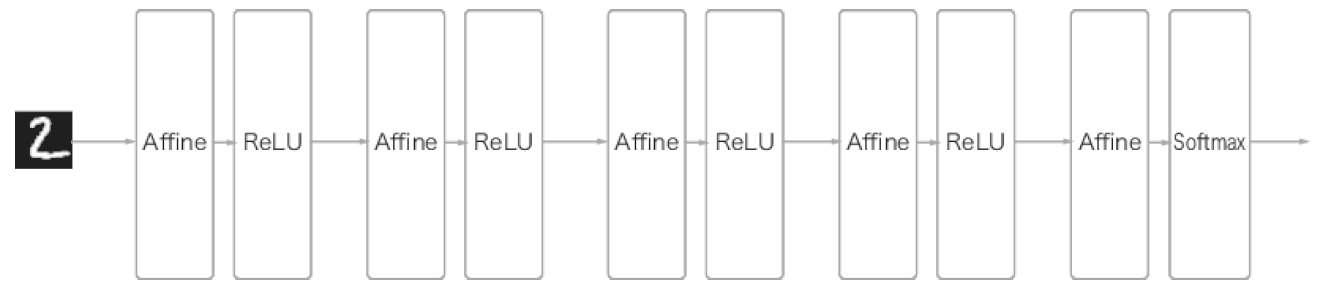
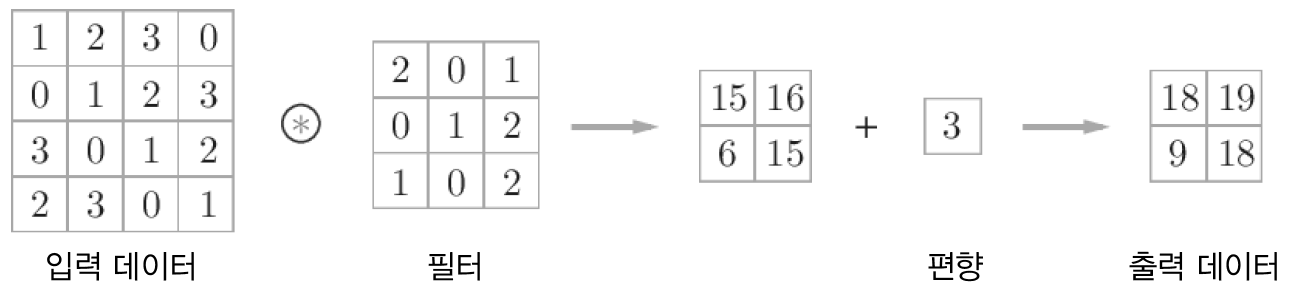
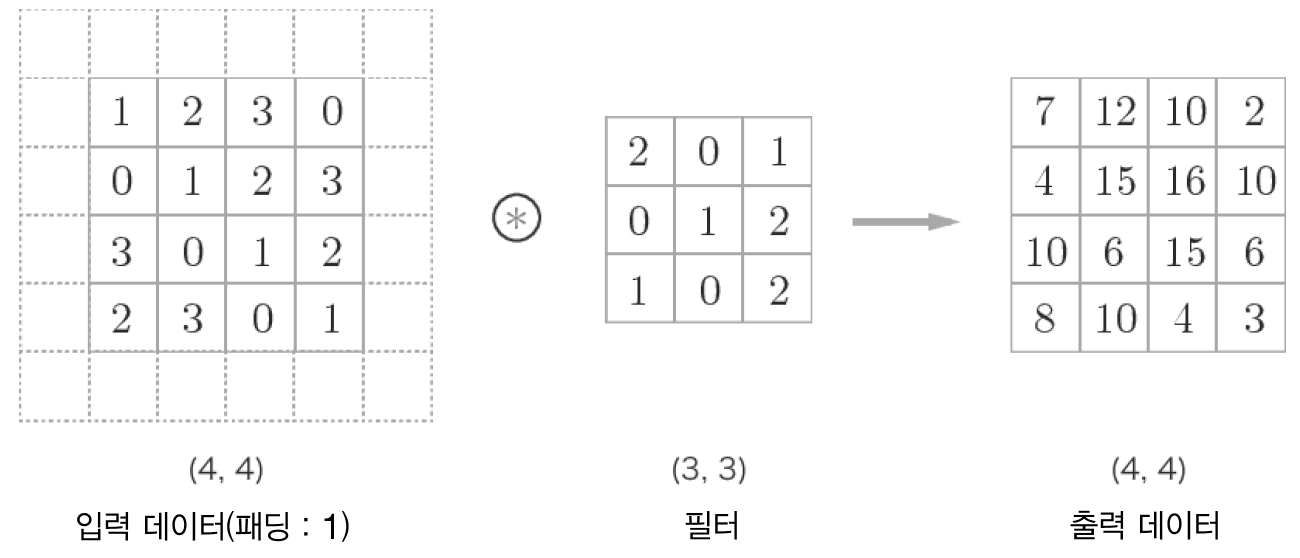
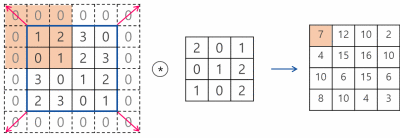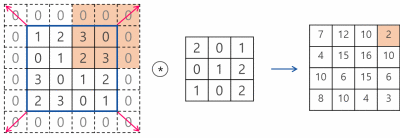