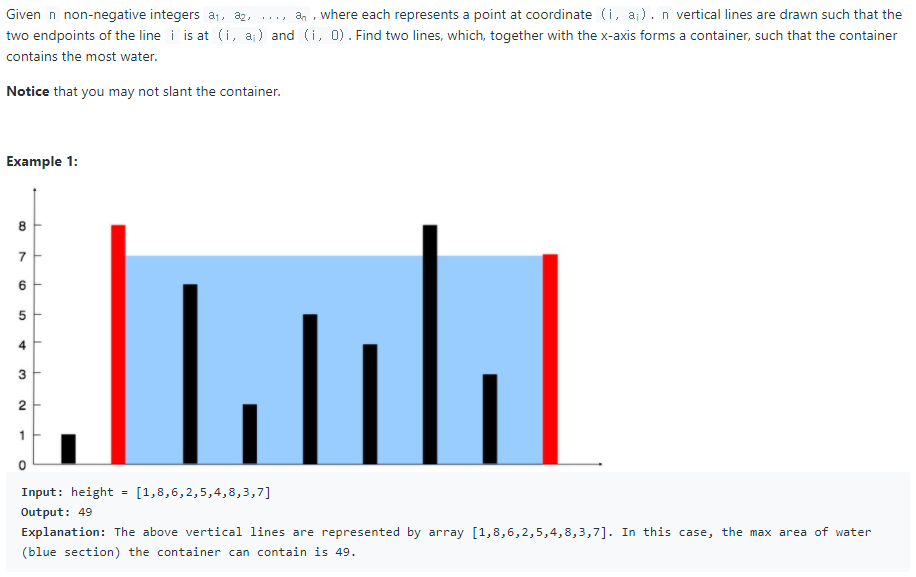
멍청한 나는 for문에 너무 집착한 나머지 1시간 동안 머리를 싸매다가 결국 Discuss를 보고 말았다.
while문이 무한루프를 도는 경우가 싫어서 왠만해선 for문을 써왔었는데 최근 Leetcode 문제들을 풀어보면 while이 그렇게 나쁜것도 아니고, 오히려 굉장히 실용적이라는 느낌도 들었다. 코딩문제를 풀때 while도 많이 애용해 봐야겠다고 생각했다.
class Solution(object):
def maxArea(self, height):
"""
:type height: List[int]
:rtype: int
"""
MAX = 0
x = len(height) - 1
y = 0
while x != y:
if height[x] > height[y]:
area = height[y] * (x - y)
y += 1
else:
area = height[x] * (x - y)
x -= 1
MAX = max(MAX, area)
return MAX
이걸 for문으로 하려면 아주 난리를 쳐야했는데 만들면서도 굉장히 잘못됐다고 느꼈었다ㅋㅋㅋㅋ,,, while... 애용합시다!
for문에 tqdm을 사용하면 이 친구가 언제 다 돌아가는지 확인할 수 있어서 매우 유용하다.
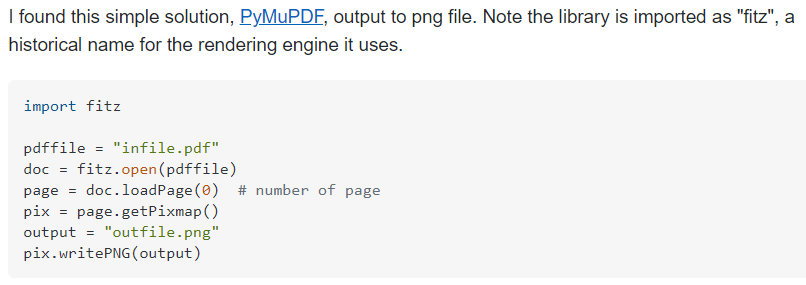
import fitz, os
import pandas as pd
from tqdm import tqdm
path_dir = './'
file_list = os.listdir(path_dir)
# print(file_list) # 현재폴더(./) 안에 있는 파일명들이 리스트화되어 들어가 있다.
for data in tqdm(file_list) :
if '.pdf' in data :
doc = fitz.open('./{}'.format(data))
page = doc.loadPage(0)
pix = page.getPixmap()
output = "../pdf2png/{}.png".format(data.replace('.pdf',''))
pix.writePNG(output)
pdf2image라는 모듈이 있으나 poppler에서 계속 오류가 났던 나는 차선책을 찾게 되었는데, 속도 면에서는 얼마나 차이가 나는지는 모르겠지만 일단 내가 PyMuPDF를 사용해 본 결론으로는 굉장히 느리다ㅋㅋ... 코드도 느릴만하긴하지만.. 그래도 PyMuPDF는 원하는 PDF 페이지만을 선택해서 이미지화 할 수도 있기 때문에 나름 유용하다.
