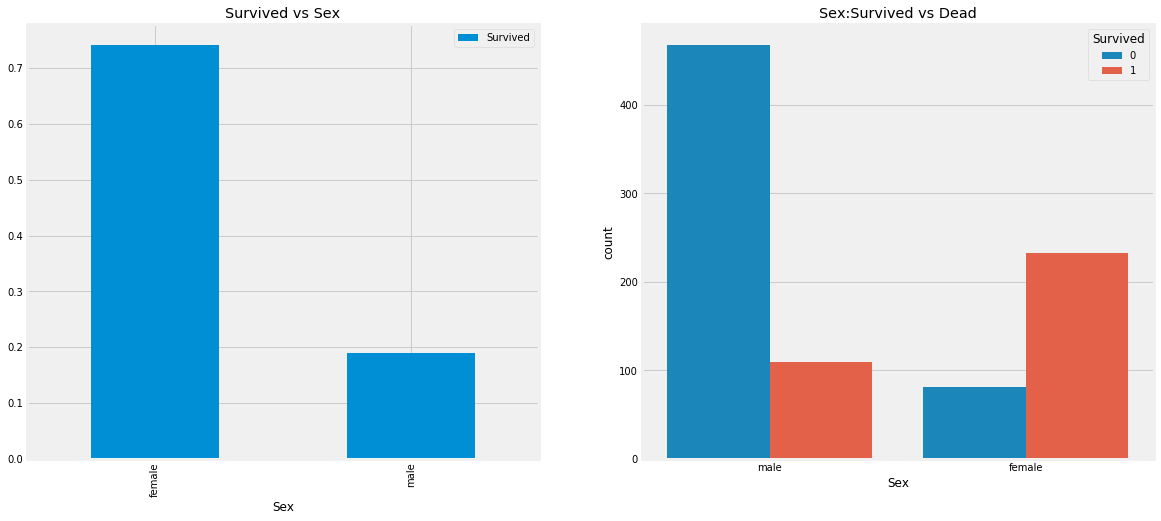
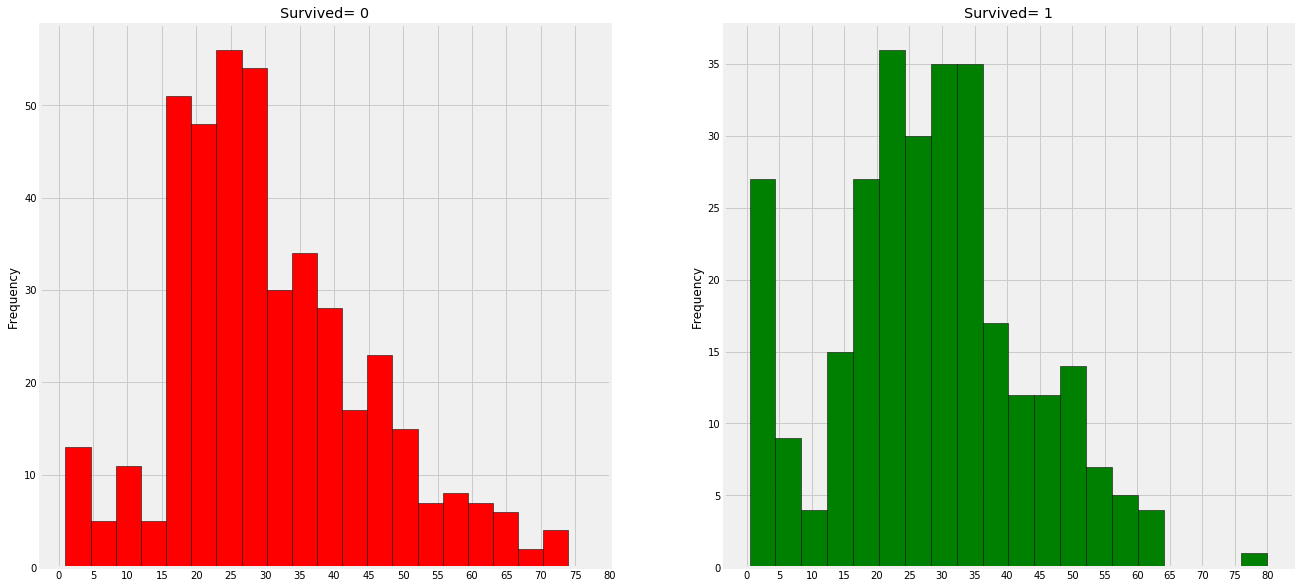
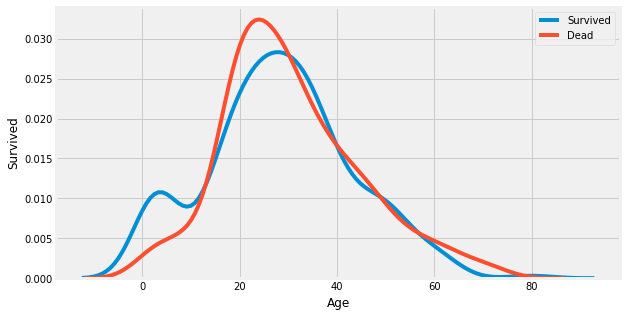
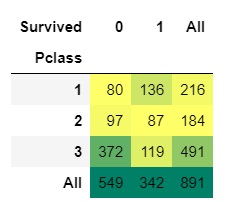
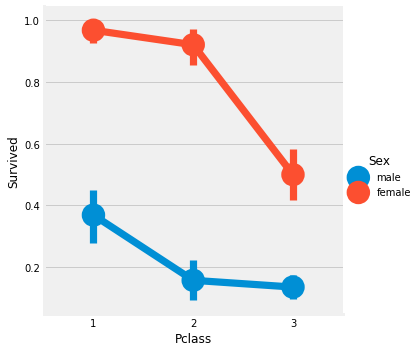
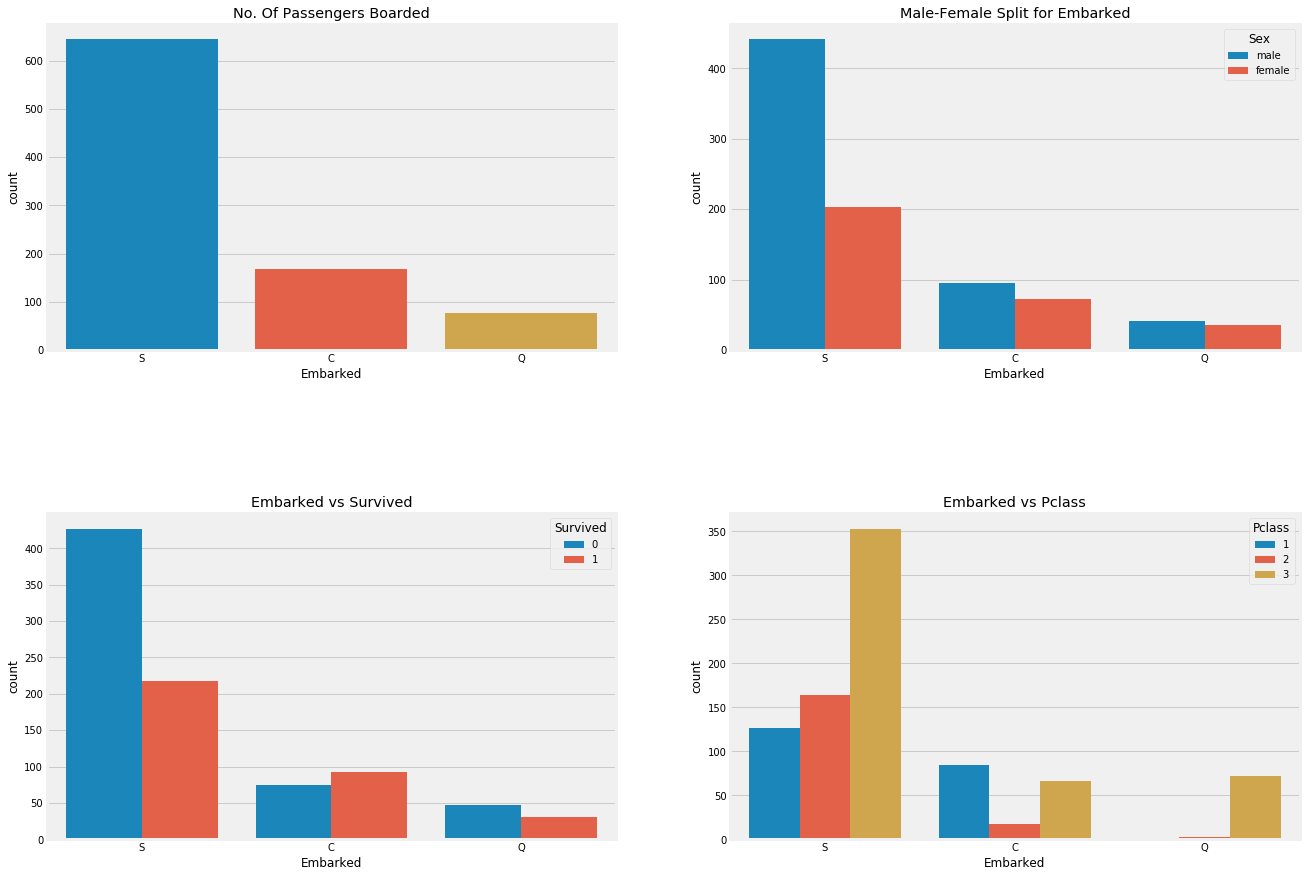
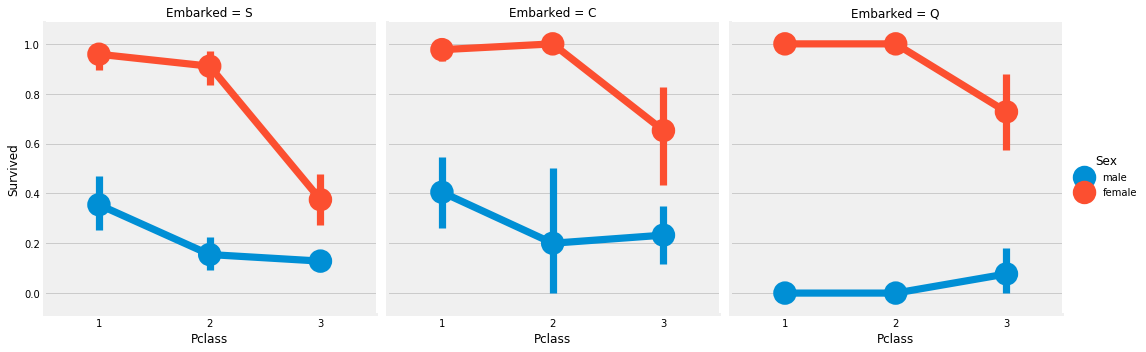
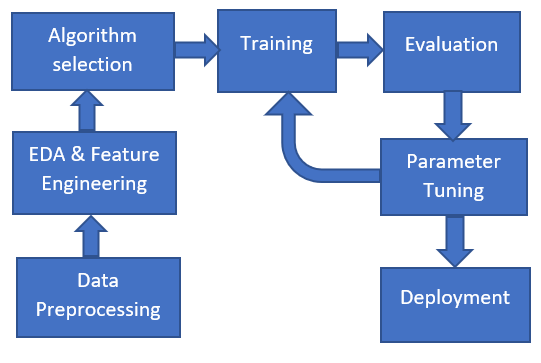
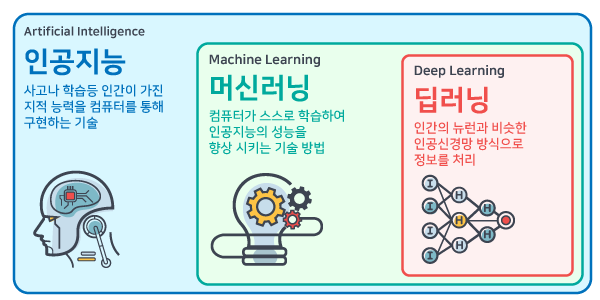
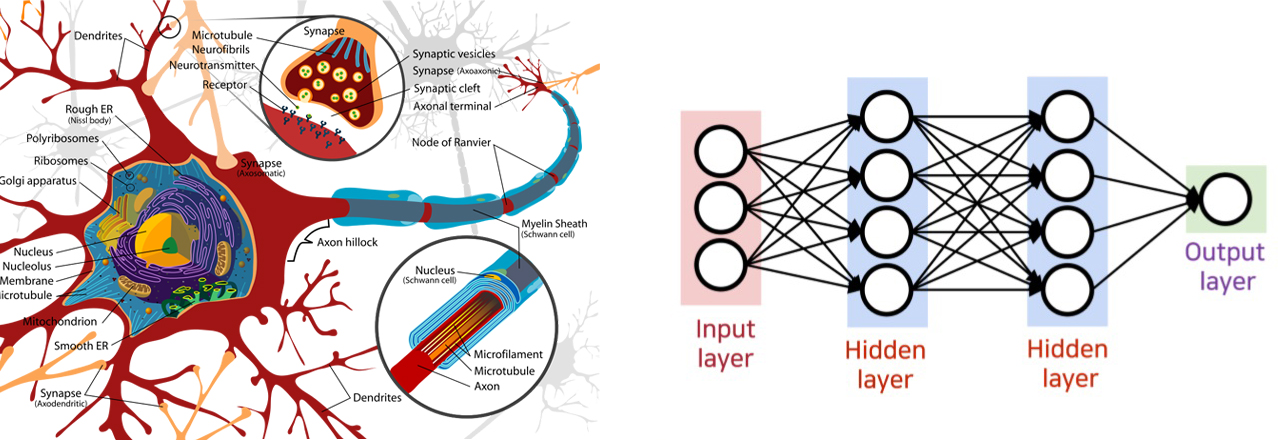
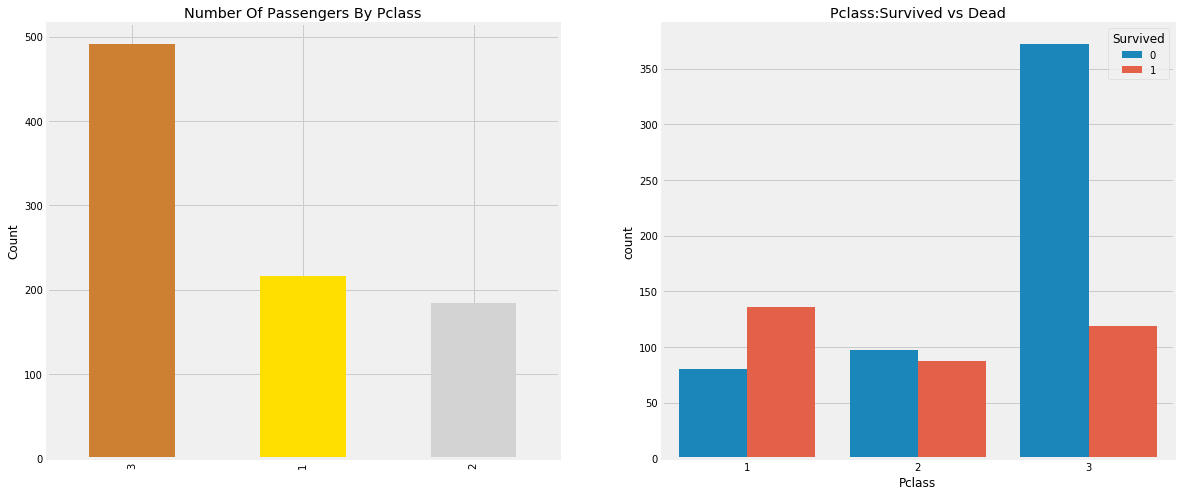3. Predictive Modeling
참고하고 있는 이 옹골찬 케글은 학습 모델을 무려 7가지나 사용해준다. 킹갓이 아닐 수 없다. 나같은 초짜에게는 다양한 예시가 제일 이해도를 높여준다. 하지만 지금까지 머신러닝 Workflow만 설명한 것 치고는 꽤나 어려운 주제라고 할 수 있겠다. 따라서 앞으로 여기서 사용한 학습 모델을 설명하는 글을 작성할 때마다 링크를 걸어 두겠다. 일단 지금은 이런 것들이 있다, 이렇게 학습시킨다 정도로 알고 넘어가자.