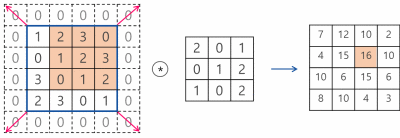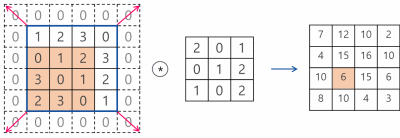
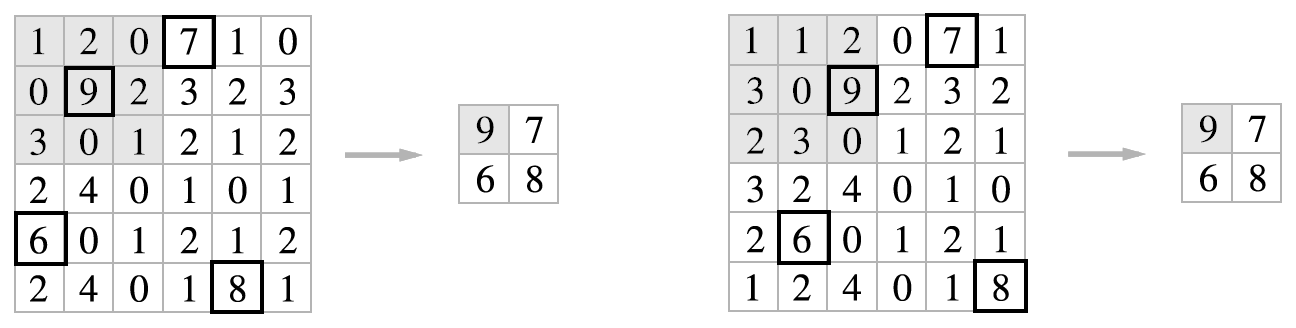
Pooling 계층에서의 im2col
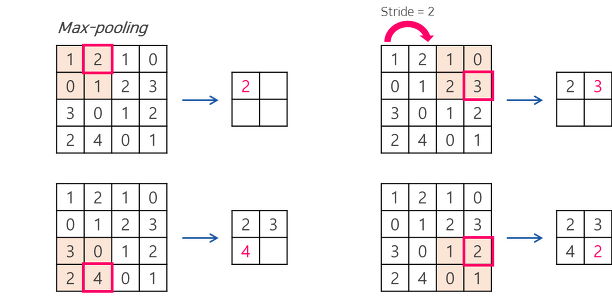
풀링 계층도 앞서 설명한 합성곱 계층과 마찬가지로 im2col을 사용해 입력 데이터를 전개한다.
