|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
# 의사결정트리 알고리즘을 이용하여 은행 대출 채무 이행/불이행 여부 예측
credit = read.csv('c:/data/credit.csv',header=T,stringsAsFactors = T)
# 데이터 형태 확인
str(credit) # 수치형, 명목형 섞여있음
# 데이터 분류 (caret 사용)
# install.packages('caret')
library(caret)
set.seed(5)
intrain = createDataPartition(credit$default,p=0.9,list=F)
# train(90%) / test(10%)
credit_train = credit[intrain,]
credit_test = credit[-intrain,]
nrow(credit_train) # 900
nrow(credit_test) # 100
# 의사결정트리 모델 생성
library(C50)
credit_model = C5.0(default~.,data=credit_train,trials=24) # 24 : 0.87
credit_result = predict(credit_model,credit_test[,-17])
# 이원 교차표로 결과 확인
library(gmodels)
x = CrossTable(credit_test[,17],credit_result)
# install.packages('rpart')
# install.packages('rpart.plot')
library(rpart)
library(rpart.plot)
# 의사결정트리 시각화
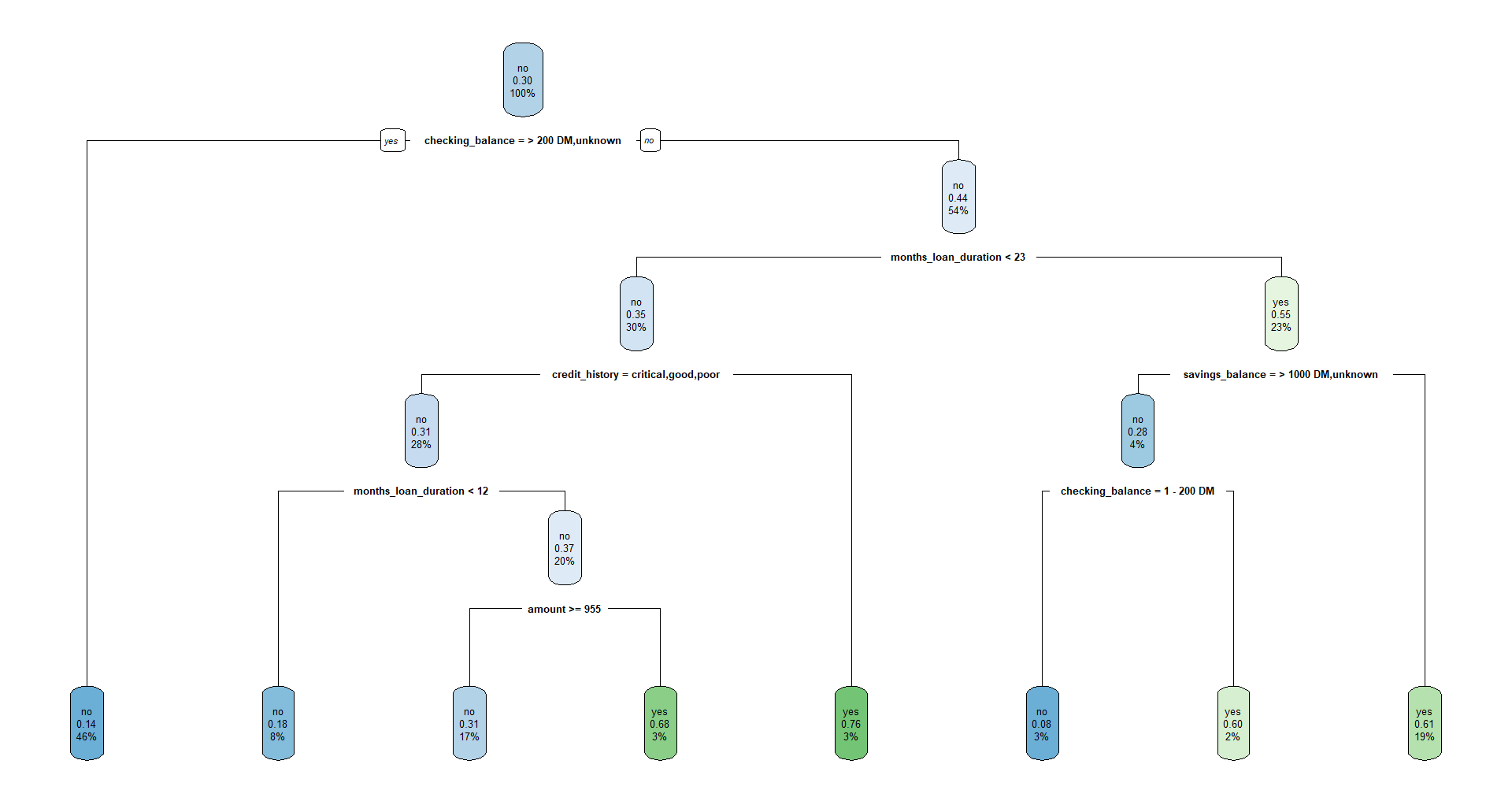
rpartmod = rpart(default~., data=credit_train, method='class')
rpart.plot(rpartmod)
