Netflix Movies and TV Shows
Movies and TV Shows listings on Netflix
www.kaggle.com
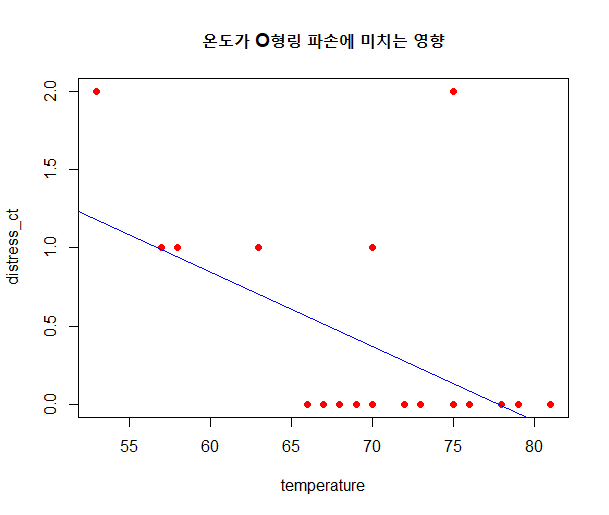
넷플릭스 데이터는 어떻게 구성되어 있는가?
# Anaconda Prompt (anaconda3) : pip install plotly
import plotly.graph_objects as go
from plotly.offline import init_notebook_mode, iplot
import pandas as pd
from plotly.subplots import make_subplots
df = pd.read_csv("c:/data/netflix_titles.csv")
df
넷플릭스에 있는 TV Show와 영화 비율
# September 9, 2019 형식을 모두 숫자 형식으로 변환해줌
df["date_added"] = pd.to_datetime(df['date_added'])
# type : 영화 / TV Show
col = 'type'
grouped = df[col].value_counts().reset_index()
grouped = grouped.rename(columns={col:"count","index":col})
# plot
trace = go.Pie(labels=grouped[col], values=grouped['count'], pull=[0.05,0],marker=dict(colors=['brown','cornflowerblue']))
layout = go.Layout(title=" ",height=400,legend=dict(x=0.1,y=1.1))
fig = go.Figure(data = [trace],layout=layout)
iplot(fig)
넷플릭스 컨텐츠 추가 추세 (선 그래프)
d1 = df[df["type"]=="TV Show"]
d2 = df[df["type"]=="Movie"]
# 년도만 사용
vc1 = d1["date_added"].dt.year.value_counts().reset_index()
vc1.columns = ['year','count']
vc1['percent'] = vc1['count'].apply(lambda x : 100*x/sum(vc1['count']))
vc1 = vc1.sort_values('year')
vc2 = d2["date_added"].dt.year.value_counts().reset_index()
vc2.columns = ['year','count']
vc2['percent'] = vc2['count'].apply(lambda x : 100*x/sum(vc2['count']))
vc2 = vc2.sort_values('year')
trace1 = go.Scatter(x=vc1['year'], y=vc1["count"],name="TV Shows",marker=dict(color='cornflowerblue'))
trace2 = go.Scatter(x=vc2['year'], y=vc2['count'],name="Movie",marker=dict(color='brown'))
data = [trace1,trace2]
layout = go.Layout(title="넷플릭스 컨텐츠 추가 증가 추세",legend=dict(x=0.1,y=1.1,orientation="h"))
fig = go.Figure(data,layout=layout)
fig.show()
넷플릭스 컨텐츠 추가 추세 (막대 그래프)
vc1 = d1["date_added"].dt.year.value_counts().reset_index()
vc1.columns = ['year','count']
vc1['percent'] = vc1['count'].apply(lambda x : 100*x/sum(vc1['count']))
vc1 = vc1.sort_values('year')
vc2 = d2["date_added"].dt.year.value_counts().reset_index()
vc2.columns = ['year','count']
vc2['percent'] = vc2['count'].apply(lambda x : 100*x/sum(vc2['count']))
vc2 = vc2.sort_values('year')
bar1 = go.Bar(x=vc1['year'],y=vc1['count'],name="TV Shows",marker=dict(color='cornflowerblue'))
bar2 = go.Bar(x=vc2['year'],y=vc2['count'],name='Movies',marker=dict(color='brown'))
data = [bar1,bar2]
layout = go.Layout(title="막대그래프로 보는 넷플릭스 컨텐츠 추가 증가 추세", legend=dict(x=0.1,y=1.1,orientation="h"))
fig = go.Figure(data,layout=layout)
fig.show()
넷플릭스 컨텐츠 추가 추세 (PIE 그래프)
df['year_added'] = df['date_added'].dt.year
k = round(df.groupby('year_added')['type'].value_counts(normalize=True)*100)
print(k)
k.reset_index(name='percent(%)')
d1 = df[df["type"]=="TV Show"]
d2 = df[df["type"]=="Movie"]
date = d1['date_added'].dt.year.value_counts().reset_index()
date2 = d2['date_added'].dt.year.value_counts().reset_index()
result = pd.merge(date,date2,how='outer',on='index').sort_values(by=['index'],ascending=False)
result.columns = ['year','TV Show','Movie']
result.index=[i for i in range(len(result))]
resultdata0 = {"values" : (result["TV Show"][0],result["Movie"][0]),