이번에는 코드와 함께 설명하도록 하겠다.
우선, pooling 계층을 구현하기 위해서는 im2col 함수가 필요하다.
import numpy as np
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""
다수의 이미지를 입력받아 2차원 배열로 변환한다(평탄화).
Parameters
----------
input_data : 4차원 배열 형태의 입력 데이터(이미지 수, 채널 수, 높이, 너비)
filter_h : 필터의 높이
filter_w : 필터의 너비
stride : 스트라이드
pad : 패딩
Returns
-------
col : 2차원 배열
"""
N, C, H, W = input_data.shape
out_h = (H + 2 * pad - filter_h) // stride + 1
out_w = (W + 2 * pad - filter_w) // stride + 1
img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)
return col
이후 풀링 계층의 진행 순서는 다음과 같다.
(선택사항). 입력 데이터가 만약 4차원이 아니라면 im2col의 입력값으로 바꾸기 위해서 4차원으로 변경한다.
1. im2col로 4차원 데이터를 행렬로 (2차원) 변경한다.
2. np.max를 사용하여 각 행에서의 최대값을 취한다.
3. 최대값만 취한 데이터를 다시 입력 데이터의 shape으로 변경한다.
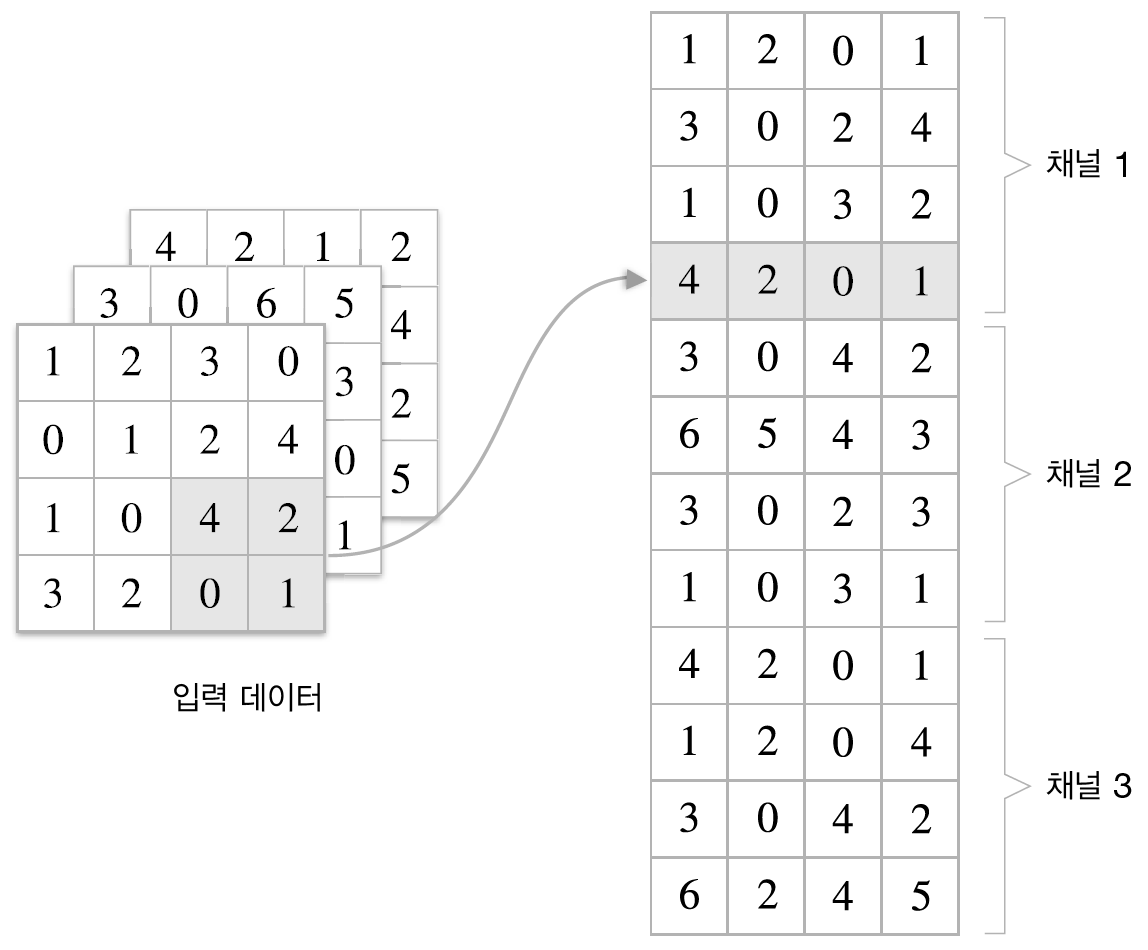
그럼 다음의 그림과 같은 예제를 코드로 진행하도록 하겠다.