사실 pdf 파일을 이미지로 바꾸기만 하면 되는거 아니겠어? pdf2image모듈을 못 사용하니 꿩 대신 닭을 사용했다.
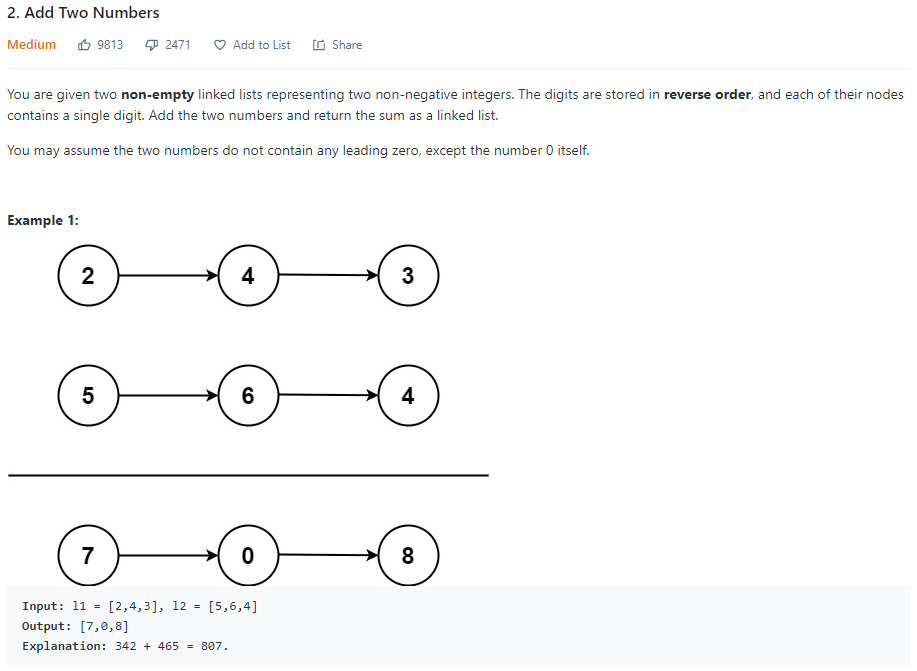
대부분의 사람들이 그렇겠지만, 개인적으로 굉장히 어려워하는게 Node인데 하필이면 2번부터 Node가 나왔다ㅋㅋㅋ 번호 순서대로 풀지 말아야겠다는 생각이 강력하게 들었지만 의외로 또 문제가 쉬워보여서 도전해봤다. 어렵진 않았지만 Node의 개념을 모른다면 절대 못푸는 그런 문제... return값도 node라는게 아주 키포인트임!
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
# 내 풀이
class Solution:
def addTwoNumbers(self, l1, l2):
# print(l1.next.next) # ListNode{val: 3, next: None}
# ListNode는 길이가 없다. 생각해보면 당연하지만 일단 len충인 나는 해봤다 봉변당함ㅋㅋ
# print(len(l1)) # 'ListNode' has no len()
result = 0
i = 0
# 우선 l1과 l2에 있는 데이터로 연산을 완료 (result)
while l1 or l2 :
if l1 != None :
result += l1.val*(10**i)
l1 = l1.next
if l2 != None :
result += l2.val*(10**i)
l2 = l2.next
i += 1
# for문을 돌리기 위해 int인 result를 str로 변경한 모습 (별로 좋다고 생각은 안함)
result = str(result)
# 여기서 진짜 웃긴게 cur을 사용하지 않으면 node가 제대로 이어지지 않는다.
answer = cur = ListNode(0)
# answer = cur = ListNode(0)이 아니고
# answer = ListNode(0)으로 해서 아래 for문을 cur 대신 answer쓰면 제대로 node 형성이 안됨
for i in range(len(result)-1,-1,-1) :
cur.next = ListNode(result[i])
cur = cur.next
# return도 제법 웃겨
return answer.next
속도 암담하다.. 아마 node 만들때 for문 쓴게 크지 않을까 하는 마음근데 같은 코드인데 제출할때마다 바뀌는거 보면 크게 신경 안써도 될것도 같고...