from sklearn.model_selection import train_test_split #training and testing data split
from sklearn import metrics #accuracy measure
train,test=train_test_split(train_data,test_size=0.3,random_state=0,stratify=train_data['Survived'])
train_X=train[train.columns[1:]]
train_Y=train[train.columns[:1]]
test_X=test[test.columns[1:]]
test_Y=test[test.columns[:1]]
X=train_data[train_data.columns[1:]]
Y=train_data['Survived']
1)Logistic Regression
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(train_X,train_Y)
prediction3=model.predict(test_X)
print('The accuracy of the Logistic Regression is',metrics.accuracy_score(prediction3,test_Y))The accuracy of the Logistic Regression is 0.8134328358208955
2)Support Vector Machines(Linear and radial)
- Linear Support Vector Machine (linear-SVM)
from sklearn import svm
model=svm.SVC(kernel='linear',C=0.1,gamma=0.1)
model.fit(train_X,train_Y)
prediction1=model.predict(test_X)
print('Accuracy for linear SVM is',metrics.accuracy_score(prediction1,test_Y))Accuracy for linear SVM is 0.8171641791044776
- Radial Support Vector Machine (rbf-SVM)
model=svm.SVC(kernel='rbf',C=1,gamma=0.1)
model.fit(train_X,train_Y)
prediction2=model.predict(test_X)
print('Accuracy for rbf SVM is ',metrics.accuracy_score(prediction2,test_Y))Accuracy for rbf SVM is 0.8022388059701493
3)Random Forest
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(n_estimators=100)
model.fit(train_X,train_Y)
prediction7=model.predict(test_X)
print('The accuracy of the Random Forests is',metrics.accuracy_score(prediction7,test_Y))The accuracy of the Random Forests is 0.7873134328358209
4)K-Nearest Neighbours (KNN)
from sklearn.neighbors import KNeighborsClassifier
model=KNeighborsClassifier()
model.fit(train_X,train_Y)
prediction5=model.predict(test_X)
print('The accuracy of the KNN is',metrics.accuracy_score(prediction5,test_Y))The accuracy of the KNN is 0.7873134328358209
n_neighbours 속성의 값을 변경하면 KNN 모델의 정확도도 바뀐다.