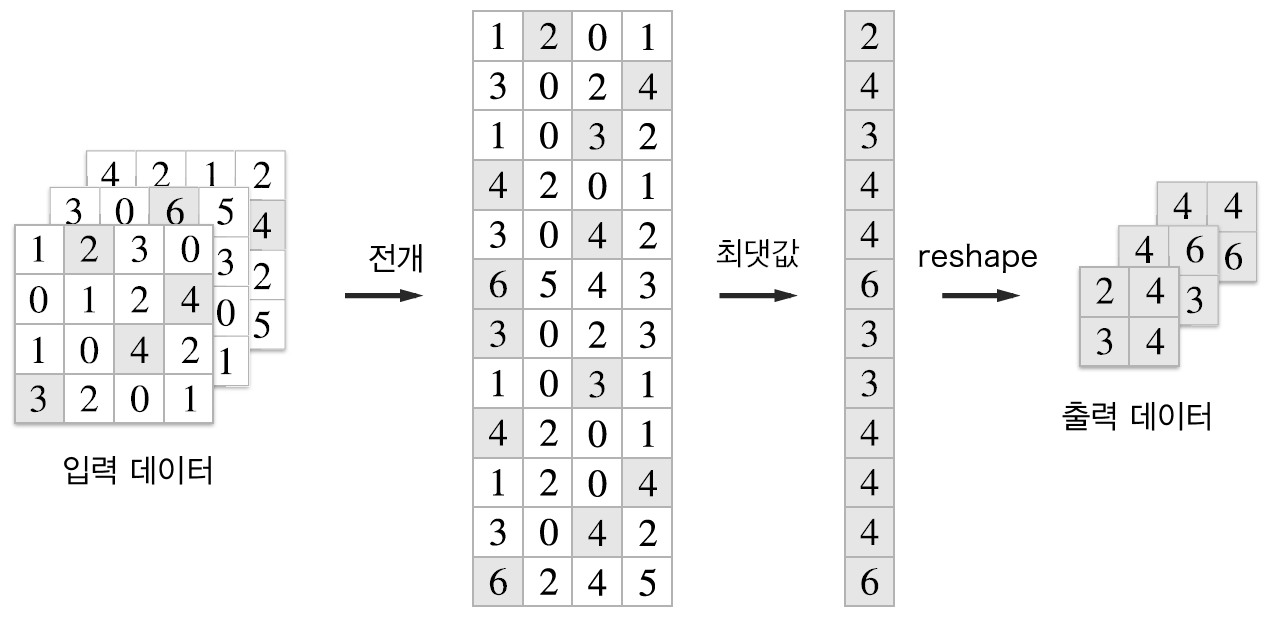
1. im2col로 4차원 데이터를 행렬로 (2차원) 변경한다.