# Discuss에서 추천 수 많았던 코드
class Solution:
def addTwoNumbers(self, l1, l2):
carry = 0
root = n = ListNode(0)
while l1 or l2 or carry:
v1 = v2 = 0
if l1:
v1 = l1.val
l1 = l1.next
if l2:
v2 = l2.val
l2 = l2.next
# print(carry)
# print("v1 :",v1,"v2 :",v2)
carry, val = divmod(v1+v2+carry, 10)
# print(carry,val)
n.next = ListNode(val)
n = n.next
return root.next
위의 코드를 보면 결국에 나랑 비슷한 생각인데 나는 올림에 대해 어떻게 해야할지 모르겠어서 연산을 다 마치고 연산이 끝난 데이터를 역순으로 뽑아 node를 만들었다면, 이 사람은 한번에 node까지 만든것을 볼 수 있다. 올림을 저렇게 할 생각을 못했었는데 진짜 똑똑한것 같다.
속도면에서는 굉장히 앞도적으로 빠르다
이 부분에 대해서는 조금 더 공부한 내용을 추가하도록 하겠다! Node를 아주 부셔버리겠어...
나는 한번도 git을 사용해본적이 없는데, 사실 대학교 3학년때 팀프로젝트에서 git을 잠깐 써봤지만 메인 개발자분이 하신거라 제대로 몰랐는데 현업오니까 git을 한번 각잡고 사용해봐야겠다는 생각이 든다. 진작에 좀 해볼껄... 많이 늙지는 않았는데 조금 늙었다고 인생에 후회가 점점 생겨간다.
위의 코드들은 내가 Transformer 구조를 이해하는데 아주 큰 도움을 준 코드인데, 앞으로 스스로 모델을 구현하는 경우가 생긴다면 위의 코드를 참고해서 짜야겠다. 가독성 좋은 코드가 최고다. 그럴려면 class에 대한 이해, 현업에서 많이 쓰이는 parser에 대한 이해가 필요하다고 정말 많이 느꼈다. 함수화를 생활하하자. class를 잘 이해하자.
3) 범주를 생활화 하고, 개발 문서 작성을 잘 하자 (기록을 생활화하자)
이건 내가 처음 받은 업무를 보면서 정말 많이 느낀점이다. github의 READ_ME.txt에 단순히 프로젝트명만 작성되어 있고 아무것도 모르는 상태에서 폴더들이 나열되었을 때, git도 잘 모르고 애초에 코드를 여러 폴더를 통해 사용해본적이 거의 없는 나에게는 정말 롬곡인 상황이었다. 이 덕에 배운점, 느낀점이 정말 많았는데 그 중에 하나가 범주 생활화 및 개발 문서 작성이다. 범주는 사실 내가 바보라 작성하는 개념이고 개발 문서는 정말 중요하다... 소중하다... 개발 문서가 정확히 뭔지 사실 아직은 잘 모르겠지만 아무튼... 뭔가 기록을 꼼꼼히 남기는 것... 특히 그 코드를 사용하는 예시같은 것.. shell script라면 범주로 예시정도는 꼭 넣어야겠다고 생각했다... 아직 처음이라 느끼는 점일 수도 있겠지만 아무튼 그래...
4) 진짜 현업에서도 다 구글링이다
알고는 있었지만 정말 다 구글링이다. 연차가 쌓일수록 잘하는건 사실이겠지만 아무튼 다 구글링을 하면서 작업한다. 내가 느끼기엔 연차가 쌓이면 작업 환경과 방향성이 익숙한거지 구글링은 어쩔 수 없이 동반되는 것 같다. 나는 실력이 너무 부족하고, 주변엔 너무 잘난 사람들만 가득한 환경에서 아무것도 모르는 상태로 일주일을 지냈기 때문에 정말 극강의 우울감과 자기혐오를 느꼈었는데 사수(사실 정확히는 사수분은 아니시다. 그냥 나를 도와주시는 분... 그저 빛)분이 생기고, 도움을 주시면서 구글링을 하시는 모습, 내가 이미 구글링을 하여 해결되지 못한 부분에 대해, 뚝딱뚝딱 해결하지 못한(당연히 뚝딱뚝딱 해결한 부분이 더 많으시다. 이 분 덕에 나는 코드를 어떻게 보는지 알 수 있었다ㅠㅠ) 부분을 보면서 아~ 사람 사는거 다 똑같구나를 정말 많이 느꼈다.
익숙해지는거지 구글링은 결국 다 똑같았다.