"labels" : ("TV Show","Movie"),
"domain" : {"row" : 0 , "column" : 0},
"name" : result["year"][0],
"hoverinfo" : "label+value+name",
"hole" : .4,
"type" : "pie"
}
data1 = {"values" : (result["TV Show"][1],result["Movie"][1]),
"labels" : ("TV Show","Movie"),
"domain" : {"row" : 1 , "column" : 0},
"name" : result["year"][1],
"hoverinfo" : "label+value+name",
"hole" : .4,
"type" : "pie"
}
data2 = {"values" : (result["TV Show"][2],result["Movie"][2]),
"labels" : ("TV Show","Movie"),
"domain" : {"row" : 2 , "column" : 0},
"name" : result["year"][2],
"hoverinfo" : "label+value+name",
"hole" : .4,
"type" : "pie"
}
data3 = {"values" : (result["TV Show"][3],result["Movie"][3]),
"labels" : ("TV Show","Movie"),
"domain" : {"row" : 0 , "column" : 1},
"name" : result["year"][3],
"hoverinfo" : "label+value+name",
"hole" : .4,
"type" : "pie"
}
data4 = {"values" : (result["TV Show"][4],result["Movie"][4]),
"labels" : ("TV Show","Movie"),
"domain" : {"row" : 1 , "column" : 1},
"name" : result["year"][4],
"hoverinfo" : "label+value+name",
"hole" : .4,
"type" : "pie"
}
data5 = {"values" : (result["TV Show"][5],result["Movie"][5]),
"labels" : ("TV Show","Movie"),
"domain" : {"row" : 2 , "column" : 1},
"name" : result["year"][5],
"hoverinfo" : "label+value+name",
"hole" : .4,
"type" : "pie"
}
data = [data0,data1,data2,data3,data4,data5]
layout = go.Layout({
"title" : "2015~2020 type 비율 시각화",
"grid" : {"rows" : 3, "columns" : 2}
})
fig = go.Figure(data=data,layout=layout)
iplot(fig)
TV Show, 영화 발매 증가 추세
vc1 = d1["release_year"].value_counts().reset_index()
vc1.columns = ['release_year','count']
# vc1['release_year'][21] = "under_1990"
# vc1['count'][21] = vc1.iloc[-21:-1,].sum()[1]
vc1 = vc1.sort_values('release_year',ascending=False)
vc1 = vc1.iloc[1:21,] # 1997년(netflix 설립일) ~ 2019년까지
vc2 = d2["release_year"].value_counts().reset_index()
vc2.columns = ['release_year','count']
vc2 = vc2.sort_values('release_year',ascending=False)
vc2 = vc2.iloc[1:21,]
bar1 = go.Bar(x=vc1['release_year'],y=vc1['count'],name="TV Shows",marker=dict(color='cornflowerblue'))
bar2 = go.Bar(x=vc2['release_year'],y=vc2['count'],name="Movies",marker=dict(color='brown'))
data = [bar1,bar2]
fig = make_subplots(rows=2, cols=1, shared_xaxes=False)
fig.add_trace(bar1,row=1,col=1)
fig.add_trace(bar2,row=2,col=1)
fig.update_layout(title_text="TV Show, 영화 발매 증가 추세")
fig.show()
어떤 달에 많이 업로드될까?
tv = d1["date_added"].dt.month.value_counts().reset_index()
tv.columns = ['month','count']
tv['percent'] = tv['count'].apply(lambda x : 100*x/sum(tv['count']))
tv.sort_values('month')
movie = d2["date_added"].dt.month.value_counts().reset_index()
movie.columns = ['month','count']
movie['percent'] = movie['count'].apply(lambda x : 100*x/sum(movie['count']))
movie.sort_values('month')
trace1 = go.Bar(x=tv['month'],y=tv['count'],name='TV Shows',marker=dict(color="cornflowerblue"))
trace2 = go.Bar(x=movie['month'],y=movie['count'],name='Movies',marker=dict(color='brown'))
fig = make_subplots(rows=2, cols=1, shared_xaxes=False)
fig.add_trace(trace1,row=1,col=1)
fig.add_trace(trace2,row=2,col=1)
fig.update_layout(title_text="어떤 달에 많이 업로드될까?")
