이제부터 Multi Speaker Tacotron에 대해 설명하도록 하겠다. 필자인 나는 공부하는 입장이니까 내가 이해하는 한으로 최대한 자세하게 설명하도록 하겠다. 하지만 공부하는 입장이기 때문에 틀리는 부분도 있을 거라는걸 명심해 주길 바란다... RNN은 정말 너무 어렵다 ㅠ_ㅠ...

위의 이미지가 구글의 Tactoron 구조이다. 이미지의 출처는 논문이기 때문에 참고하길 바란다. 참고로 논문 처음의 참여자들의 이름에 * 표시가 있는 분들은 타코를 좋아하고 † 표시가 있는 분들은 초밥을 더 좋아한다고 한다. 타코를 좋아하는 사람들이 더 많아서 타코트론이 되었다는 멋진 녀석.... 공대생들의 찐광기를 느낄 수 있는 부분

Encoder

위의 이미지가 타코트론의 Encoder의 세부적인 내용이다. 우선 첫번째로 Character embeddings를 보도록 하겠다.
Character embeddings
사실 Character embeddings에 대해 아주 완벽하게 이해를 하지는 못했다. 내가 책으로 공부하기로는 단어의 one-hot encodding과 가중치의 matmul 연산의 불필요함을 줄이기 위해 한번에 단어 ID로 단어의 분산표현을 만들어내는 것이 Embedding이라고 이해했는데 Tacotron의 논문에서는 입력 인코더는 각 문자가 원-핫 벡터로 표현되고 연속 벡터에 포함되는 문자 시퀀스라고 설명되어 있어서 나의 지식과 혼동되고 있다.(ㅠㅠ) 뭐 아무튼 이래나 저래나 Character embeddings의 핵심은 단어의 분산표현을 나타낸다는 것이고, 결론적으로 이것을 쉽게 말하자면 단어를 숫자 데이터로 변환해준다는 뜻이다.
Pre-net

Pre-net은 별거 없어 보인다. Fully Connected layer - ReLU - Dropout을 2번 반복하는 구조이다. 사실 처음 타코트론을 공부할 때 이 Pre-net은 단순히 오버피팅을 억제하는 정도로만 이해했었다. 근데 논문을 자세히 살펴보니 이 pre-net의 Dropout이 상당히 중요한 역할을 한다.
Pre-net의 Dropout은 크게 2가지 역할을 하는데 우선 첫번째로 일반화를 해준다는 점에서 매우 중요하다. 일반화란, 학습 데이터와 Input data가 달라져도 출력에 대한 성능 차이가 나지 않도록 하는 것을 의미한다. 즉, training data로 나오는 학습 결과만큼 새로운 입력 데이터에 대해서도 좋은 결과가 나올 수 있도록 돕는 역할이라는 것이다. 뭐, 한마디로 그냥 오버피팅을 억제한다고 생각해도 되겠다.
Pre-net의 Dropout은 bottleneck layer, 즉 병목 layer라는 점에서 중요하다. 병목 layer라고 하면 마치 이 계층이 병목현상을 유발한다는 것처럼 읽히지만 사실 이 계층은 병목 현상을 방지한다고 보면 되겠다. Dropout의 구조는 여기의 이미지를 참고하면 되는데, 쉽게 말하자면 모든 신경망을 사용하지 않고 일부만을 사용하여 학습을 진행하고 이 과정을 여러번 반복해 평균을 내 모든 신경망을 사용한것과 비슷한 효과를 내면서 overfitting, 즉 과적합을 방지한다. 이런 과정을 거치면, 여기서 설명하는 것과 같이 학습에 필요한 계산 비용이 크게 줄어들게 된다.


CBHG란 convolutional 1-D filters, bank, highway networks, gated recurrent unit bidirectional의 첫글자를 따서 지어진 이름이다. CBHG는 크게 보자면 CNN과 RNN으로 구성된 신경망으로, 층이 깊어질수록 복잡하고 추상화된 특징을 추출할 수 있는 CNN의 장점과 시계열 데이터의 전체적인 특징을 파악할 수 있는 RNN의 장점을 모두 합친 모델이다.