5) 리눅스에 대해 공부하자
나는 취업성공패키지에서 리눅스에 대해 배운적이 있었는데 한달도 안되게 배웠고, 리눅스가 개인적으로 너무 복잡하게 느껴져서 열심히 안했다. 그랬더니 현업 와서 정말 눈물을 줄줄 흘렸다. 열심히 할 것도 없긴 하지만 아무튼 리눅스 환경에 익숙하면 개이득인건 분명했다. 그래도 나는 리눅스에 대해 배운 내용을 정리했으니 망정이지. 나의 리눅스_정리.pdf 파일을 볼 때마다 선생님께 정말 무한한 감사의 마음을 드렸다. 근데 사실 며칠도 안되어서 리눅스가 익숙해지는걸 보면, 그리고 여전히 리눅스가 불편한걸 보면 역시 사람은 적응의 동물인것 같다.
6) 인간은 적응의 동물이다
정말 업무를 하나도 모르겠는데 압박은 자꾸 들어오고 정말 미치는줄 알았다. 끝없는 자기혐오와 스트레스로 정말 너무 힘들었었다. 그렇게 한 3일? 정도 지나니까 멀쩡해졌다. 아마 도움을 주실 분이 생긴 것이 가장 컸겠지만, 도움을 주실 분을 찾아가는 과정도 오롯이 나 혼자 해낸 일이었기 때문에 그 과정은 정말 지옥같았다. 어떻게든 멘탈을 추스리려고 부단히 노력했던 지난 며칠... 일주일도 안되어 멀쩡해지고... 일이 조금은 익숙해지고... 동료가 편해지고... 그게 한달도 안걸리는게 너무 웃겼다. 한달이 뭐야.. 진짜 얼마 안걸렸다. 내 멘탈을 추스리는데 도움을 준 엄마 아빠 주변 지인들에게 다 너무 고맙다. 근데 사실 그때는 정말 너무 힘들어서 별 도움은 안됐다ㅋㅋㅋㅋ... 걍 지나고 보니 고마웠다.. 이정도...? ㅋㅎ 아무튼 난 정말 죽고 싶었고, 일을 하는 것보다 아무것도 하지 않고 가만히 있는게, 일을 이해하지 못해 아무것도 하지 못하는게 얼마나 절망적이고 스트레스 받는 일인지를 잘 경험한 것 같다. 처음엔 회사가 너무 어렵고 무서웠는데 지금은 그때보단 편하고, 사람들이 좋은게 느껴진다.
MobaXterm은 굳이 설치를 하지 않아도 사용할 수 있고 매우 편하고 좋다. 대신 엄청 중요한 부분이 있는데, 리눅스 환경 안에 있는 .py 파일 안에 한글이 있으면 MobaTextEditor로 보면 깨져보이는데, 여기서 코드 수정하고 저장하면 리눅스 안에서도 한글이 깨지니까 한글이 있으면 절대 수정하지 말자... 범주에 한글이 있는 경우에 대해서는 잘 모르겠다. 뭐 일단 만약에 코드를 MobaTextEditor로 수정했는데 실행이 안되면 아마 이 문제일 가능성이 매우 크다. 그거 외에는 윈도우와 리눅스에 존재하는 파일이 이동되기 매우 편리하기 때문에 매우매우 좋다. 다들 알겠지만 나같이 처음 MobaXterm을 사용하는 사람에게 알려줄 팁이 있다면, ctrl+c한 것을 linux환경에서 오른쪽 마우스를 누르고 paste하지 않고 shift+insert를 하면 ctrl+v가 되기 때문에 이걸 활용하는 것을 추천한다.
또 linux 환경에서 -ls를 해서 보이는 파일들에 대해서 더블클릭을 하고 shift+insert를 눌러도 ctrl+v와 같은 효과를 볼 수 있다.
2번째로 설명할 faster R-CNN은 Object Detection에 사용되는 모델로, Object Detection의 시초인 R-CNN을 개선한 모델이다. 따라서 faster R-CNN을 설명하기 앞서 R-CNN을 포함한 Object Detection의 주요한 논문들의 흐름을 설명하겠다.
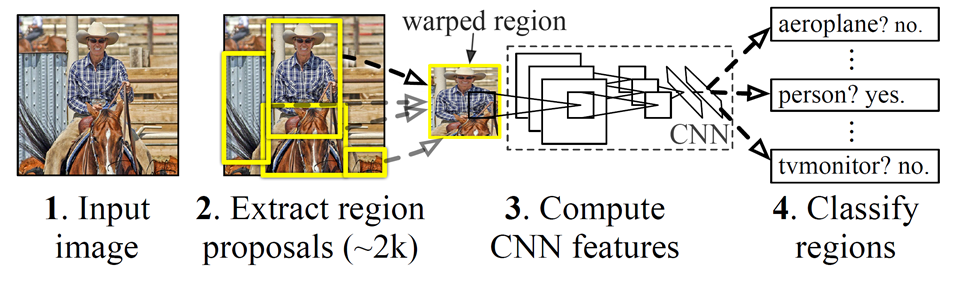
R-CNN은 말 그대로 CNN을 사용하여 Object Detection에서 높은 성능을 보였다. R-CNN의 구조를 그림으로 설명하자면 위의 이미지들로 나타낼 수 있으며, R-CNN의 학습과정을 자세히 설명하자면 다음과 같다.