# 예제 데이터 생성
x = np.array([[[[1,2,3,0],[0,1,2,4],[1,0,4,2],[3,2,0,1]],
[[3,0,6,5],[4,2,4,3],[3,0,1,0],[2,3,3,1]],
[[4,2,1,2],[0,1,0,4],[3,0,6,2],[4,2,4,5]]]])
x.ndim # 4차원
x.shape # (1,3,4,4)
# 1번 : im2col로 4차원 데이터를 행렬로 (2차원) 변경한다.
step_1 = im2col(x,2,2,2,0) # 입력 데이터(x)를 필터크기(2x2)와 stride(2), padding(0)으로 평탄화함
step_1
'''
array([[1., 2., 0., 1., 3., 0., 4., 2., 4., 2., 0., 1.],
[3., 0., 2., 4., 6., 5., 4., 3., 1., 2., 0., 4.],
[1., 0., 3., 2., 3., 0., 2., 3., 3., 0., 4., 2.],
[4., 2., 0., 1., 1., 0., 3., 1., 6., 2., 4., 5.]])
'''
step_1.shape # (4,12)
# 1번_2 : 평탄화 된(im2col 사용) 행렬을 그림과 같은 2차원으로 변경한다.
step1 = step_1.reshape(-1,4)
'''
array([[1., 2., 0., 1.],
[3., 0., 4., 2.],
[4., 2., 0., 1.],
[3., 0., 2., 4.],
[6., 5., 4., 3.],
[1., 2., 0., 4.],
[1., 0., 3., 2.],
[3., 0., 2., 3.],
[3., 0., 4., 2.],
[4., 2., 0., 1.],
[1., 0., 3., 1.],
[6., 2., 4., 5.]])
'''
step1.shape # (12,4)
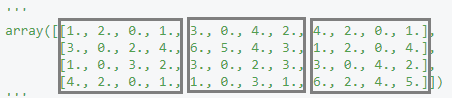
im2col 함수를 사용한 변수의 결과는 위의 이미지로, 그림의 전개에 해당하는 부분처럼 이해하고 싶으면 사각형으로 봐야 한다. 실제 코드로 구현할 때는 채널1, 채널2, 채널3에 해당하는 수들을 전개하는 것이 아니라 채널1과 채널2, 채널3에 같은 위치(행)에 존재하는 것들을 일렬로 전개한다. 이때문에 2번째로 reshape을 해 준 array는 그림에서의 전개 후 이미지와는 약간 다르다.
2. np.max를 사용하여 각 행에서의 최대값을 취한다.
# 2. np.max를 사용하여 각 행에서의 최대값을 취한다.
step2 = np.max(step1,axis=1)
step2 # array([2., 4., 4., 4., 6., 4., 3., 3., 4., 4., 3., 6.])
여기서 np.max(,axis=1)을 사용하는 이유는 여기를 참고하길 바란다.
step2의 결과물도 그림의 최댓값 이후의 전개물과 동일하게 이해하려면 다음의 그림을 참고하면 된다.

3. 최대값만 취한 데이터를 다시 입력 데이터의 shape으로 변경한다.
# 3. 최대값만 취한 데이터를 다시 입력 데이터의 shape으로 변경한다.
step3 = step2.reshape(1,2,2,-1) # step2의 결과를 배치사이즈(1), 출력데이터크기(2x2), 채널(-1)로 reshape한다.
step3.transpose(0,3,1,2) #(1,2,2,3) : step3의 결과(N,H,W,C)를 (N,C,H,W)로 순서를 바꿔준다.
'''
array([[[[2., 4.],
[3., 4.]],
[[4., 6.],
[3., 3.]],
[[4., 4.],
[4., 6.]]]])
'''
그럼 그림과 일치하게, 우리가 원하는 풀링 계층의 출력 데이터를 만들 수 있다.