a_index=list(range(1,11))
a=pd.Series()
x=[0,1,2,3,4,5,6,7,8,9,10]
for i in list(range(1,11)):
model=KNeighborsClassifier(n_neighbors=i)
model.fit(train_X,train_Y)
prediction=model.predict(test_X)
a=a.append(pd.Series(metrics.accuracy_score(prediction,test_Y)))
plt.plot(a_index, a)
plt.xticks(x)
fig=plt.gcf()
fig.set_size_inches(12,6)
plt.show()
print('Accuracies for different values of n are:',a.values)
print("Max Accuracy ",a.values.max())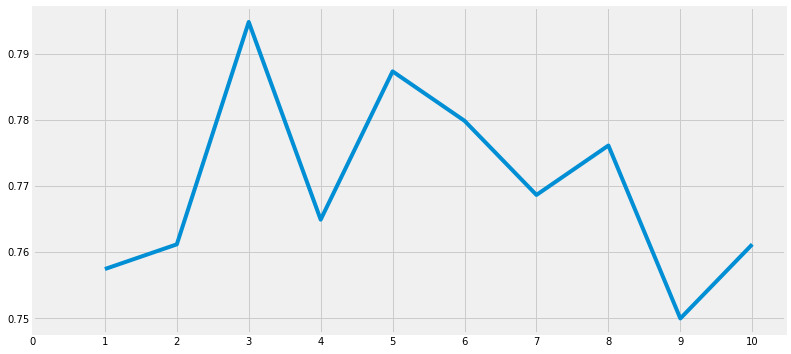
Accuracies for different values of n are: [0.75746269 0.76119403 0.79477612 0.76492537 0.78731343 0.77985075
0.76865672 0.7761194 0.75 0.76119403]
Max Accuracy 0.7947761194029851
5)Naive Bayes
from sklearn.naive_bayes import GaussianNB
model=GaussianNB()
model.fit(train_X,train_Y)
prediction6=model.predict(test_X)
print('The accuracy of the NaiveBayes is',metrics.accuracy_score(prediction6,test_Y))The accuracy of the NaiveBayes is 0.8171641791044776
6)Decision Tree
from sklearn.tree import DecisionTreeClassifier
model=DecisionTreeClassifier()
model.fit(train_X,train_Y)
prediction4=model.predict(test_X)
print('The accuracy of the Decision Tree is',metrics.accuracy_score(prediction4,test_Y))The accuracy of the Decision Tree is 0.7947761194029851
앞서했던 전처리와 EDA에 비해 함수가 매우 간략한 것을 알 수 있다. 사실 인공지능을 하다 보면 알고리즘을 돌려 정확도를 내는 것은 정말 쉽다. 단순히 함수만 사용하면 되니까 말이다. 하지만 이 함수들의 내용을 잘 알아야 함수를 설정할 때 사용자가 지정해야하는 파라미터들을 잘 설정할 수 있고 원하는 결과가 나오지 않았을 때 대체할만한 알고리즘을 선택할 수 있다. 하지만 일단 여기까지하자. 정확도가 높진 못하지만, 어쨌든 우리는 진짜 머신러닝을 해봤기 때문이다. 앞으로 더 공부하면서 차차 정확도를 높여가보고 여기에 쓰인 알고리즘은 어떤 원리로 동작되는지 알아가보자.
'인공지능 > 인공지능 이론' 카테고리의 다른 글
| 7. 머신러닝종류 (0) | 2019.09.08 |
|---|---|
| 6. Train, Valid, Test Data / CrossValidation (교차 검증) (0) | 2019.08.27 |
| 4. 타이타닉 (2) / 전처리 (0) | 2019.08.22 |
| 3. 타이타닉 / EDA (탐색적 자료 분석) (0) | 2019.08.22 |
| 2. 머신러닝 진행과정 (0) | 2019.08.22 |