알고리즘
1. Input으로 들어온 이미지를 Selective Search 알고리즘을 사용하여 후보 영역(Region proposal)을 생성한다. (~2k : 2000여개) 2. 각각의 후보 영역(Region proposal)을 고정된 크기로 Warp하여 CNN input으로 사용한다. +) CNN은 이미 ImageNet을 활용한 pre-trained된 네트워크를 사용 + fine tune(Object Detection용 데이터 셋 사용) 3. CNN을 통해 나온 feature map을 사용하여 벡터를 추출하고 클래스 별로 SVM Classifier 학습, regressor를 통한 Bounding Box Regression을 진행한다. +) SVM Classification을 한 후의 2000여개의 박스들은 어떤 물체일 확률 값을 갖게 되며, 2000여개의 박스를 모두 사용하는 것이 아닌, 가장 확률값이 높은 박스만을 사용하기 위해 IoU(Intercetion over Union)을 적용하여 물체 전체를 대상화할 수 있는 박스 한개를 만들어낸다. 이 과정을 Non-Maximun Supperssion이라고 하며, IoU는 쉽게 말해 두 박스의 교집합을 합집합으로 나눠준 값으로 두 박스가 일치할수록 1에 가까운 값이 나오게 된다. +) Bounding Box Regression을 사용하는 이유는 Selective Search를 통해 찾은 박스 위치가 부정확하기 때문에 모델의 성능을 높이기 위해 박스 위치를 교정하기 위해 사용한다. 박스의 위치를 조절하는 과정은 박스의 좌표 및 너비 높이를 조정하는 함수의 가중치를 곱하며 선형 회귀 학습을 시키기 때문에 Regression이 함께 들어가 있다.
R-CNN의 한계점
합성곱 신경망(conv)의 입력을 위한 고정된 크기를 위해 wraping/crop을 사용해야 하며, 그 과정에서 input 이미지 정보의 손실이 일어난다.
2000여개의 영역마다 CNN을 적용해야 하기 때문에 학습 시간이 오래 걸린다.
학습이 여러 단계(conv-SVM Classifier/Bounding Box Regression)로 이루어지기 때문에 학습 시간이 오래 걸리며, 대용량의 저장 공간을 필요로 한다.
Object Detection 속도가 느리다. (이미지 하나당 CPU에서 54', GPU에서 13')
이와 관련해 더 자세한 설명을 필요로한다면 여기를 참고하길 바란다. 설명이 매우 친절히 되어있고 Object Detection에 대한 논문들이 순차적으로 정리되어 있어 이해하기 편하다.
Fast R-CNN을 설명하기에 앞서 SPPNet에 대해서도 설명하면 좋지만 내가 여기서 말하고 싶은 논문은 Faster R-CNN이기 때문에 SPPNet에 대한 내용은 여기와 여기를 참고하길 바란다.
SPPNet에 대해 간략히 설명하자면 R-CNN의 단점을 보완하고자 만들어진 모델로, R-CNN은 Region proposal을 하나 하나 conv input으로 사용한 반면, SPPNet은 input 이미지 자체를 Convolution Network를 통해 feature map을 만들고 그 feature map으로부터 Region proposal을 만든다는 차이점이 있다. 이 덕에 SPPNet은 학습 속도를 개선할 수 있었다.
Fast R-CNN은 R-CNN과 SPPNet의 단점을 개선하고자 나온 모델이다. R-CNN과 SPPNet의 단점은 학습이 여러 단계로 진행되며, 그로 인해 많은 학습 시간과 GPU 계산 용량이 요구되고 Object Detect에 있어 시간이 오래 걸린다는 것이다.
Fast R-CNN은 CNN 특징 추출 및 Classification, Bounding Box Regression을 모두 하나의 모델에서 학습시키고자 한 모델이다.