fig.show()
# + 날짜와 컨텐츠 발매는 상관성이 있는가?
관람등급 등급표
col = 'rating'
tv = d1[col].value_counts().reset_index()
tv.columns=[col,'count']
tv = tv.sort_values(col)
movie = d2[col].value_counts().reset_index()
movie.columns = [col,'count']
movie = movie.sort_values(col)
trace1 = go.Bar(x=tv[col],y=tv['count'],name='TV Shows',marker=dict(color="cornflowerblue"))
trace2 = go.Bar(x=movie[col],y=movie['count'],name='Movies',marker=dict(color='brown'))
data = [trace1,trace2]
layout = go.Layout(title="관람등급", legend=dict(x=0.1,y=1.1,orientation="h"))
fig = go.Figure(data,layout=layout)
fig.show()
영화는 압도적으로 성인물이 많다.(TV-MA : 17세 미만의 어린이나 청소년이 시청하기에 부적절한 프로그램)
TV는 그나마 비율이 적절하다. (TV-14 : 14세 미만의 어린이가 시청하기에 부적절한 프로그램)
장르
from collections import Counter
col = 'listed_in'
# 리스트에 저장
categories1 = ", ".join(d1[col]).split(", ")
for i in range(len(categories1)) :
categories1[i] = categories1[i].strip("TV Shows")
categories2 = ", ".join(d2[col]).split(", ")
# 빈도수 측정을 위해 counter 사용
counter_list1 = Counter(categories1).most_common(50)
counter_list2 = Counter(categories2).most_common(50)
labels1 = [_[0] for _ in counter_list1][::-1]
values1 = [_[1] for _ in counter_list1][::-1]
labels2 = [_[0] for _ in counter_list2][::-1]
values2 = [_[1] for _ in counter_list2][::-1]
trace1 = go.Bar(y=labels1,x=values1,orientation='h',name="TV Shows",marker=dict(color='cornflowerblue'))
trace2 = go.Bar(y=labels2,x=values2,orientation='h',name="Movies",marker=dict(color='brown'))
data = [trace1,trace2]
fig = make_subplots(rows=2, cols=1, shared_xaxes=False)
fig.add_trace(trace1,row=1,col=1)
fig.add_trace(trace2,row=2,col=1)
fig.update_layout(title_text="TV Show, 영화 장르 파악")
fig.show()
넷플릭스에 있는 영화 중 가장 많이 출연한 사람들
def country_trace(country, flag = "movie"):
df["from_us"] = df['country'].fillna("").apply(lambda x : 1 if country.lower() in x.lower() else 0)
small = df[df["from_us"] == 1]
if flag == "movie":
small = small[small["duration"] != ""]
else:
small = small[small["season_count"] != ""]
cast = ", ".join(small['cast'].fillna("")).split(", ")
tags = Counter(cast).most_common(25)
tags = [_ for _ in tags if "" != _[0]]
labels, values = [_[0]+" " for _ in tags], [_[1] for _ in tags]
trace = go.Bar(y=labels[::-1], x=values[::-1], orientation="h", name="", marker=dict(color="olivedrab"))
return trace
from plotly.subplots import make_subplots
traces = []
titles = ["United States", "","India","", "United Kingdom", "Canada","", "Spain","", "Korea"]
for title in titles:
if title != "":
traces.append(country_trace(title))
fig = make_subplots(rows=2, cols=5, subplot_titles=titles)
fig.add_trace(traces[0], 1,1)
fig.add_trace(traces[1], 1,3)
fig.add_trace(traces[2], 1,5)
fig.add_trace(traces[3], 2,1)
fig.add_trace(traces[4], 2,3)
fig.add_trace(traces[5], 2,5)
fig.update_layout(title="많이 출연한 사람",height=1200, showlegend=False)
fig.show() 
넷플릭스에 있는 영화 중 가장 많은 작품이 있는 감독들
def country_trace(country, flag = "movie"):
df["from_us"] = df['country'].fillna("").apply(lambda x : 1 if country.lower() in x.lower() else 0)
small = df[df["from_us"] == 1]
if flag == "movie":
small = small[small["duration"] != ""]
else:
small = small[small["season_count"] != ""]
cast = ", ".join(small['director'].fillna("")).split(", ")
tags = Counter(cast).most_common(25)
tags = [_ for _ in tags if "" != _[0]]
labels, values = [_[0]+" " for _ in tags], [_[1] for _ in tags]
trace = go.Bar(y=labels[::-1], x=values[::-1], orientation="h", name="", marker=dict(color="#66cdaa"))
return trace
from plotly.subplots import make_subplots
traces = []
titles = ["United States", "","India","", "United Kingdom", "Canada","", "Spain","", "Korea"]
for title in titles:
if title != "":
traces.append(country_trace(title))
fig = make_subplots(rows=2, cols=5, subplot_titles=titles)
fig.add_trace(traces[0], 1,1)
fig.add_trace(traces[1], 1,3)
fig.add_trace(traces[2], 1,5)
fig.add_trace(traces[3], 2,1)
fig.add_trace(traces[4], 2,3)
fig.add_trace(traces[5], 2,5)
fig.update_layout(title="이름이 많이 있는 감독",height=1200, showlegend=False)
fig.show() 
더 자세한 내용은 위의 파일로 확인하길!