CNN 모델을 자세히 살펴보자면 Convolution, Max pooling, Convolution 계층을 지나면서 데이터 특징을 잡을 준비를 한다. (혹은 이미 데이터의 특징을 거의 잡아놨다.) 이 과정에서 바로 Highway Layers로 넘어가지 않고 Residual Connection을 하는데, 이는 ResNet을 사용하는 이유와 같은 맥락이라고 보면 된다. 기존의 데이터에 대한 정보를 잃지 않기 위해 우리는 단순 합산을 통해 학습된 데이터와 기존의 데이터의 모든 정보를 갖고 Highway Layers를 통해 특징만을 추출해 낸다.
그 후, Bidirectional RNN으로 데이터를 보내 전체에 대한 흐름의 특징을 파악한다. 여기서 Bidirectional은 양방향이라는 뜻으로, Bidrectional RNN을 사용하는 이유는 시계열 데이터는 순방향 못지 않게 역방향으로도 맥락의 흐름을 유추할 수 있기 때문이다. 따라서 Bidrectional RNN을 사용하여 우리는 과거 시점에서도 미래 시점에 대한 데이터를 받고, 미래 시점에서 과거 시점에 대한 데이터를 받아 맥락의 전체적인 흐름에 대해 파악한다.
Attention
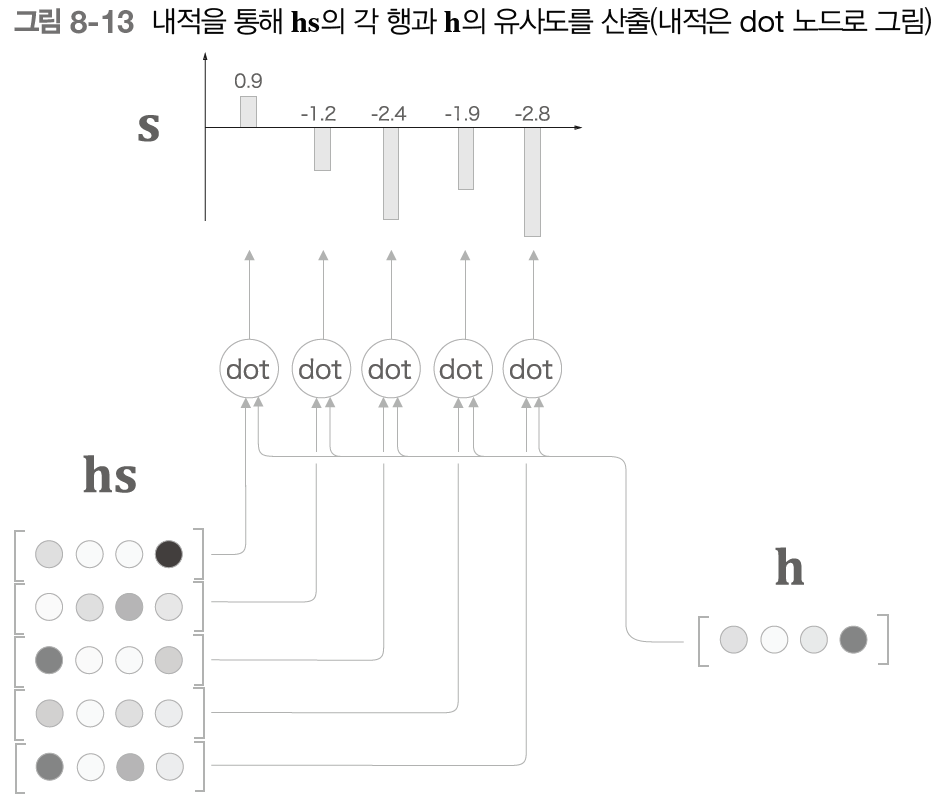
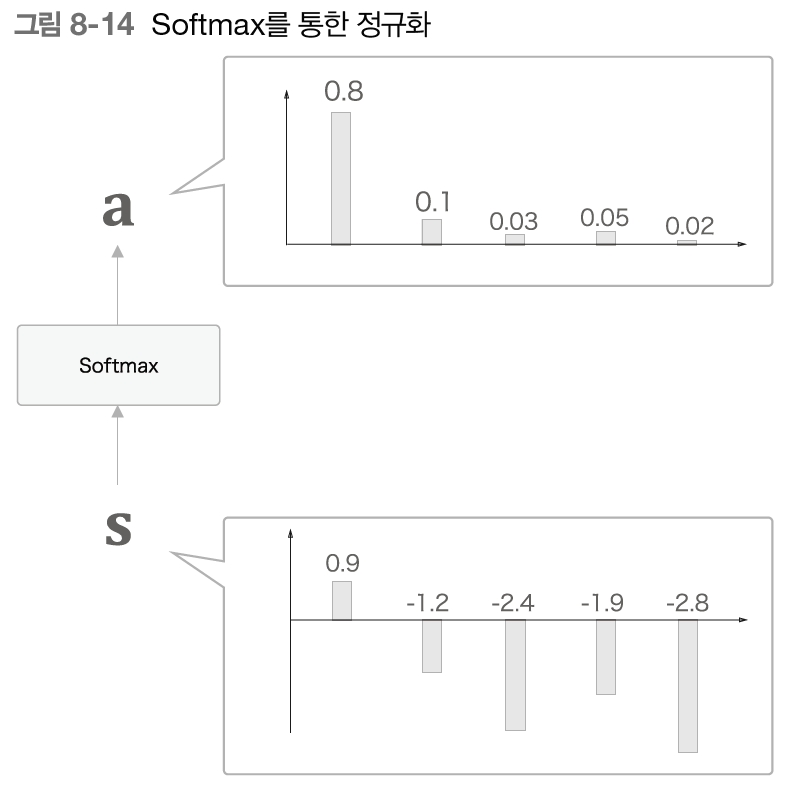
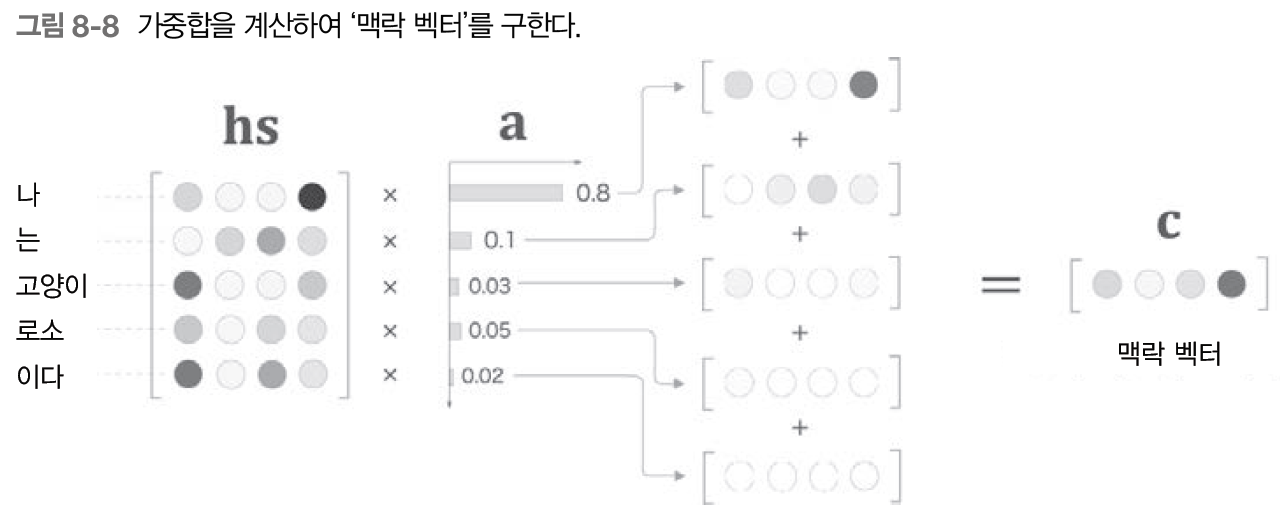
어텐션에 대한 자세한 내용은 링크와 동영상, PPT p.121 부터를 참고하길 바란다. 여기서 간단히 핵심만 다시 언급하자면 Attention이란 시계열 데이터에서 어느 부분에 집중할 것인가에 대해 학습하는 것이며, Attention을 사용하면 '일반화'가 가능하다. 즉, 새로운 데이터가 입력되어도 충분히 좋은 결과를 나타낼 수 있도록 도와준다.