알고리즘
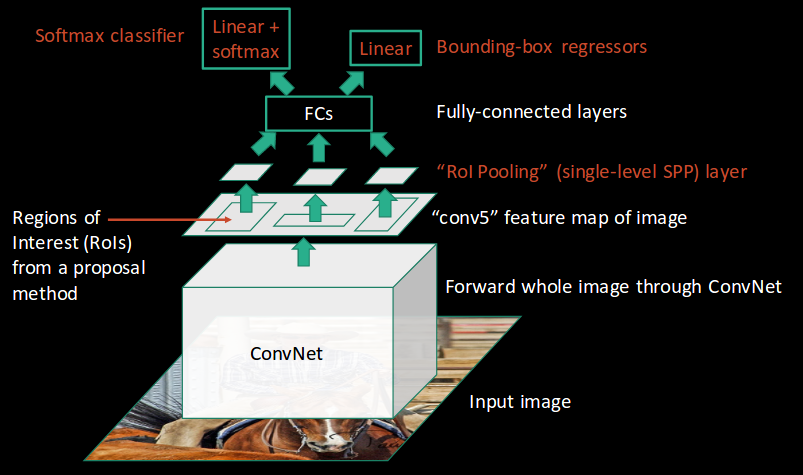
1. 전체 이미지를 미리 학습된 CNN을 통과시켜 feature map을 추출한다. 2. feature map에서 RoI(Region of Interest)들을 찾아준다. +) RoI들은 input 이미지에서 Selective Search를 통해 찾은 것을 feature map에 적용한 것이다. 3. (Selective Search를 통해 찾은) 각각의 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 벡터를 추출한다. 4. feature vector는 fully vector들을 통과한 후, softmax와 bounding box regression의 input으로 들어간다. +) softmax는 SVM을 대신하는 방법으로, 해당 RoI가 어떤 물체인지를 classification한다. +) bounding box regression은 selective search로 찾은 박스의 위치를 조절한다.
Fast R-CNN은 SPPNet처럼 input 이미지를 CNN에 통과한 뒤, 그 feature map을 공유한다. SPPNet은 그 뒤의 과정이 R-CNN과 동일하지만, Fast R-CNN은 RoI Pooling을 사용하여 end-to-end로 학습 가능하게 했다는 것이 가장 큰 특징이다. 이러한 end-to-end 학습이 가능하게 되면서 학습 속도와 정확도를 모두 향상시킬 수 있게 되었다.
RoI Pooling Layer
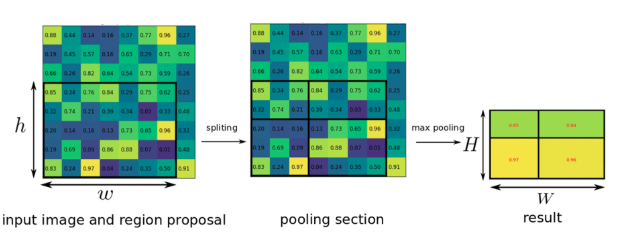
Fast R-CNN의 핵심인 RoI Pooling은 RoI 영역에 해당하는 부분만 max-pooling을 통해 feature map으로부터 고정된 길이의 저차원 벡터로 축소하는 단계를 의미한다. RoI Pooling에 대한 자세한 내용은 아래의 그림을 참고하며 설명하도록 하겠다.
위의 h*w의 영역이 바로 CNN의 output인 feature map에서 RoI 영역에 해당한다. 이 RoI 영역은 CNN을 통과한 feature map에 selective search 기반의 region proposal을 통해 추출된다.
이렇게 정의된 RoI(h*w)를 H*W의 고정된 작은 윈도우 사이즈로 나누고, 나눠진 영역에서 max-pooling을 적용하면 결과값으로 항상 H*W 크기의 feature map이 생성된다. 이런 pooling을 하는 이유는, 다 제각각의 크기인 RoI 영역을 동일한 크기로 맞춰 fc(fullly connect) layer로 넘기기 위함이다.
RoI pooling layer
위의 이미지를 보면 RoI 영역 안의 max-pooling 영역이 모두 동일하지 않음을 알 수 있다. 그럼에도 불구하고 고정된 길이의 벡터로 만드는 것이 RoI pooling layer의 역할이다.
이렇게 RoI pooling layer를 통해 전부 동일한 크기가 된 output들은 fully connected layer를 거쳐 softmax classifcation과 bounding box regression이 수행된다.
이 모든 과정들이 하나의 conv 모델에 의해 동시에 수행되기 때문에 연산속도가 빠르고 정확도가 높아질 수 있었다.