위의 흐름을 따라서 Pooling class를 만들면 다음과 같다.
class Pooling :
def __init__(self,pool_h,pool_w,stride=1,pad=0) :
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
def forward(self,x) :
N, C, H, W = x.shape
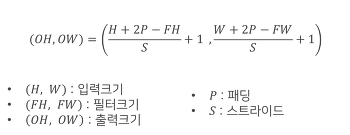
out_h = int(1+(H - self.pool_h)/self.stride) # 공식 사용, padding은 Pooling에서 사용하지 않으므로 애초에 수식에서 뺌
out_w = int(1+(W - self.pool_w)/self.stride) # 공식 사용, padding은 Pooling에서 사용하지 않으므로 애초에 수식에서 뺌
col = im2col(x,self.pool_h,self.pool_w,self.stride,self.pad) # im2col로 평탄화해줌
col = col.reshape(-1,self.pool_h*self.pool_w) # np.max를 수행하기 위해 reshape 해줌
out = np.max(col,axis=1) # np.max 수행
out = out.reshape(N,out_h,out_w,C).transpose(0,3,1,2) # (N,H,W,C)의 모양을 (N,C,H,W)로 바꿔줌
return out
pool = Pooling(2,2,2) # pooling size(2x2), stride(2)의 풀링 계층 구현
pool.forward(x)
im2col을 사용하는 이유는 행렬 연산에 최적화 된 컴퓨터가 연산을 더욱 빠르게 하도록,
또 딥러닝에 많이 사용되는 GPU의 병렬 연산을 효율적으로 사용하기 위해서였다.
그런데 im2col과 완전연결신경망인 MLNN(Multi-Layer Neural Network)에서의 flatten은 정확히 무슨 차이가 있는걸까?
MLNN은 가중치를 갱신하면서 최적의 가중치를 찾아가며 신경망을 학습하고 이 때 입력 데이터의 모든 데이터가 사용된다. 따라서 초반에 2차원, 혹은 3차원의 입력 데이터를 flatten함으로써 모든 데이터가 신경망 전체를 아우르는 가중치의 학습 및 갱신에 사용된다고 볼 수 있다.
하지만 im2col은 결국 Conv층과 Pooling층의 연산 속도를 빠르게 하기 위해 사용하는 함수이고, 실질적으로 im2col을 사용한 후의 데이터는 Conv층의 합성곱을 수행하고 Pooling층의 기능을 한다. 또한 Conv층과 Pooling층은 각각의 filter를 갖고 있기 때문에 입력 데이터는 각각의 filter에 대해서만 영향을 받는다. 따라서 im2col과 flatten은 데이터를 압축시킨다는 역할은 같으나, im2col은 각 계층의 연산을 빠르게 해준다는 장점 이외의 데이터 변형, 또는 연산 변형은 전혀 없다. (정확하다고 볼 수는 없겠지만 느낌적으로 이 둘의 차이를 이해하길 바란다. 개인적인 해석으로 틀렸다면 꼭 알려주시길 바랍니다 크흡,,)
결론적으로 CNN은 MLNN과 달리 데이터를 flatten시키지 않아 데이터 형상을 유지하면서 Conv계층, Pooling계층의 연산(내부적으로는 im2col을 사용하여 연산속도를 빠르게 함)을 사용하며 이미지 자체를 학습할 수 있다.
'인공지능 > 인공지능 이론' 카테고리의 다른 글
| 26. 자연어 처리 2) 단어의 분산 표현 얻는 방법 - 추론 기반 기법(word2vec) (0) | 2020.10.04 |
|---|---|
| 25. 자연어 처리 1) 단어의 의미 이해시키기(단어의 분산 표현 얻는 방법) (0) | 2020.09.28 |
| 23. im2col 이해하기 - 합성곱 계층(Convolution Layer) (4) | 2020.08.12 |
| 22. 딥러닝, 전이학습, 강화학습 (0) | 2020.08.10 |
| 21. CNN (합성곱 신경망) (2) | 2020.08.07 |