Decoder

Decoder의 아래에 입력 데이터인 <GO> frame은 Decoder, 즉 시계열 데이터의 시작을 알리는 데이터로 큰 의미는 없다. (하지만 반드시 필요) 우리는 이 <GO> frame의 데이터와 Encoder에서 학습된, 문장의 특징을 잘 갖고 있는 단어 임베딩들을 (Encoder CBHG의 맨위쪽, 초록색 Embeddings) Attention 계층에서 학습시키고 (특징을 또한번 잡아내고) 일반 RNN을 사용하여 n개의 스펙토그램으로 출력한다. 이 Spectrogram은 음성 신호로 변환되기 직전의 숫자 데이터로, 발음, 음성에 대한 정보를 담고 있다. 즉, 결론적으로 Encoder에 들어온 단어 데이터들을 Decoder의 Attention과 RNN을 통해 음성 신호로 변환될 수 있는 숫자 데이터로 바꿔준다고 이해하면 되겠다. 이에 대한 자세한 설명은 PPT p.103부터 참고하길 바란다.
이렇게 스펙트로그램 데이터를 만들면 CBHG를 통해 또한번 특징을 잡은 후 하나의 시계열 데이터로 출력한다. 이 데이터를 스펙트로그램을 음성 데이터로 변환해주는 Griffin-Lim을 통해 음성 데이터로 출력한다.
위의 구조가 Tacotron의 구조이다. 정말... 정말 복잡하다... 사실 이해하고 보면 그렇게 어렵지는 않은데 다양한 개념들이 섞여서 헷갈린다. 하지만 그냥 엄청엄청 쉽게 이해를 하자면 악착같이 시계열 데이터들에 대해 특징을 잡아내고 일반화를 하기 위해 노력하는 짓을 n번 반복하여 결과물을 만들어내는 악착같은 모델이라고 이해하면 되겠다.
Multi Spekaer Tacotron - Speaker Embedding
여기서 끝이 아니다. 우리는 Multi Speaker Tacotron을 사용하기 때문에 Multi Speaker에 대해서도 이해해야한다. 사실 이 부분에 대해서는 완벽하게 이해를 아직 하지 못했기 때문에 대략적으로 설명하고 넘어가도록 하겠다. (큐ㅠ)
Multi Speaker Tacotron은 Baidu에서 발표한 Deep Voice2에 기재된 내용으로, 쉽게 말하자면 여러명의 발화자에 대해 적은 메모리 사용량으로도 효과적으로 학습할 수 있다는 내용이다. 이에 대한 자세한 설명은 PPT의 p.159부터 참고하길 바란다.
간략하게 설명하자면 N명의 발화자(Speaker) 정보를 가진 Speaker Embedding을 만들어 Encoder CBHG의 CNN부분(정확히는 residual connection)과 RNN부분에 삽입한다. 그리고 Decoder Pre-net과 RNN에 삽입하여 적은 메모리 사용량으로 효과적으로 여러명의 음성 특징을 학습할 수 있게 한다.
Multi Speaker Tacotron을 사용하면 결론적으로 잘 학습된 Attention이 잘 학습되지 않은 Attention의 학습에 도움을 주어 적은 양의 데이터로도 충분히 좋은 효과를 볼 수 있다. 필자가 이해하기로는 전이학습과는 다르지만, 결론적으로 학습이 잘된 Attention이 학습이 안된 Attention의 학습에 도움을 준다는 것이 전이학습과 비슷한 '결'이지 않을까 싶다. 이 부분에 대해서는 아직 정확하게 알지 못하기 때문에 추가적으로 기재하도록 하겠다.
아무튼 Speaker Embedding을 사용하여 여러 화자에 대한 Attention을 학습하면 내가 원하는 특징(예를 들자면 발화 속도, 억양과 같은)만을 추출하여 다른 화자에게 대입할 수 있다. 이 부분에 대해서도 PPT p.185부터 참고하길 바란다.
설명이 부족하거나 이해가 가지 않는 부분에 대해서는 우리가 참고한 github의 주인인 carpedm20님의 PPT와 동영상을 참고하길 바란다. (이미 너무 남발하긴 했지만ㅋㅋㅋㅋ) 큰 틀에서 이해하기엔 동영상이 최고다... 흑흑 이제 드디어 끝났다.. 타코트론아 많은 깨달음을 줘서 고맙지만,,, 참,, 힘들었다,,,,★
'인공지능 > 프로젝트' 카테고리의 다른 글
| DJ You Prjoect) Multi Speaker Tacotron 을 활용하여 선생님 목소리로 TTS 만들기 - Preview (0) | 2020.10.10 |
|---|---|
| R 개인프로젝트 - 코로나와 마스크의 상관성 (0) | 2020.07.14 |