Fast R-CNN은 RoI pooling layer를 사용하여 CNN 특징 추출 및 Classification, Bounding Box Regression을 모두 하나의 모델에서 학습시킬 수 있게 되어 R-CNN과 SPPNet에 비해 빠른 연산 속도와 정확도를 나타낼 수 있었다. 하지만 여전히 Region proposal을 selective search로 수행하여 Region proposal 연산이 느리다는 단점이 있다. (selective search 알고리즘은 GPU를 사용하기 부적합하다.)
Fast R-CNN에 대해 더 자세한 설명이 필요하다면 여기, 여기, 여기를 참고하길 바란다.
Faster R-CNN은 이름과 같이 Fast R-CNN의 개선된 모델로, end-to-end 구조를 위한 전체적인 모델 구조는 Fast R-CNN과 동일하다. 하지만 Fast R-CNN의 단점이었던 Region Proposal을 개선하고자 selective search를 사용하지 않고, Region Proposal Network(RPN)를 통해서 RoI를 계산한다. 이 덕분에 GPU를 통해 RoI 연산이 가능해졌으며 RoI 연산도 학습을 시켜 정확도를 높였다. 따라서 기존의 Selective Search는 2000여개의 RoI를 계산하는 반면 RPN은 더 적은 수의 RoI를 계산하면서도 높은 정확도를 보인다.
Faster R-CNN
위의 이미지를 보면 알 수 있다시피, Faster R-CNN은 RoI를 구하는 방법으로 RPN을 사용하는 것 외에는 Fast R-CNN과 모두 동일하다는 것을 알 수 있다. 그렇다면 RPN의 구조는 정확하게 어떻게 생긴걸까? 이에 대한 내용을 아래에 자세히 다루도록 하겠다.
Region Proposal Network
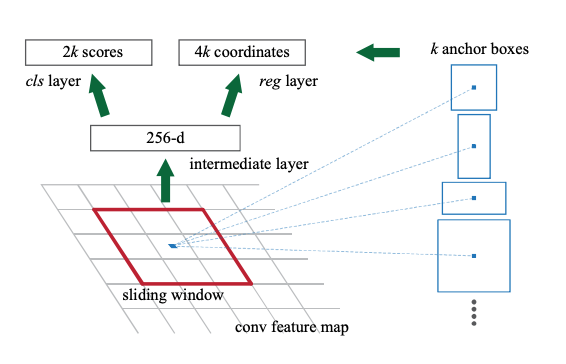
Region Proposal Network(RPN) 구조
참고한 블로그에 의하면 아래의 이미지가 더 직관적으로 RPN의 구조를 이해하기 쉬운 이미지라고 하여 둘 다 갖고 왔다. RPN이 동작하는 원리는 다음과 같다.
알고리즘
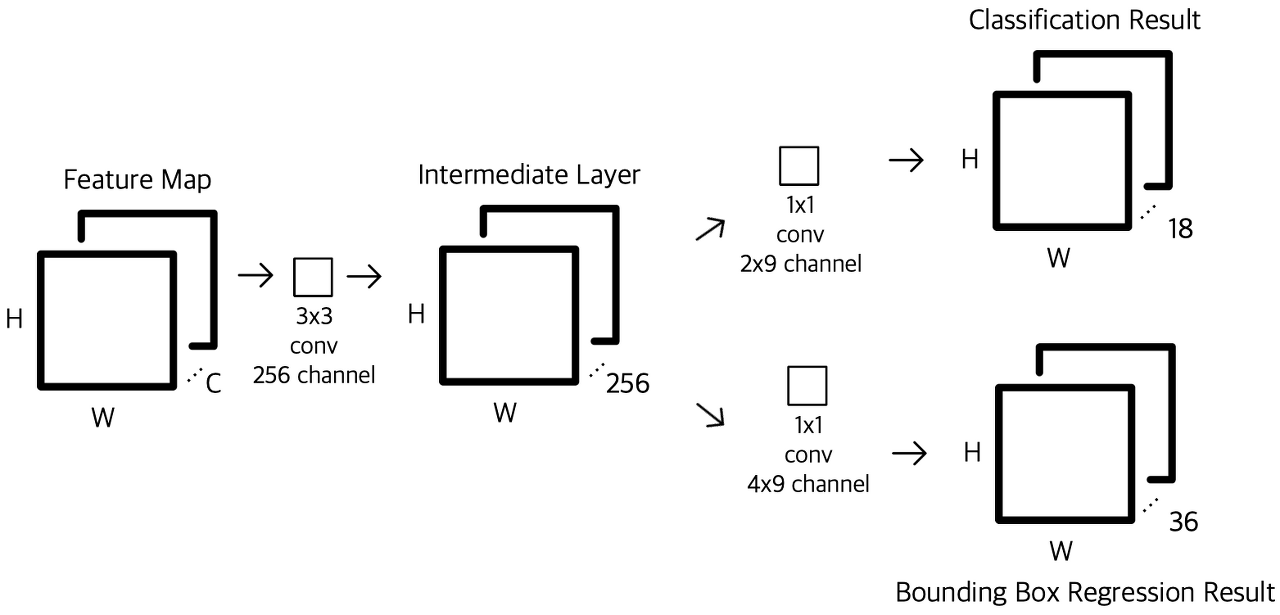
1. CNN을 통해 뽑아낸 feature map을 입력으로 받는다. 이 때, feature map의 크기를 H*W*C(세로*가로*채널수)로 잡는다. 2. feature map에 3x3 convolution을 256 channel (or 512 channel)만큼 수행한다. 이 때, padding을 1로 설정해주어 H x W가 보존되도록 진행하며, intermediate layer 수행 결과 H*W*256 (or 512) 크기의 두 번째 featur map을 얻는다. 3. 2번째 feature map을 입력으로하여 classification(cls layer)과 bounding box regression(reg layer) 예측 값을 계산한다. +) 이 과정은 Fully Connected Layer가 아니라 1 x 1 컨볼루션을 이용하여 계산하는 Fully Convolution Network의 특징을 갖는다. 