 각 단어의 분산 표현을 만들어 낸다.
놀랍게도(ㅠㅠ) 아직 단어의 분산 표현을 만드는 방법을 다 설명하지 않았다.
단어의 분산 표현을 만드는 방법인 또 하나의 방법인 '추론 기반 기법'에 대해서는 다음에 설명하도록 하겠다.
'인공지능 > 인공지능 이론' 카테고리의 다른 글
| 27. RNN(순환 신경망) (0) | 2020.10.05 |
|---|---|
| 26. 자연어 처리 2) 단어의 분산 표현 얻는 방법 - 추론 기반 기법(word2vec) (0) | 2020.10.04 |
| 24. im2col 이해하기 - Pooling Layer (0) | 2020.08.13 |
| 23. im2col 이해하기 - 합성곱 계층(Convolution Layer) (4) | 2020.08.12 |
| 22. 딥러닝, 전이학습, 강화학습 (0) | 2020.08.10 |