x$prop.tbl[1]+x$prop.tbl[4] # 0.87
# 어떤 trial 값이 가장 정답률이 높은가?
temp = c()
num = c()
for (i in 1:100) {
num = append(num,i)
credit_model = C5.0(default~.,data=credit_train,trials=i)
credit_result = predict(credit_model,credit_test[,-17])
x = CrossTable(credit_test[,17],credit_result)
g3 = x$prop.tbl[1]+x$prop.tbl[4]
temp = append(temp,g3)
}
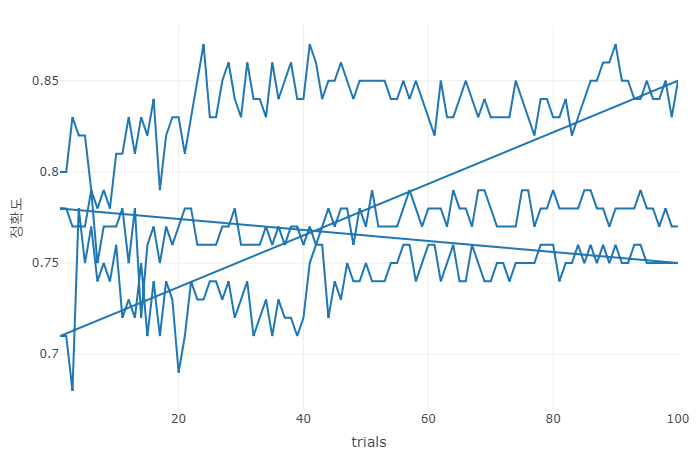
result = data.frame("trials"=num,"정확도"=temp)
library(plotly)
plot_ly(x=~result[,"trials"],y=~result[,"정확도"],type='scatter',mode='lines') %>%
layout(xaxis=list(title="trials"),yaxis=list(title="정확도"))
|
cs |
+) 호기심에 미친 나! 어떤 seed값과 trial값이 가장 좋은 결과를 만들어낼까? 2중 for 문 돌려보자!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
# 의사결정트리 알고리즘을 이용하여 은행 대출 채무 이행/불이행 여부 예측
credit = read.csv('c:/data/credit.csv',header=T,stringsAsFactors = T)
# 데이터 형태 확인
str(credit) # 수치형, 명목형 섞여있음
library(caret)
library(C50)
library(gmodels)
# 어떤 trial값과 seed값이 가장 정답률이 높은가?
temp = c()
num = c()
seed_num = c()
for (j in 5:6) {
for (i in 1:100) {
set.seed(j)
intrain = createDataPartition(credit$default,p=0.9,list=F)
# train(90%) / test(10%)
credit_train = credit[intrain,]
credit_test = credit[-intrain,]
num = append(num,i)
credit_model = C5.0(default~.,data=credit_train,trials=i)
credit_result = predict(credit_model,credit_test[,-17])
x = CrossTable(credit_test[,17],credit_result)
g3 = x$prop.tbl[1]+x$prop.tbl[4]
temp = append(temp,g3)
seed_num = append(seed_num,j)
}
}
# seed값과 trials에 따른 정확도를 보여주는 result라는 테이블을 만들어다.
result = data.frame("trials"=num,"seed"=seed_num,"정확도"=temp)
result
# 제일 좋은 조건 한번에 보기
result[result$정확도==max(result['정확도']),]
# 근데 lines 그래프로는 seed값을 어떻게 보여줘야 될 지 모르겠네 ^^
# 아는 분은 댓글로 좀 알려주세요 ^0^
library(plotly)
plot_ly(x=~result[,"trials"],y=~result[,"정확도"],type='scatter',mode='lines') %>%
layout(xaxis=list(title="trials"),yaxis=list(title="정확도"))
|
cs |
'인공지능 > 실습예제' 카테고리의 다른 글
| (R) 회귀분석 활용하기 (0) | 2020.06.26 |
|---|---|
| (R) 규칙기반알고리즘 활용하기 - 버섯 분류 (0) | 2020.06.26 |
| (R) 의사결정트리 활용하기 1 - 화장품을 구입할 고객은? (0) | 2020.06.25 |
| (R) 나이브베이즈알고리즘 활용하기 3 - 독감 환자입니까? (0) | 2020.06.25 |
| (R) 나이브베이즈알고리즘 활용하기 2 - 영화 장르 예측 (0) | 2020.06.25 |