이는 입력 이미지의 크기에 상관없이 동작할 수 있도록 하기 위함이며 자세한 내용은 Fully Convolution Network을 참고하길 바란다. 4. Classification layer에서는 1 x 1 컨볼루션을 (2(Object인지 아닌지를 나타냄) x 9(앵커(Anchor) 개수)) 채널 수 만큼 수행하며, 그 결과로 H*W*18 크기의 feature map을 얻는다. H*W 상의 하나의 인덱스는 피쳐맵 상의 좌표를 의미하고, 그 아래 18개의 채널은 각각 해당 좌표를 Anchor로 삼아 k개의 앵커 박스들이 object인지 아닌지에 대한 예측 값을 담는다. 즉, 한번의 1x1 컨볼루션으로 H x W 개의 Anchor 좌표들에 대한 예측을 모두 수행할 수 있다. 이제 이 값들을 적절히 reshape 해준 다음 Softmax를 적용하여 해당 Anchor가 Object일 확률 값을 얻는다. +) 여기서 앵커(Anchor)란, 각 슬라이딩 윈도우에서 bounding box의 후보로 사용되는 상자를 의미하며 이동불변성의 특징을 갖는다. 5. Bounding Box Regression 예측 값을 얻기 위한 1 x 1 컨볼루션을 (4 x 9) 채널 수 만큼 수행하며 regression이기 때문에 결과로 얻은 값을 그대로 사용한다. 6. Classification의 값과 Bounding Box Regression의 값들을 통해 RoI를 계산한다. +) 먼저 Classification을 통해서 얻은 물체일 확률 값들을 정렬한 다음, 높은 순으로 K개의 앵커를 추려낸다. 그 후, K개의 앵커들에 각각 Bounding box regression을 적용하고 Non-Maximum-Suppression을 적용하여 RoI을 구한다.
Training
Faster R-CNN은 크게 RPN과 Fast R-CNN으로 구성되어있는 것으로 나눌 수 있고, 결론적으로 RPN이 RoI를 제대로 만들어야 학습이 잘 되기 때문에 4단계에 걸쳐 모델을 번갈아 학습시킨다. 4단계는 다음과 같다.
1. ImageNet pretrained 모델을 불러온 후, Region Proposal을 위해 end-to-end로 RPN을 학습시킨다. 2. 1단계에서 학습시킨 RPN에서 기본 CNN을 제외한 Region Proposal layer만을 가져와 Fast R-CNN을 학습시킨다. +) 첫 feature map을 추출하는 CNN까지 fine tune을 시킨다. 3. 학습시킨 Fast R-CNN과 RPN을 불러와 다른 가중치들(공통된 conv layer 고정)을 고정하고 RPN에 해당하는 layer들만 fine tune 시킨다. +) 이 때부터 RPN과 Fast R-CNN이 conv weight를 공유하게 된다. 4. 공유된 conv layer를 고정시키고 Fast R-CNN에 해당하는 레이어만 fine tune 시킨다.
이러한 과정을 통해 만들어진 Faster R-CNN은 굉장히 빠른 속도와 높은 정확도를 보인다. 여기에 쓰지는 않았지만 Faster R-CNN의 손실함수에 대해 알고 싶다면 여기를 참고하길 바란다.